

L2 norm standardization and cosine theorem improvement-based elbow rule method
A cosine theorem and norm technology, applied in the field of elbow rule based on L2 norm normalization and cosine theorem improvement, can solve the problems of unfavorable promotion and use, personal subjectivity, etc., and achieve the goal of reducing the dependence of the optimal clustering number Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
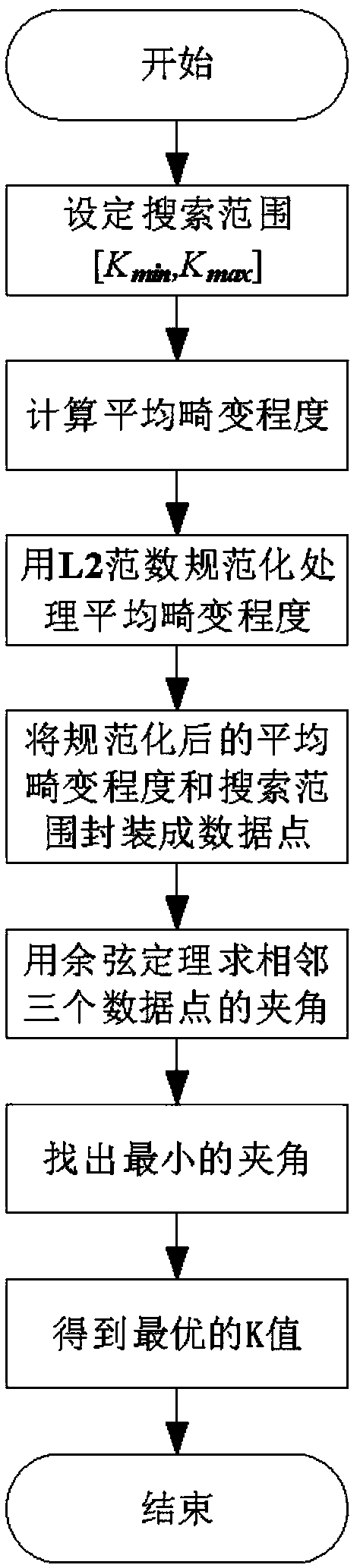
[0036] Embodiment 1: as Figure 1-5 As shown, the method based on the L2 norm normalization and the improved elbow rule of the law of cosines includes the following steps:
[0037] (1) Set the range to search for the best K value in the K-means clustering algorithm [K min , K max ];
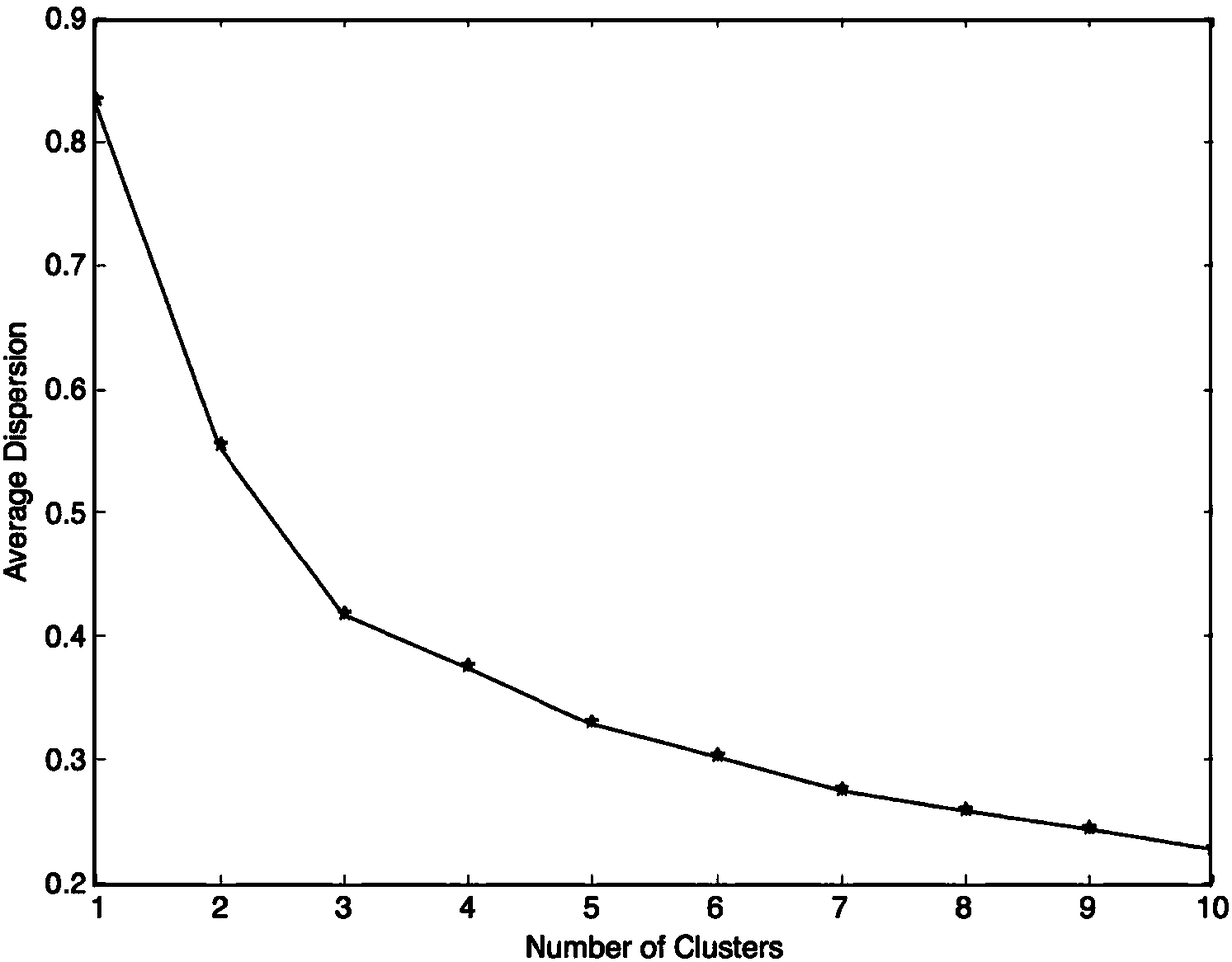
[0038] (2) Use the K-means clustering algorithm to calculate the search range [K min , K max K in ] max -K min The average degree of distortion corresponding to the number of +1 clusters;
[0039] (3) For the calculated K max -K min +1 average distortion degree for L2 norm normalization;
[0040] (4) K after normalizing the L2 norm max -K min +1 Average Distortion Level vs. Search Range [K min , K max K in ] max -K min +1 clustering number packed into K max -K min +1 data point;
[0041] (5) Utilize the law of cosines to find the K packaged above max -K min The angle between every three adjacent data points in +1 data point;
[0042] (6) Find the obtained K max -K min - the...
example 1
[0059] Example 1: The specific steps of the method for automatically identifying the optimal K value in the elbow rule are as follows:
[0060] Step1. Set the range of the best K value to search for in the K-means clustering algorithm Range: [K min , K min +1,...,K max -1,K max ];specific:
[0061] Assuming that the K-means clustering algorithm is to search for K in the best K value range Range min = 1,K max =9, that is, the range of searching for the best K value is: [1, 2, 3, 4, 5, 6, 7, 8, 9]; the actual number of clusters contained in the sample data set involved in this example is 3 , that is, the actual number of clusters is in the search range Range of the best K value;
[0062] Step2. Initialize the number of clusters k=K min , and generate a length K max -K min +1 and the average distortion degree list MDL with all elements being 0; specifically:
[0063] Since K is assumed in Step1 min =1, so initialize k to 1, that is, k=1; since K is assumed in Step1 mi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More