

Automatic document summarization extraction method based on term vectors
A document summary and automatic extraction technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as reducing the accuracy of node weights, affecting the performance of summarization, and ignoring the semantic similarity between sentences
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment
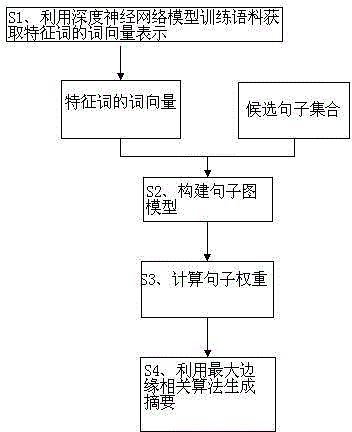
[0085] In order to make the purpose, technical solutions and beneficial effects of the present invention clearer and easier to implement, the present invention will be further described in detail in combination with the following specific embodiments and with reference to the accompanying drawings. In this embodiment, the length of the generated summary is preset to be 150 words.
[0086] S1. Use the deep neural network model to train the corpus to obtain the word vector representation of the feature words:
[0087] In order to obtain the vector representation of feature words, the embodiment adopts the biomedical literature database MEDLINE maintained by the National Library of Medicine of the United States to collect the corpus used for the experiment. Preprocess the sentences in the citation, that is, remove stop words, special characters, and punctuation marks against the stop word list, and finally obtain a 1.2G training corpus.
[0088] In the training process of this e...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More