

Semi-supervised classification method of unbalance data
A classification method and semi-supervised technology, applied in the field of data processing, can solve the problems of low classification accuracy of minority classes, wrong classification into majority classes, over-learning, etc., so as to avoid over-learning phenomenon, improve generalization ability, and improve classification performance. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

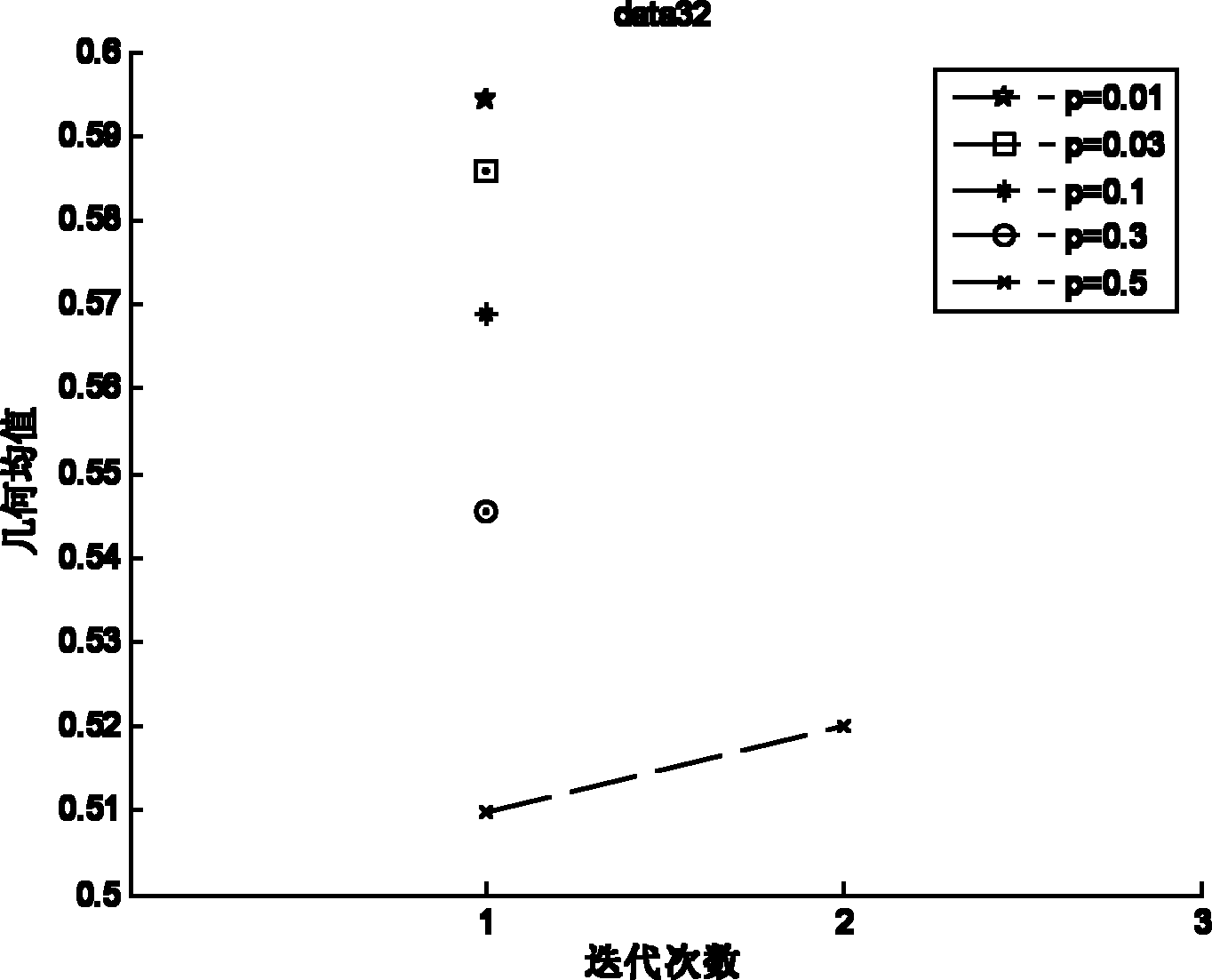
Examples
Embodiment Construction
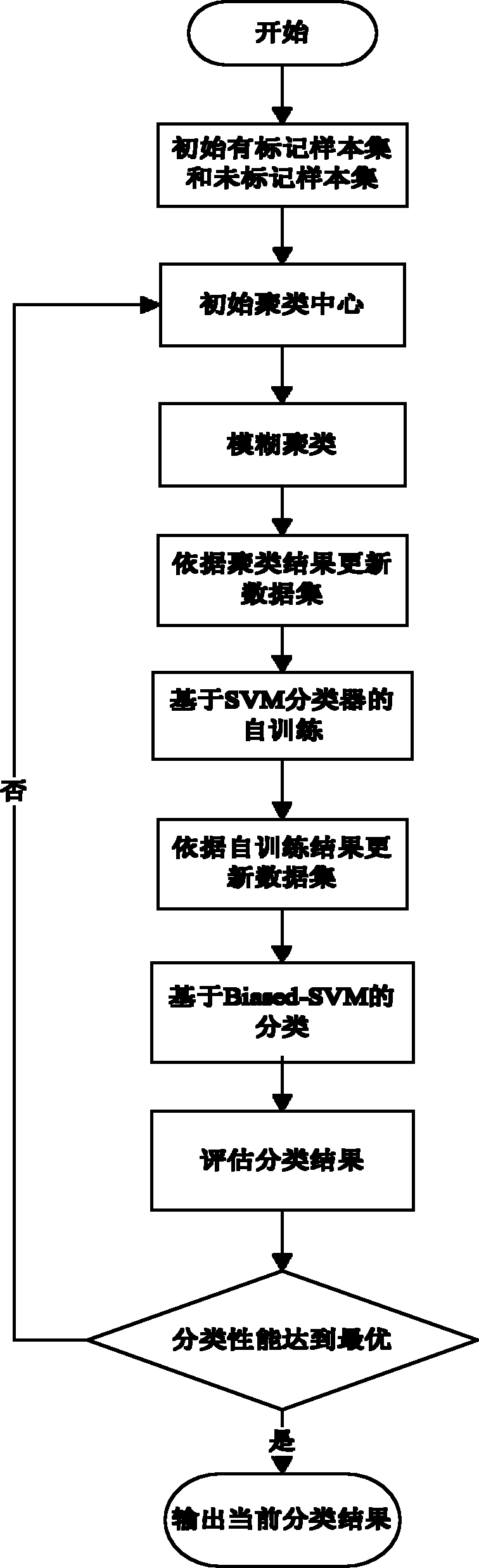
[0026] refer to figure 1 , the specific implementation steps of the present invention are as follows:
[0027] Step 1. Select an initial labeled sample set and an initial unlabeled sample set.
