

Efficient mass data indexing method in cloud computing
A massive data, cloud computing technology, applied in the field of cloud computing, can solve problems such as low access rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035] Below according to accompanying drawing of description, in conjunction with specific embodiment, the present invention is further described:
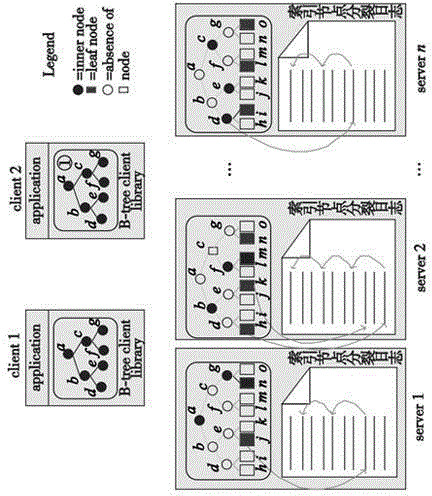
[0036] A high-efficiency indexing method for massive data in cloud computing. The method uses logs to record the split history of nodes on the basis of distributed B-trees, and efficiently and concurrently accesses distributed B-trees based on the split history of nodes, which effectively improves cloud computing. Massive, distributed data access and indexing efficiency in the environment.
[0037] Described method specific content is as follows:
[0038] Each server has a B-tree node split log, which is used to record the split history of all B-tree nodes distributed in the server;
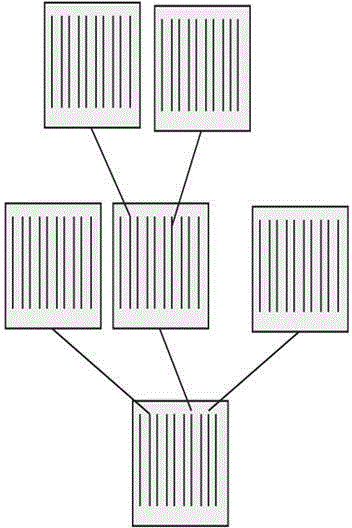
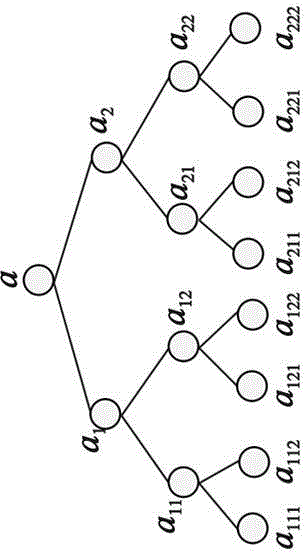
[0039] The splitting history is a record file sorted in chronological order. Its structure is shown in Figure 1. Each splitting of a node is recorded in the log as a record;
[0040]The record structure in the log is: , where LowValue and UpValue ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More