

Repeated data deletion framework-based reverse index representation method and system
A technology of data deduplication and inverted index, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., can solve coding problems, achieve the effect of reducing the number and improving the compression rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
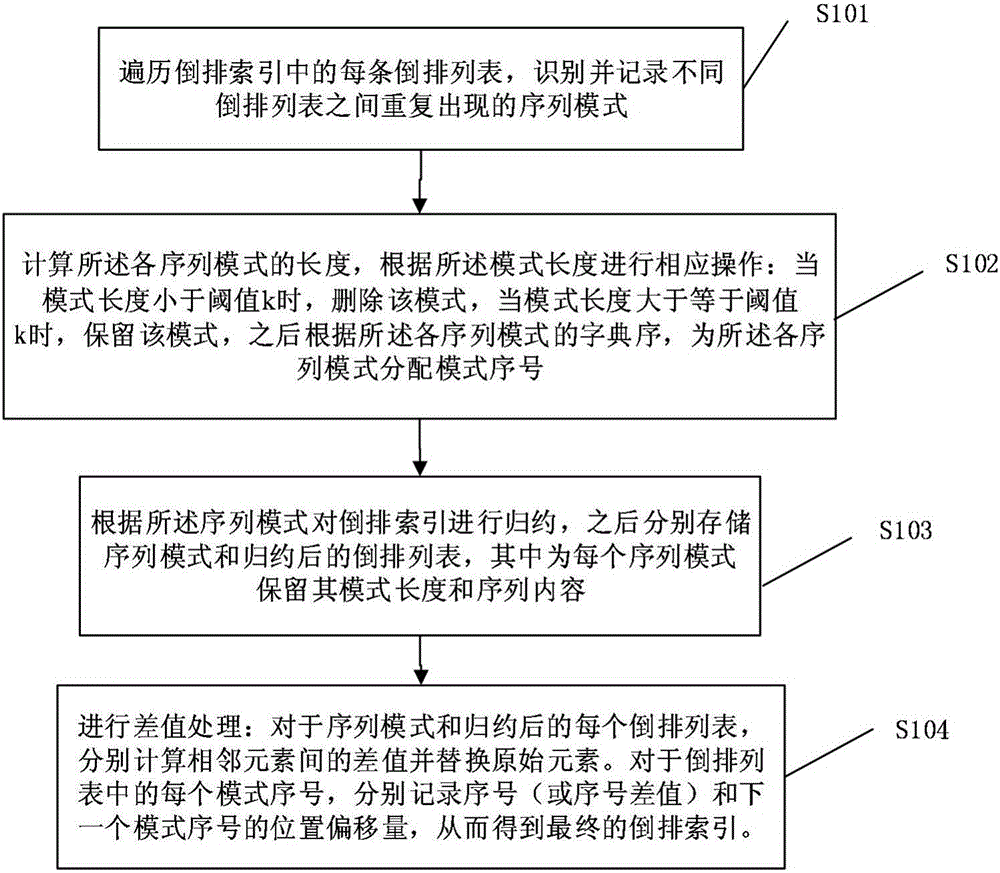
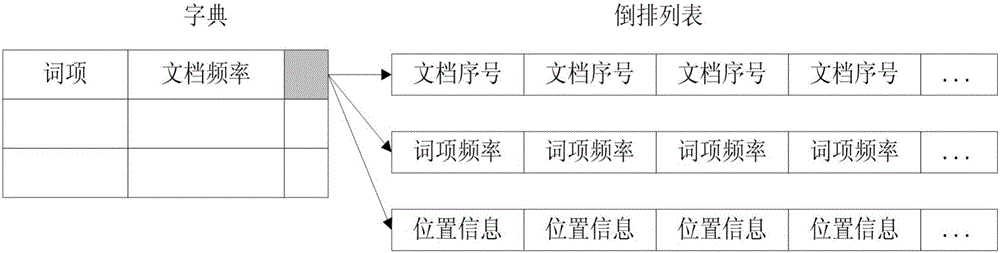
[0037] Inverted index representation method based on data deduplication architecture, its process see figure 1 . For an inverted index representation system implementing the described method, see figure 2 .
[0038] We call the sequence of document serial numbers with continuous values in the inverted list a sequence interval. For example, the sequence {10,11,12,13,14} can be called a sequence interval, while the sequence {10,11,13,14} is Contains two sequence intervals, the first sequence interval is {10,11}, and the second sequence interval is {13,14}. Through observation, we find that there are a large number of such sequence intervals in the inverted list, so in the present invention, we propose two strategies for identifying repeated document sequences between different lists: C1. identify any repeated document sequences; C2. only Identify repeating sequence intervals. For the case where the sequence pattern is a sequence interval, we use the run-length representa...
Embodiment 2
[0073] We compared the number of bits required for each document serial number and the corresponding decompression speed after various forms of index encoding on the TREC GOV2 dataset, where EF represents the inverted index representation based on the optimal segmentation strategy and Elias-Fano encoding Method; TD represents the inverted index based on the traditional d-gap, R represents the index representation based on the deduplication architecture (I and II represent the repeated sequence identification strategy adopted, corresponding to the strategy C1 and strategy C2 described above respectively) . The inverted index data set used is described as follows:
[0074] (1) TREC GOV2 is a data set captured from the .gov domain name in 2004, including more than 25 million web pages;
[0075] (2) We use the TREC 2009 query set as the query test set, which contains a total of 32,244 queries, and is used to test the average decompression speed of various forms of indexes for the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More