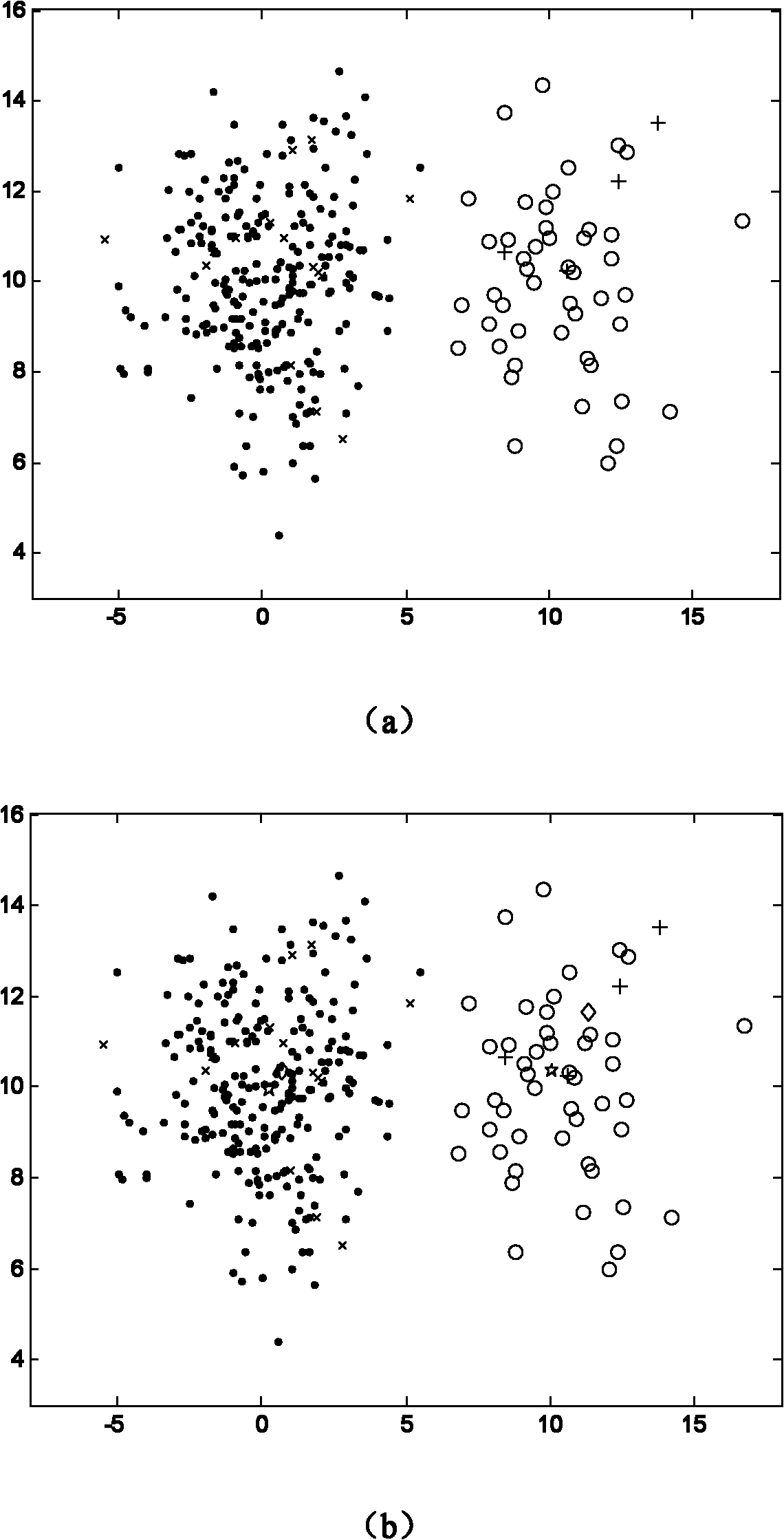
[0028] Given an unbalanced data set, the samples of the data set are divided into two types according to their characteristics and attributes, and these two types are recorded as the minority class and the majority class according to the number of samples. Randomly select a part of the balanced data set as the initial labeled sample set {x i}, using the remaining data samples as the initial unlabeled sample set {x j}.
[0029] Step 2, initialize the cluster centers of the unbalanced data set.
[0030] (2a) For the current labeled sample set {x i} in the minority class samples and the majority class samples are respectively averaged to obtain the mean center set M={m + , m -}, where m + is the mean center of minority class samples, m - is the mean center of the majority class s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More