

Visual speech multi-mode collaborative analysis method based on emotion context and system
A sentiment analysis and context technology, applied in the field of emotion recognition, can solve problems such as ignoring the context of the analysis object, not considering the real scene, and the decline in recognition accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0048] The present invention will be described in detail below in conjunction with various embodiments shown in the drawings. However, these embodiments do not limit the present invention, and any structural, method, or functional changes made by those skilled in the art according to these embodiments are included in the protection scope of the present invention.
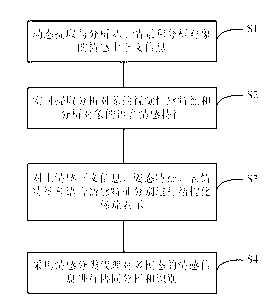
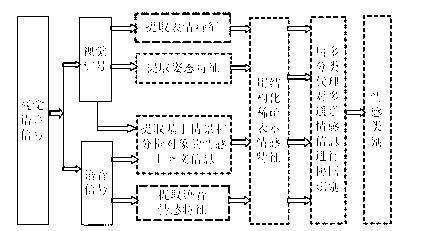
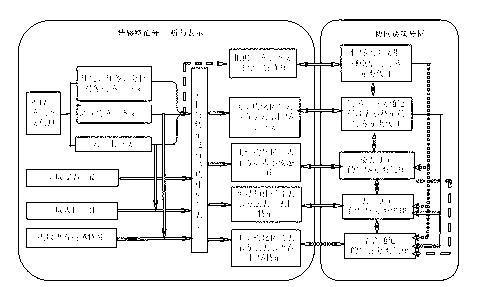
[0049] ginseng figure 1 , figure 2 As shown, the emotional context-based visual speech multimodal collaborative emotion analysis method of the present invention is characterized in that the method includes:
[0050] S1. Dynamically extract and analyze the emotional context information based on the situation and the analysis object in the visual-voice scene. The emotional context information includes the prior emotional context information and spatio-temporal context information (Spatio-temporal context) contained in the visual-voice scene, wherein the prior Emotional context information includes environmental con...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More