

Webpage text extracting method based on text tag feature mining
A technology for web page text extraction and text labeling, which is applied in the field of web page body text extraction based on text label feature mining, and can solve the problems of inability to adapt to web pages in real time and high maintenance costs.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0073] The technical solution of the present invention will be further described below in conjunction with the accompanying drawings.
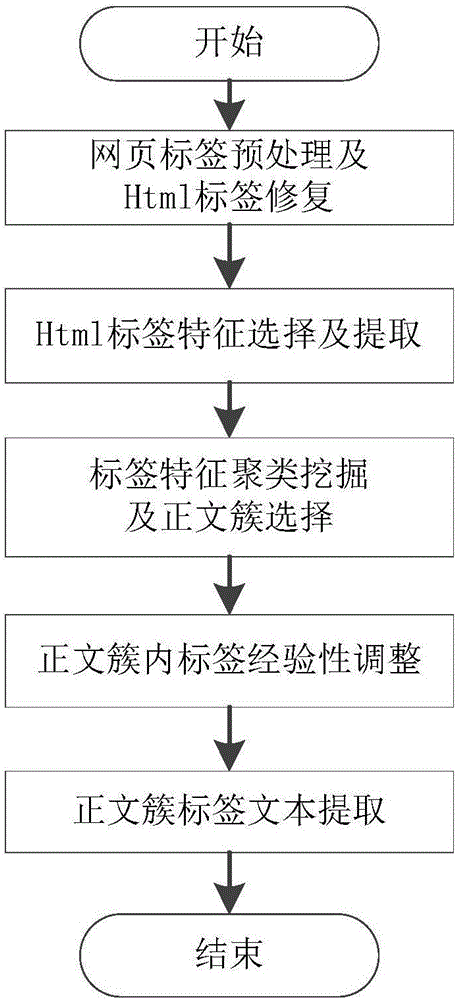
[0074] like figure 1 As shown, a web page text extraction method based on text label feature mining includes the following steps:
[0075] S1. Perform web page label preprocessing and Html label repair;
