Method and device for storing and inquiring mass semantic data
A semantic and data technology, applied in the field of using cloud computing technology to store and query massive semantic data. requirements and other issues to achieve good scalability, high efficiency, and fast query speed.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

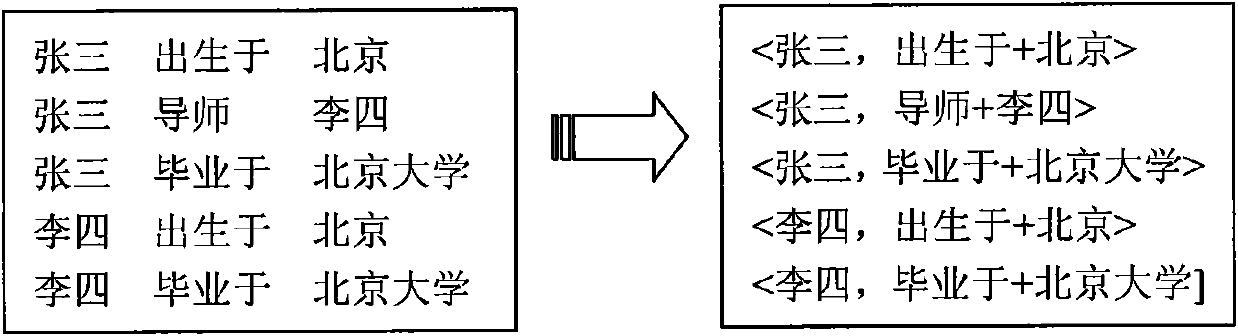
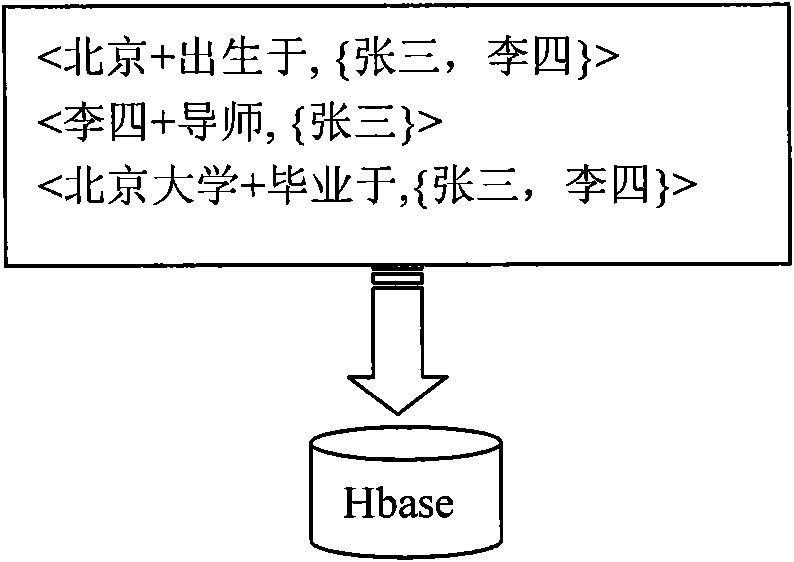
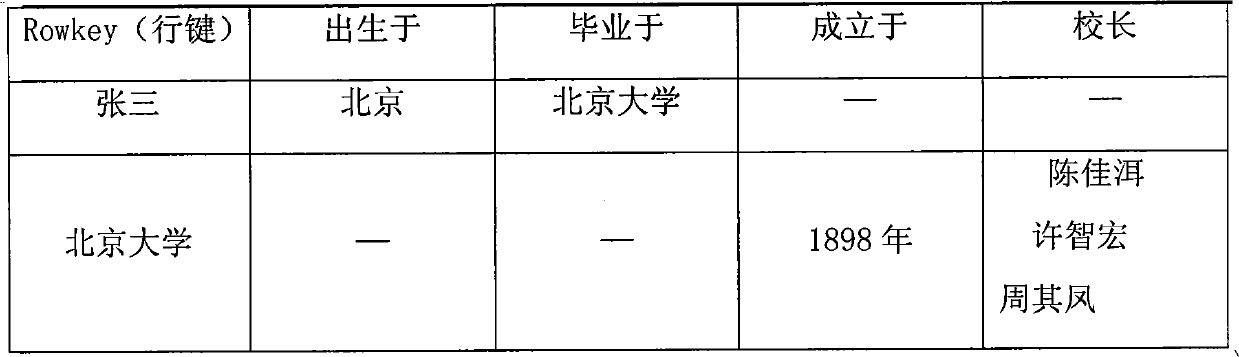
Examples
Embodiment Construction
[0049] The example of the present invention is based on the Hadoop cloud computing platform, and a cluster with multiple computer nodes is built on this platform. The cluster includes a master control node and several slave nodes. The role of the master node is to control the storage details of the slave nodes, schedule storage units, allocate computing tasks, monitor node status, and balance cluster load. The role of the slave node is to store specific data, complete the calculation tasks assigned by the master node, and report storage information, calculation information, and its current state to the master node. On this cluster, a distributed database Hbase is established, so that each node of the cluster can provide storage functions. When storing massive amounts of semantic data, there is no need to worry about capacity. And when the data continues to increase, you only need to increase the number of slave nodes in the cluster, which has very good scalability. The MapRedu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com