

Data persistent storage method and system based on federal Hadoop distributed file system
A technology of distributed data and storage systems, which is applied to data error detection, transmission systems, and electrical digital data processing in the direction of redundancy in computing, and can solve data backup number adjustment, cluster paralysis, and inflexible data backup strategies and other issues to achieve the effect of preventing single point failure, high fault tolerance and security
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0045] specific implementation plan
[0046] The technical solutions of the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments.
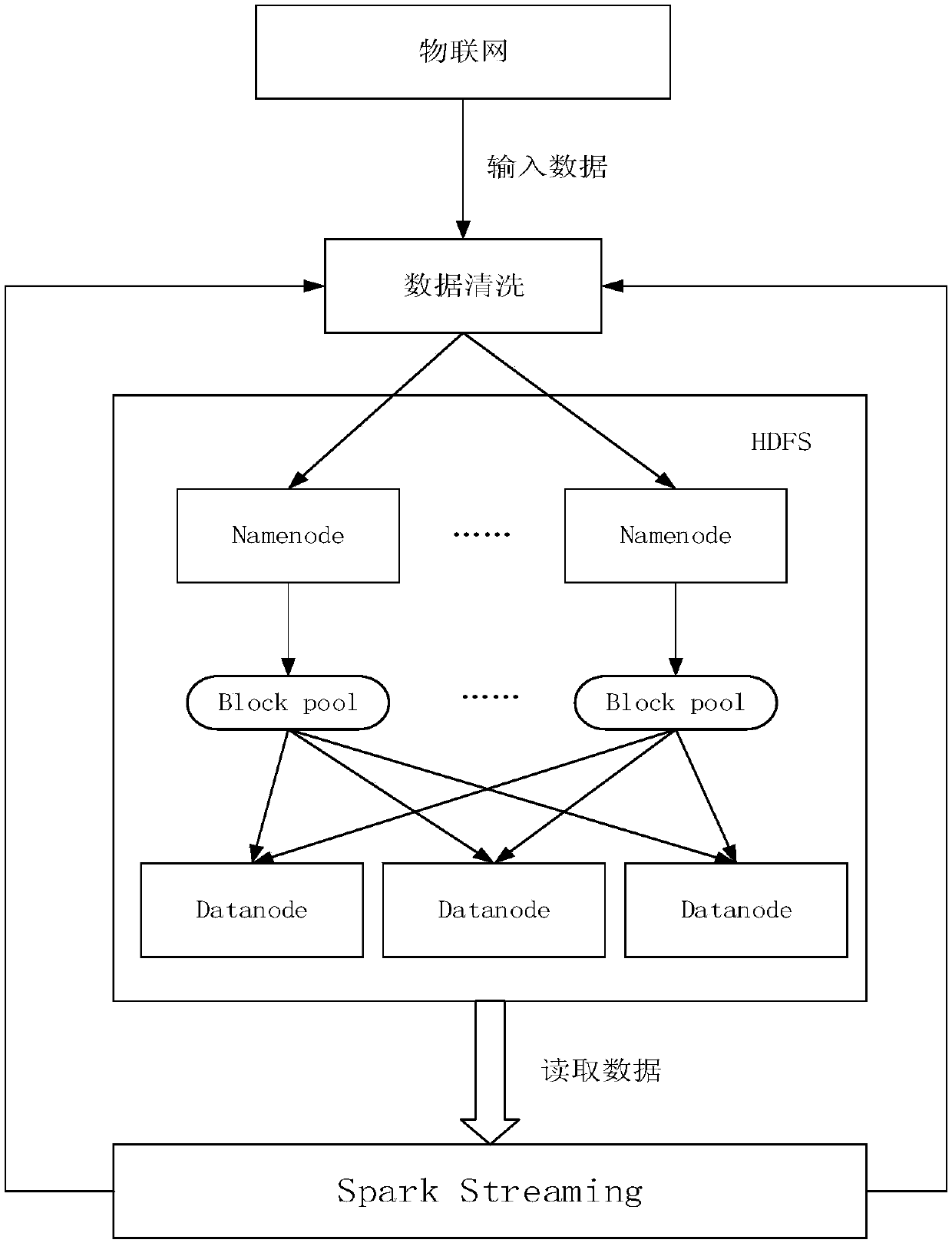
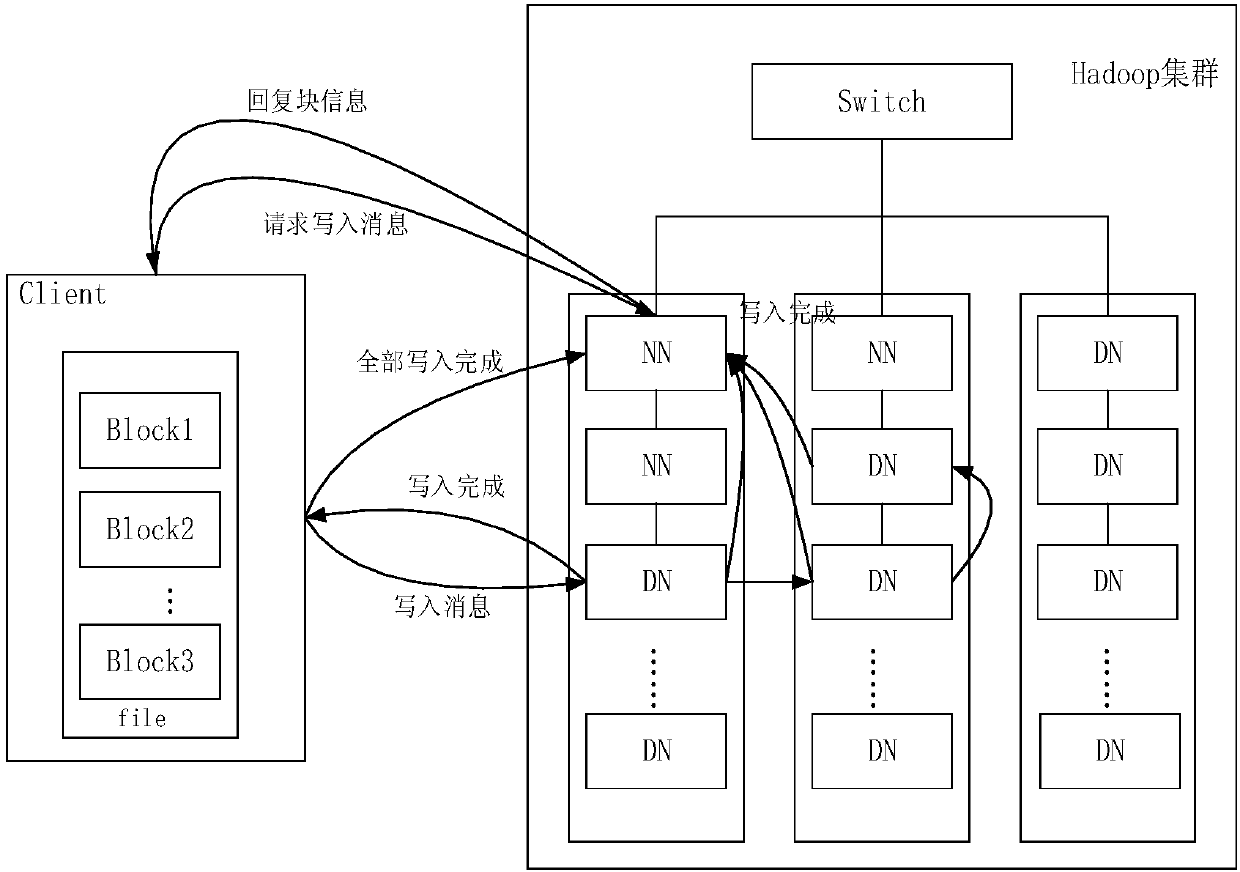
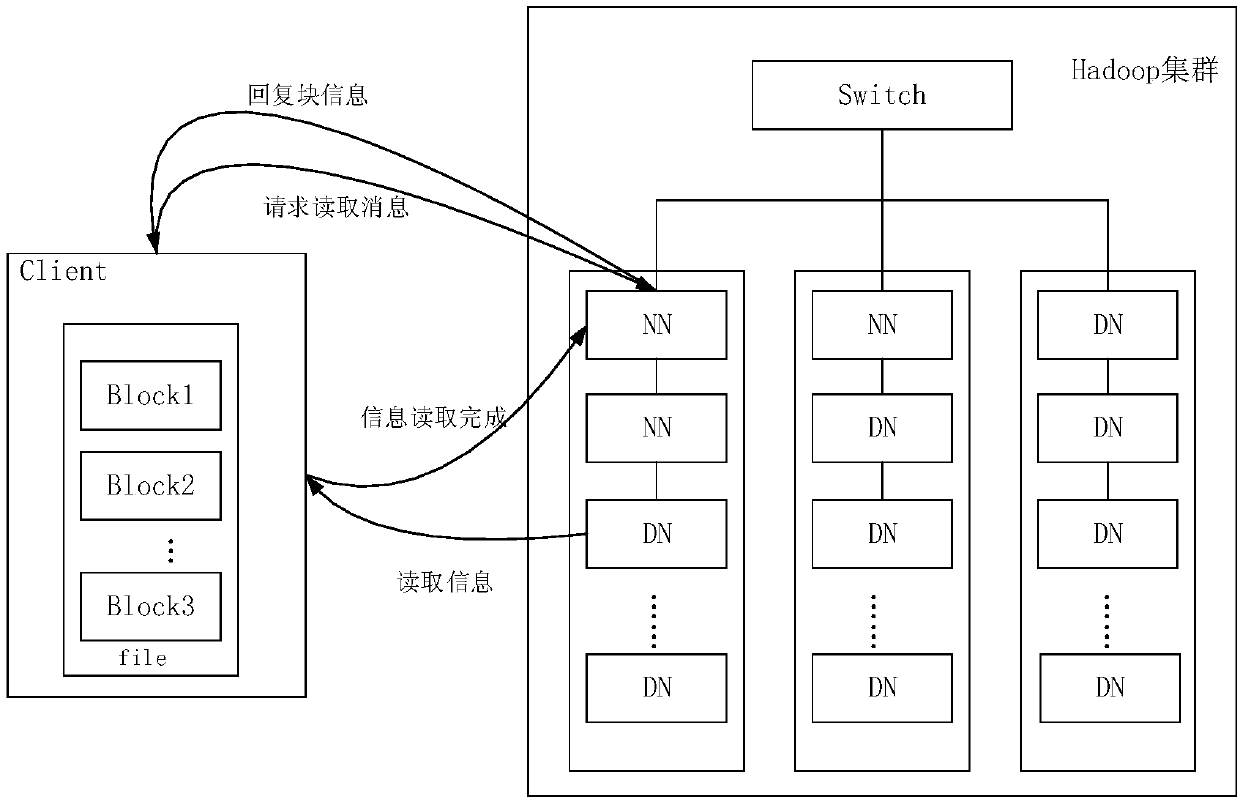
[0047] The method of the present invention utilizes federated HDFS technology to set different backup strategies for different block storage pools, classify and store data received from the Internet of Things into these block storage pools, and Spark Streaming processes newly added data in HDFS in real time , store the processed results in the federated HDFS and MySQL databases according to their importance, realize flexible data storage and safe isolation, and analyze the processed data. The cluster system architecture diagram is as follows figure 1 shown.
[0048] 1. Architecture
[0049] In the traditional distributed storage system HDFS, because it is easy to generate a single point of failure, the entire cluster will be paralyzed due to the failure of one node; the data ba...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More