

Text classification method and device based on Hadoop
A text classification and text technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as unbalanced training classifier data, overcome unbalanced distribution of training data, improve training efficiency, and improve uploading speed effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
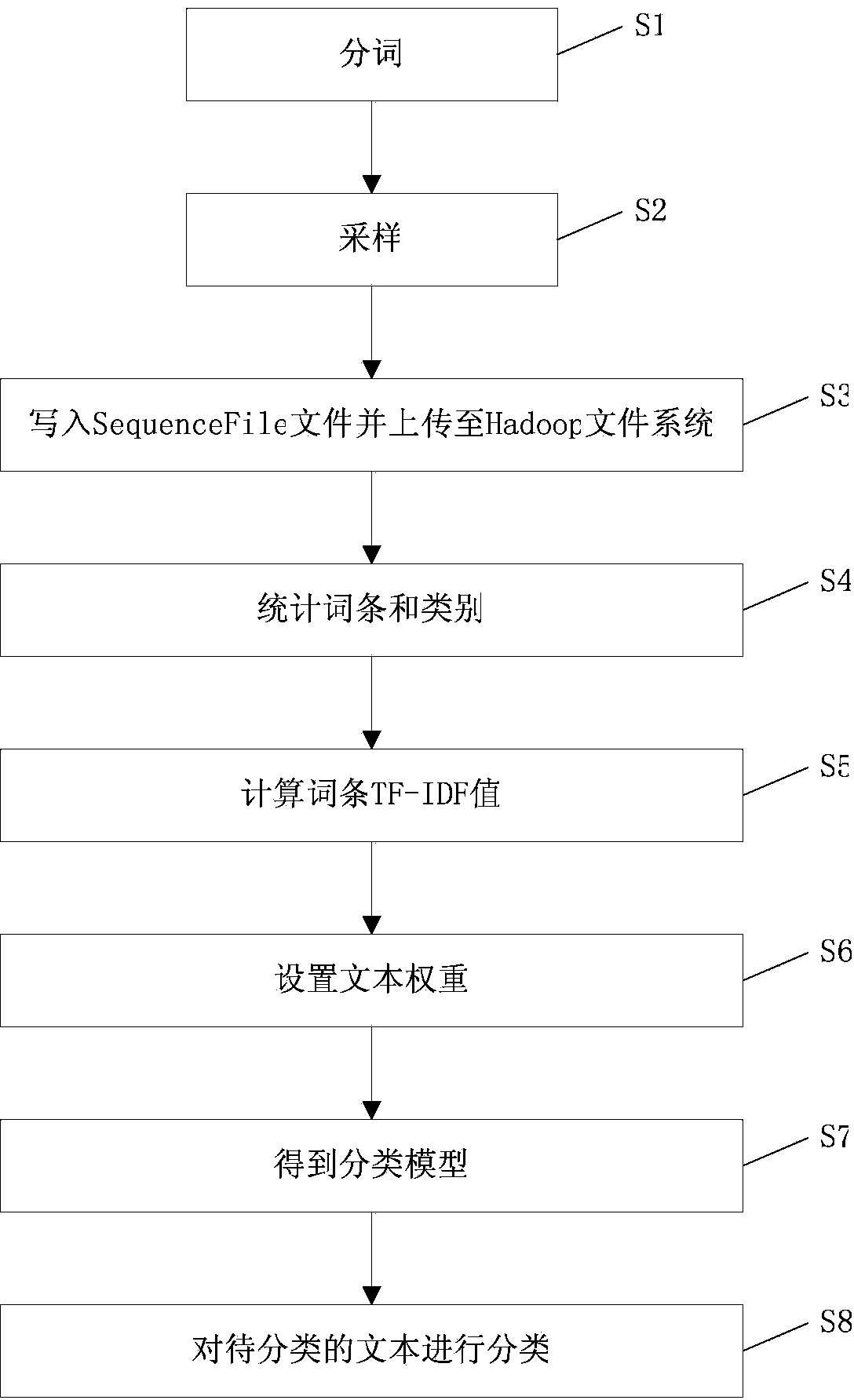
[0034] In the following, the present invention will be further described in conjunction with the drawings and specific embodiments.
[0035] combine figure 1 Shown, a kind of text classification method based on Hadoop, it comprises the following steps:
[0036] Step S1 , perform word segmentation processing on the text used for training, and save each word-segmented text into a corresponding text file in a training data set. Open source word segmentation packages such as IK and ICTCLAS can be used to perform automatic Chinese word segmentation on the training text, and remove punctuation and stop words. The stop words here refer to words that appear frequently but have no practical meaning, such as "and", "的", "得" and so on. And the entries obtained after word segmentation are separated by spaces and output to the local training data set. For example, the sentence "explain machine learning concept" will become three words "interpretation", "machine learning" and "concept" af...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More