

Unsupervised rapid clustering method and system suitable for big data
A clustering method, an unsupervised technology, applied in the fields of electrical digital data processing, special data processing applications, instruments, etc., can solve the problems of inapplicability to big data, high space complexity, large memory consumption, etc., to reduce space complexity and memory overhead, strong robustness, and the effect of improving operating efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
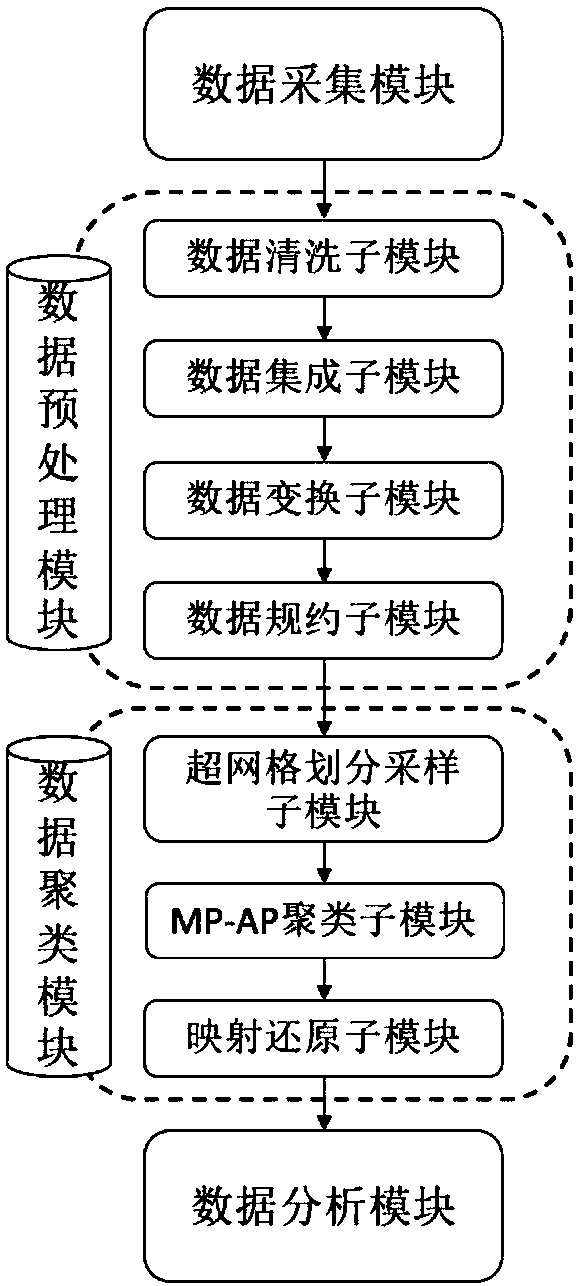
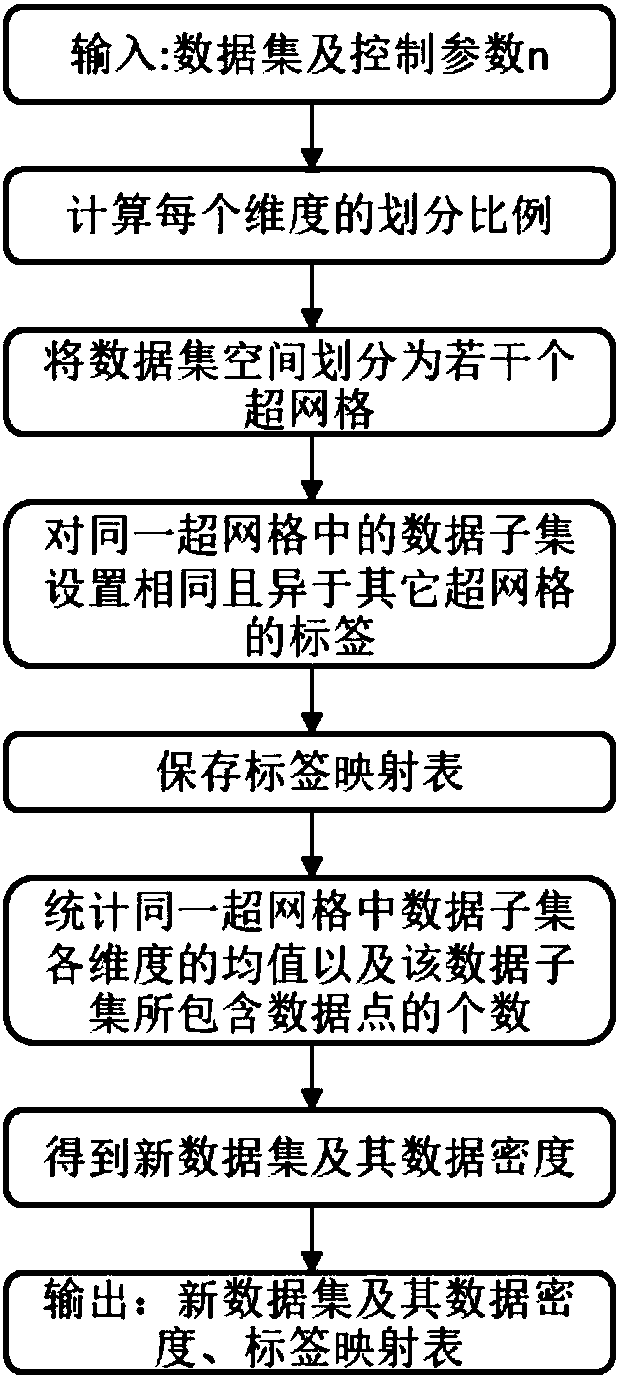
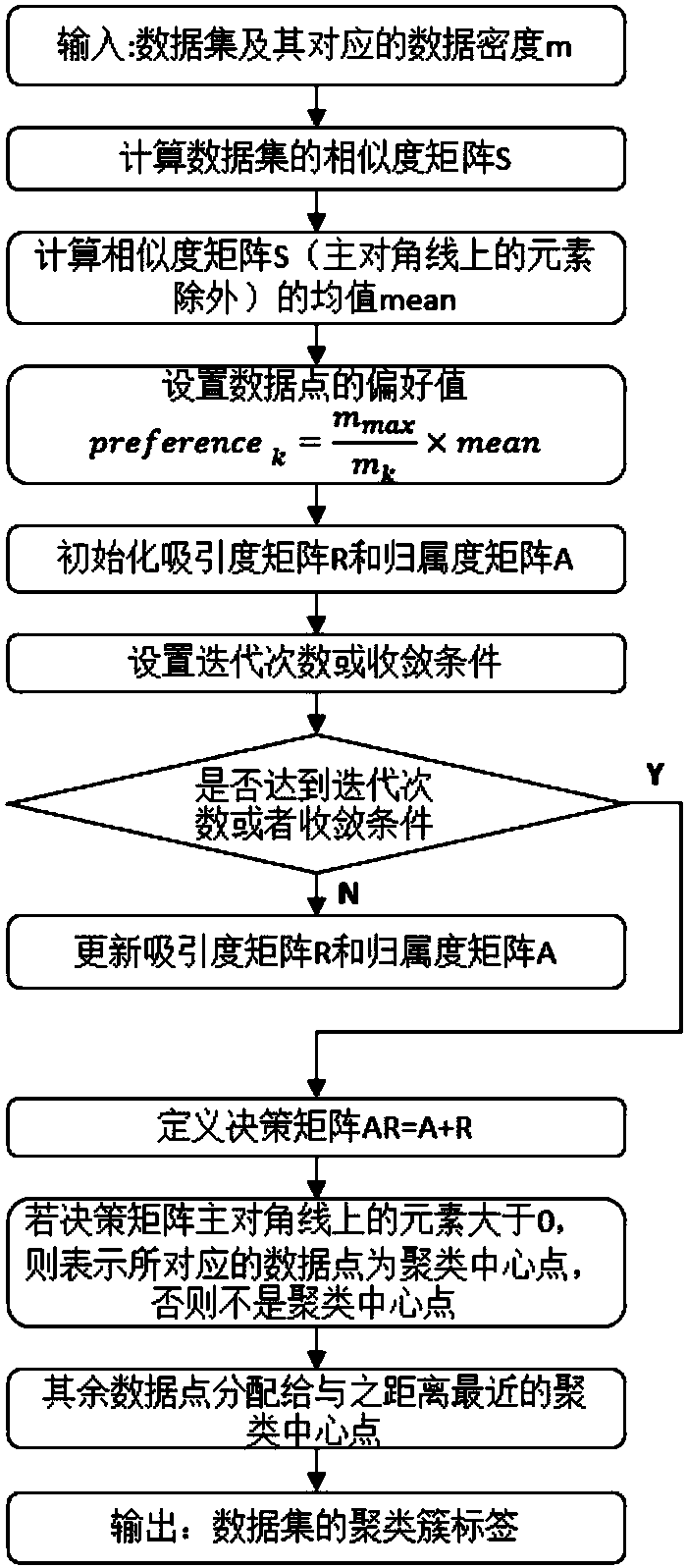
[0065] Such as figure 1 As shown, an unsupervised fast clustering system suitable for big data, including data acquisition module, data preprocessing module, data clustering module and data analysis module. Among them, the data preprocessing module can be subdivided into data cleaning sub-module, data integration sub-module, data transformation sub-module and data specification sub-module; data clustering module can be subdivided into hypergrid sampling sub-module, MP-AP clustering Classes submodules and maps restore submodules.
[0066] The specific method is:
[0067] Firstly, use the data collection module to identify and collect data from the data sources that generate information. Generally, data information can be obtained through web crawlers, website public APIs, and specific system interfaces provided by enterprises, and unstructured data can be extracted and stored as Unified local data files and stored in a structured way".
[0068] Then, the collected data is tr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More