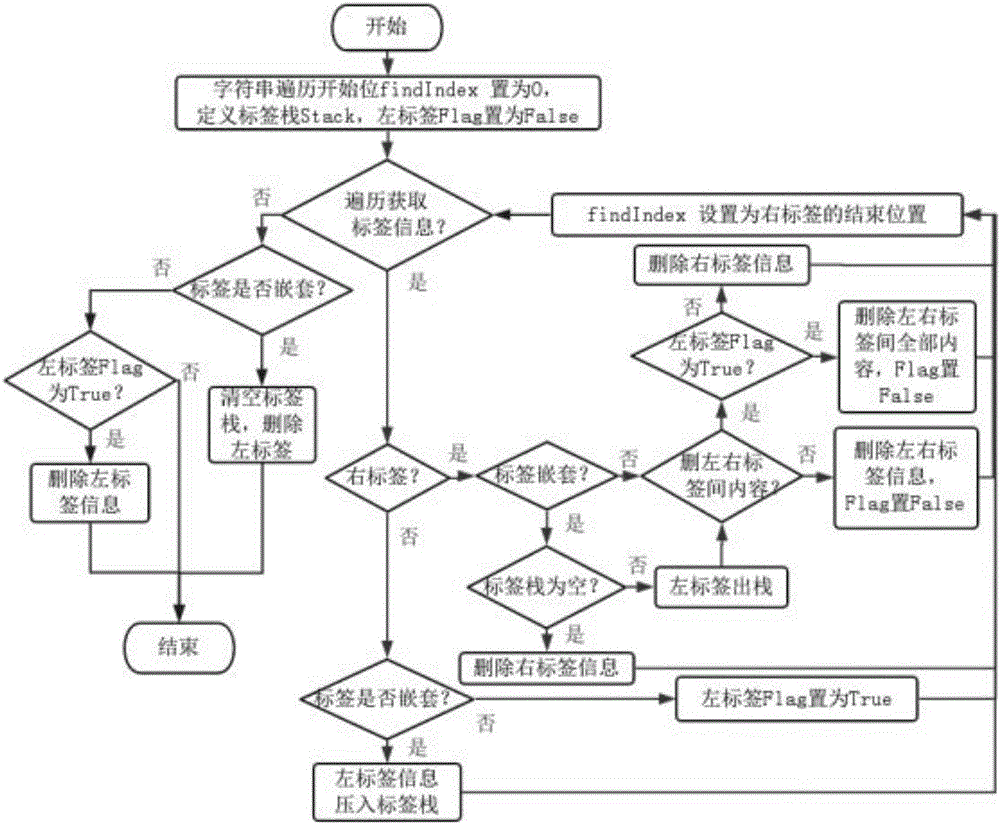
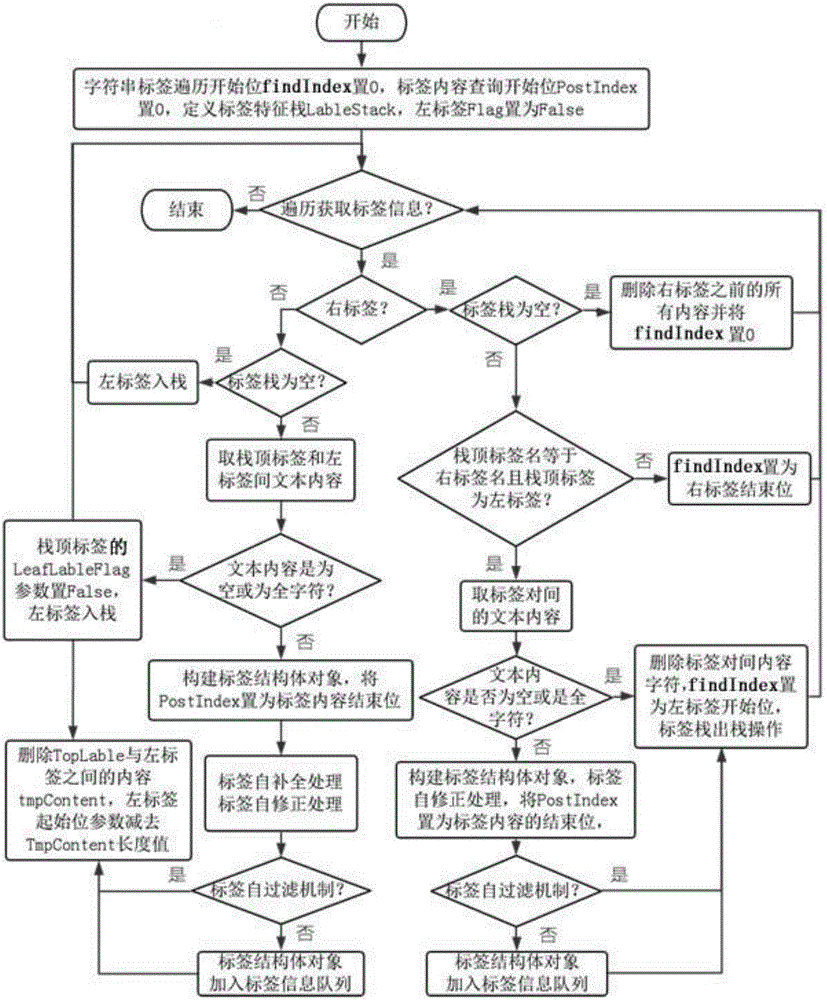
[0076] The web page text extraction method revolves around the text label features of the web page, and the web page tags contain a large number of useless noise tags, so it is necessary to exclude the script tags of the JavaScript language, the style tags used for the structural features of the web pages, and the noscript tags before extracting the tag features. Exclude annotation content tags, exclude useless table span tags and their internal list li tags, and exclude noise tags such as text formatting tags and newline tags.
[0077] According to the requirements of the following text, two situations should be considered in the process o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More