Personalized music recommendation method and system
A recommendation method and music technology, applied in special data processing applications, instruments, electrical and digital data processing, etc., can solve problems such as slow and irregular changes, adjustment of recommended content, noise recommended data, etc., to achieve the effect of improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0030] The following describes the implementation process of the present invention in detail through specific embodiments.
[0031] The present invention is used to obtain user tastes, especially user tastes associated with time. At the same time, according to the acquired tastes of the users, songs that meet the tastes of the users are recommended for the users.
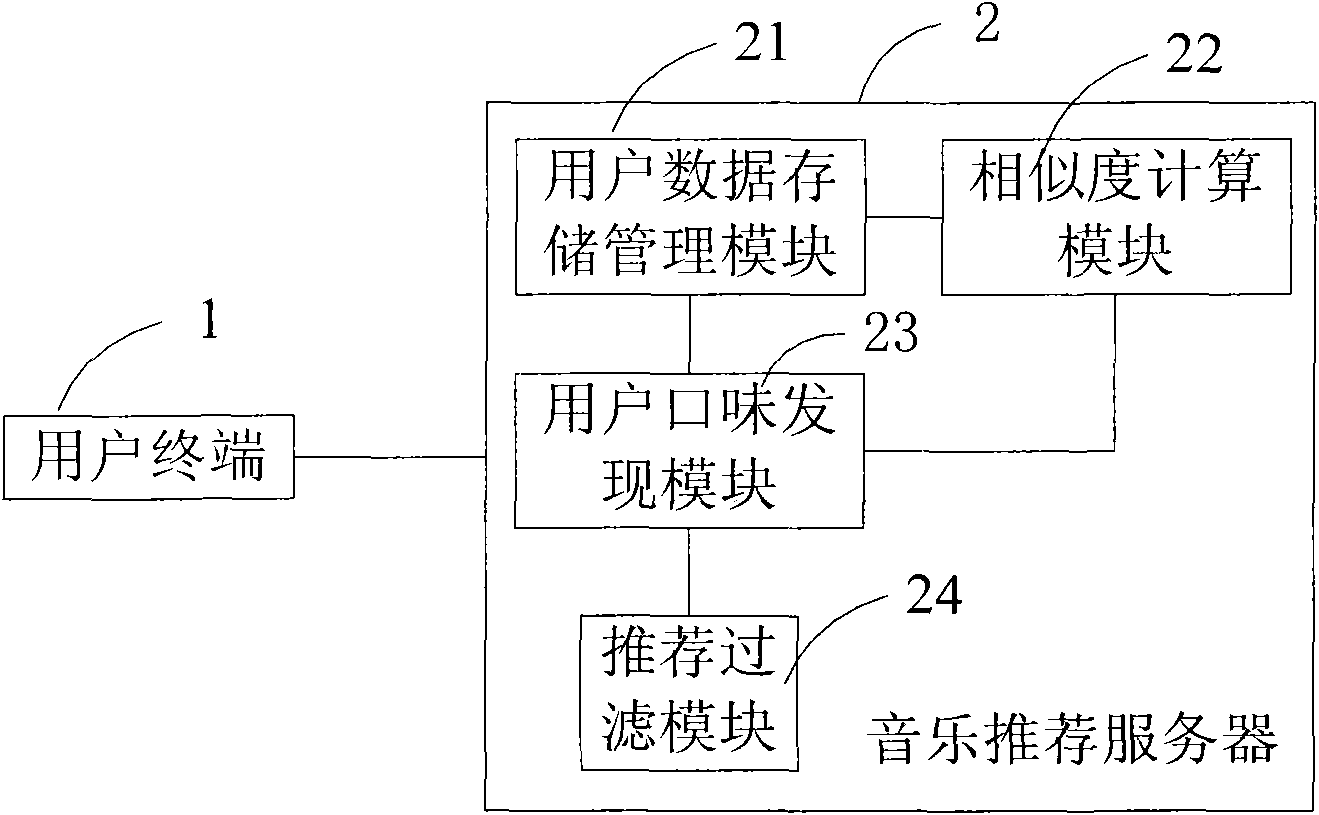
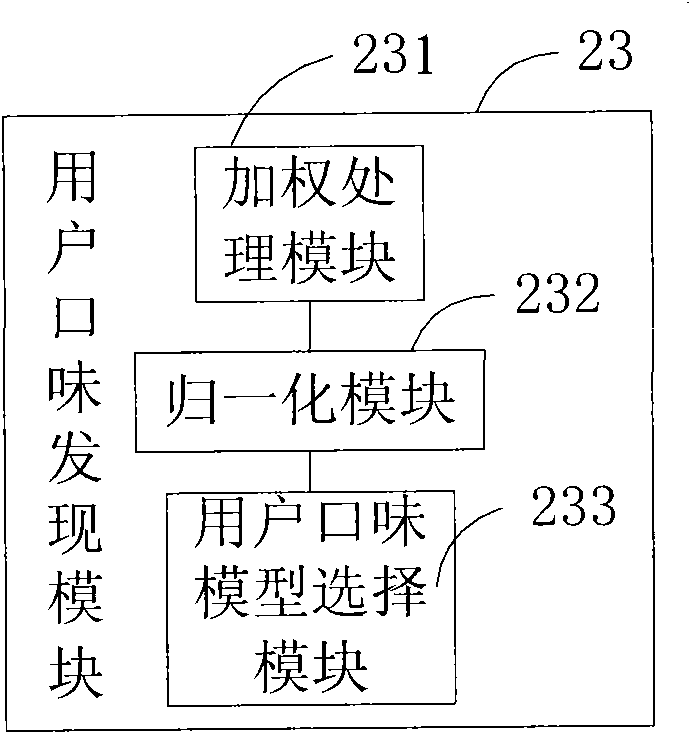
[0032] Such as Figure 1A Shown is a schematic diagram of the structure of the personalized music recommendation system of the present invention. At least one user terminal 1 is connected to the music recommendation server 2 through the network. The music recommendation server 2 includes a user data storage management module 21, a similarity calculation module 22, a user taste discovery module 23, and a recommendation filtering module 24. The user terminal 1 includes a PC, a mobile phone, a PDA, a tablet computer, a vehicle-mounted mobile terminal, and the like.
[0033] The user terminal 1 logs in to the music recommend...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More