

Retrieval algorithm for deleting repetitive data in cloud storage
A technology of data deduplication and retrieval algorithm, applied in digital data processing, special data processing applications, computing, etc., can solve problems such as waste of cloud resources, retrieval troubles, similarity impact, etc., to achieve short running time and low system overhead , the effect of high deduplication rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

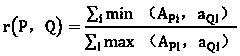
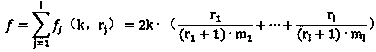
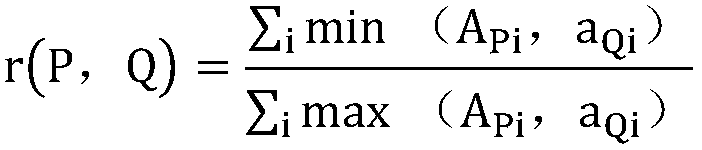
Examples
Embodiment Construction
[0006] In order to make the purpose of the present invention, technical solutions and advantages clearer, the following are the specific calculation steps of the technical solutions of the present invention:
[0007] Step 1. After the fingerprint data is divided into blocks, each file block is hashed, and the corresponding hash value is the fingerprint.
[0008] Step 2. Calculate the similarity between different file samples, and the specific solution process is as follows:
[0009] Assuming that there is a file P in the storage space, divide them into n file blocks according to the word length, hash each file block, and output a set A of hash values P , A P =(a P1 , a P2 ,...,a Pn ); Similarly, for file Q there are: A Q =(a Q1 , a Q2 ,...,a Qn )
[0010] If: A Pi =a Qi , indicating that the two file blocks are the same, then in the file P / Q, the number of identical blocks can be expressed as: ∑ i min(A Pi , a Qi ) The total number of blocks of the two files is: ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More