

Emotion classifying method fusing intrinsic feature and shallow feature
A technology of emotion classification and deep features, applied in the field of emotion classification, can solve problems such as ignoring semantic relations, achieve the effect of improving classification performance and increasing accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

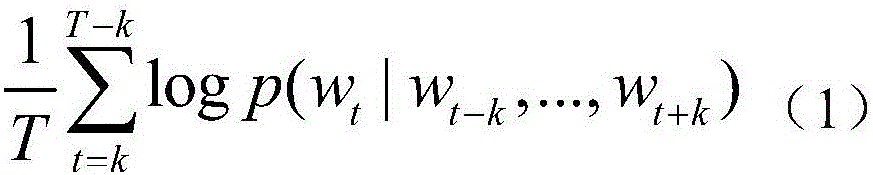
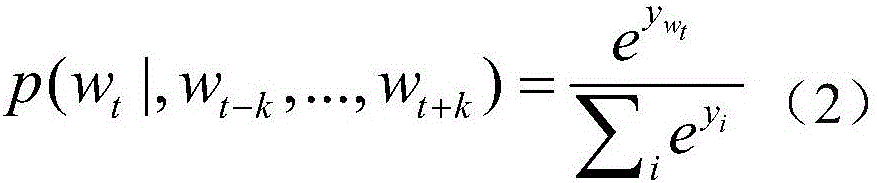
Examples
Embodiment Construction
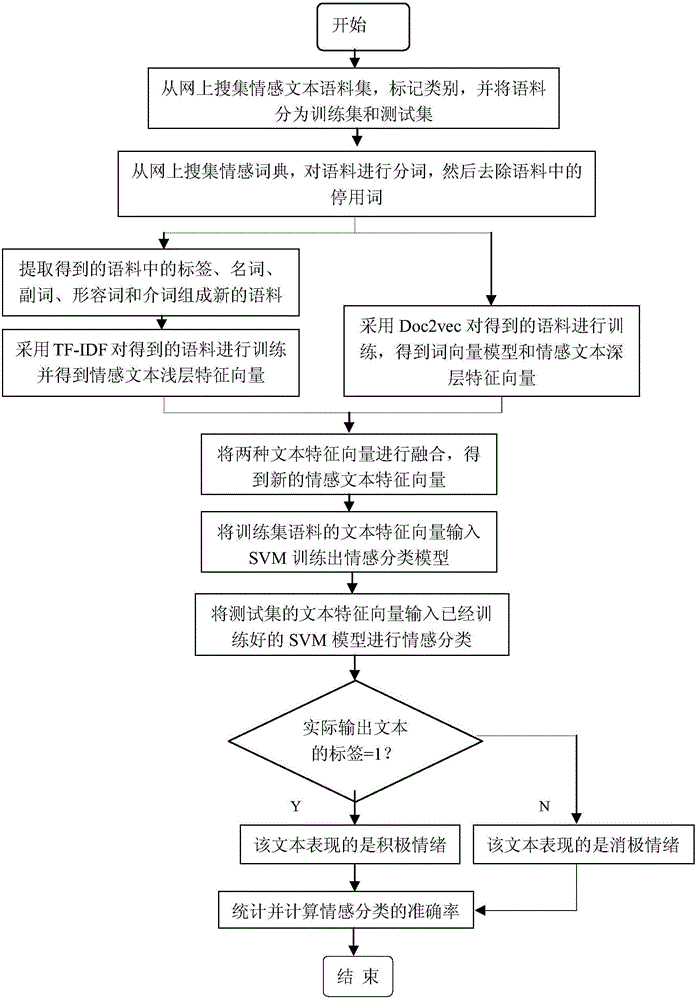
[0025] Below in conjunction with accompanying drawing, the present invention will be further described:
[0026] Such as figure 1 Shown, the specific steps of the emotional classification method of the present invention fusion deep layer and shallow feature are:
[0027]Step 1: Collect emotional text corpus from the Internet, and manually mark the categories, such as the text label of positive emotion is 1, and the text label of negative emotion is 2. And remove the leading and trailing spaces of the text, and represent the data in the text as a sentence, which is convenient for subsequent processing. And the corpus is divided into training set and test set. The training set is used to train the sentiment classification model, and the test set is used to test the classification effect of the model.
[0028] Step 2: First, collect sentiment dictionaries from the Internet. Sentiment dictionaries are the basic resources for text sentiment analysis, and are actually a collectio...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More