

A Method for Big Data Query Based on Distributed Relation-Object Mapping Processing
A query method and mapping processing technology, applied in the network field, to achieve the effect of ensuring data integrity and query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
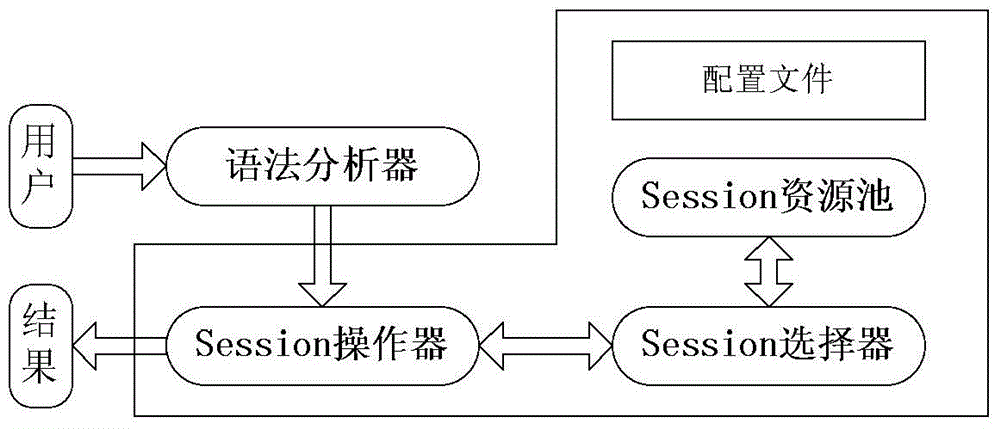
[0058] 1. Configuration work
[0059] Before loading Hibernate for the first time, you need to initialize the Session selector according to the configuration information of the configuration file. The format of the configuration file is as follows
[0060]
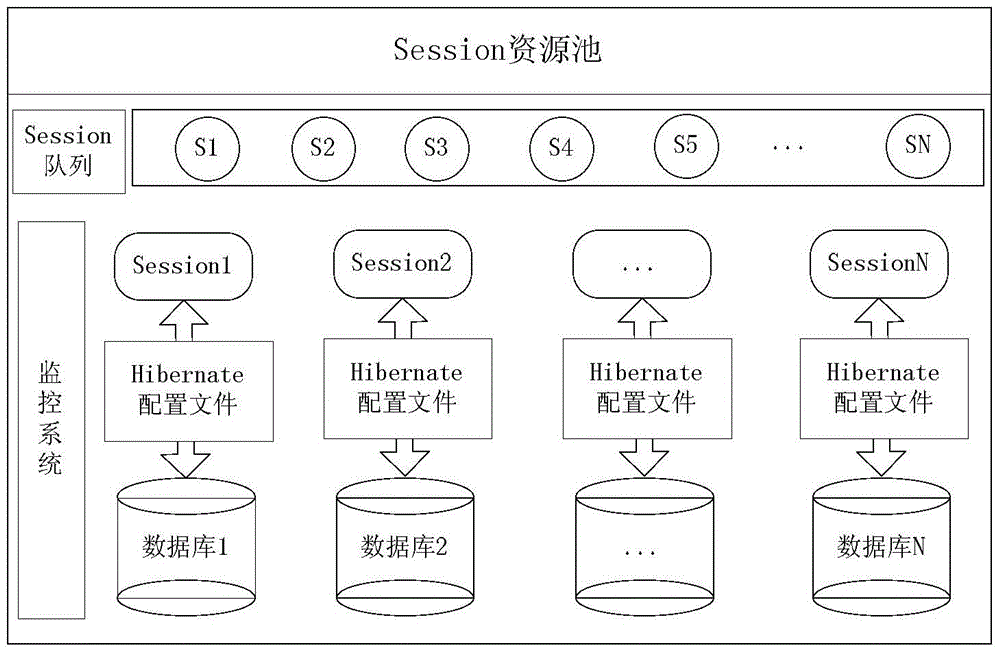
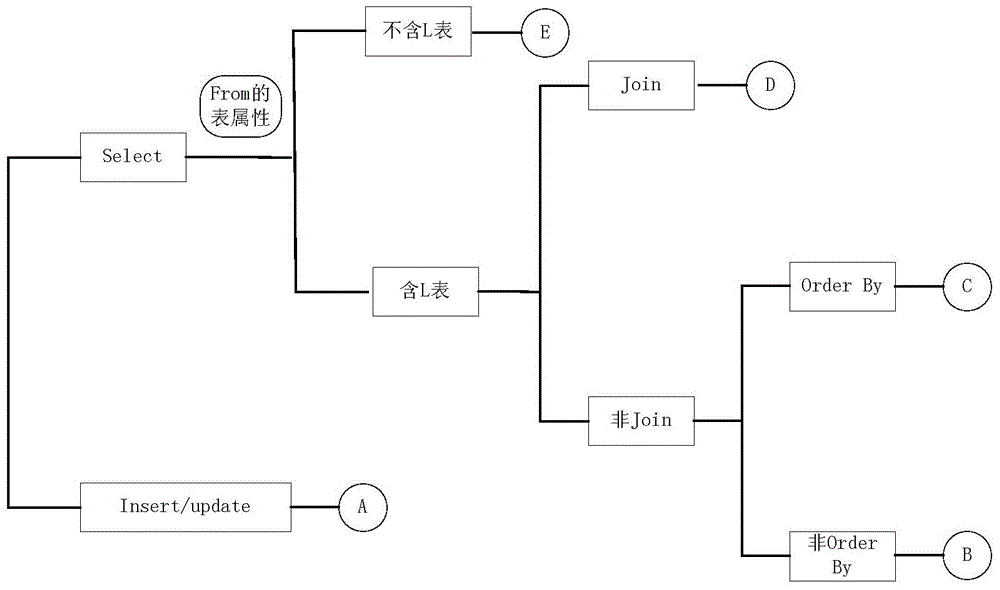
[0061] The configuration file mainly stores two types of configuration information: table attribute configuration and partition strategy configuration. The table attribute configuration is a Map collection. The elements in this collection are key-value pairs with the table name TableName as the Key and L or S as the Value. This Map can provide the basis for the table attributes for the Session selector and the parser. , the L-type table is a table with a large amount of data, and its data is stored in blocks on each data node according to the division strategy. The S-type table is a table with a small amount of data, and the table data is stored on each data node. full backup.
[0062] The second type of configuration...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More