

Template-based classification system of electronic official documents
An electronic document and grading system technology, applied in the fields of electronic digital data processing, special data processing applications, instruments, etc., can solve problems such as poor applicability and false positives in the process of sensitive word screening, and achieve the effect of strong applicability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
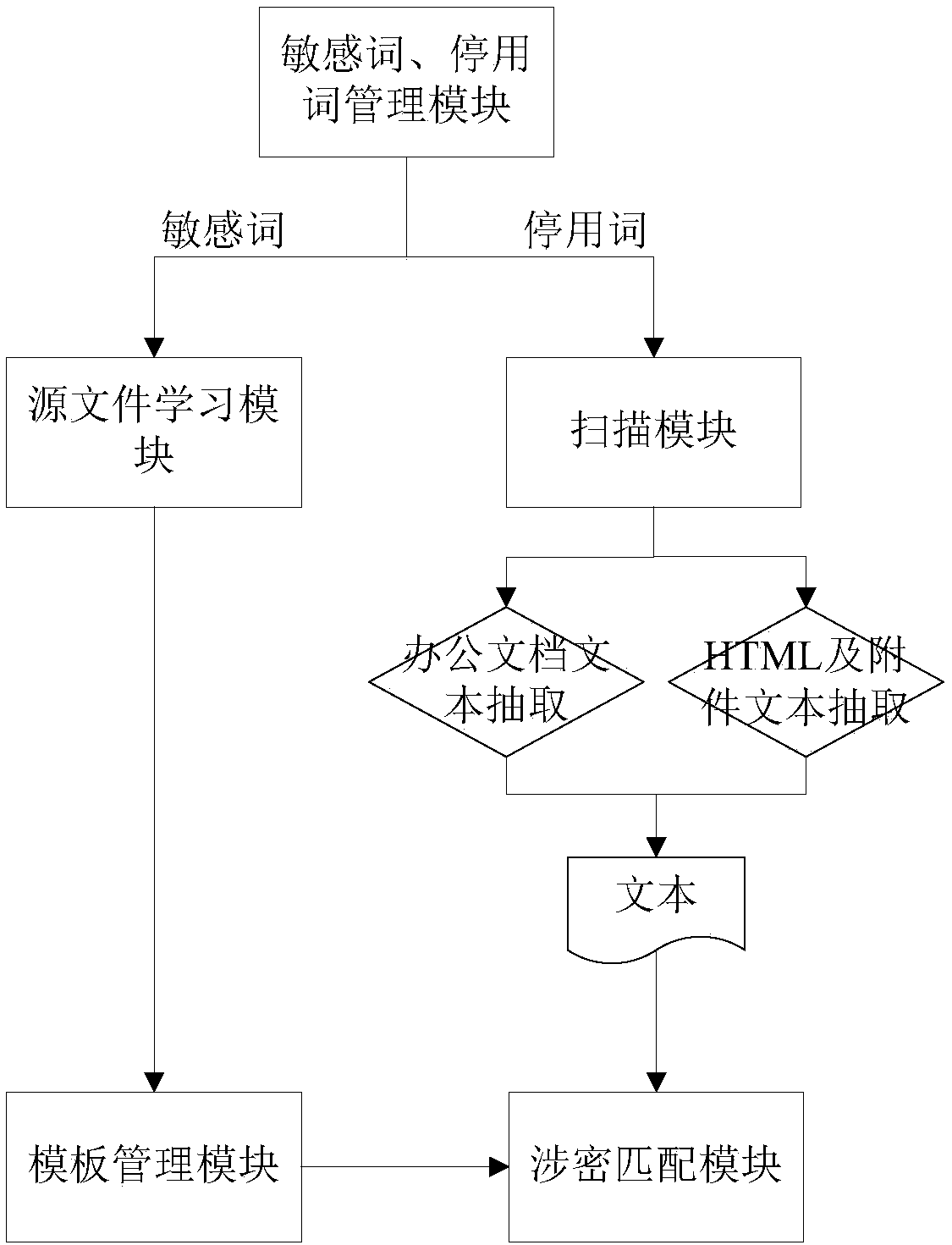
[0043] Specific implementation mode one: combine figure 1 To describe this embodiment,
[0044] A template-based electronic document classification and grading system, including:
[0045] Sensitive words and stop words management module, which is used to provide users with setting operations of sensitive words and stop words; Sensitive words; users can set stop words according to Chinese usage habits;
[0046] The sensitive words mentioned are key words or parameters that the user considers to be confidential or possibly confidential in the file or page;
[0047] The above stop words refer to certain words or words that are automatically ignored when the scanning module is scanning to index pages or process search requests in order to save space and improve search efficiency; in a general sense, stop words roughly include tone Auxiliary words, adverbs, conjunctions, etc., usually have no clear meaning by themselves, and only have a certain effect when they are put into a co...
specific Embodiment approach 2
[0054] The scanning module described in this embodiment includes a file scanning submodule and a URL scanning submodule:
[0055] The file scanning submodule is used to provide full-text text extraction for office documents such as Office series documents and PDF; for compressed files such as ZIP and RAR, it provides decompression and then performs file type determination and text extraction operations, and supports Nested recursive decompression of compressed files;
[0056] The URL scanning sub-module is used to scan the URL (Uniform Resource Locator, Uniform Resource Locator) of the specified location, and use the search engine crawler technology to crawl recursively according to the set number of crawling layers, so as to realize the text extraction of HTML pages and page attachments; In the form of attachments, it also supports office documents such as Office series, PDF and other document types, as well as text extraction of compression types such as ZIP and RAR;
[005...
specific Embodiment approach 3
[0058] The file scanning sub-module described in this embodiment encapsulates the text content extraction of different files, that is, only a single interface is provided to realize the content extraction of documents such as Office and PDF. When the URL scanning sub-module extracts HTML content, the encoding of the processed text is UTF-8 by default.
[0059] The scanning module has designed a unified multi-format text content extraction interface: it supports the text content extraction of Office and PDF, and the text extraction of HTML and attachments. Because the text extraction methods of different types of documents are different, even different versions of the same type of documents have Differences, such as Office 2003 and Office 2007, extracting file content separately will lead to interface complexity and lower maintainability. In view of the above situation, the text content extraction of different files is used to encapsulate, that is, only a single interface is pro...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More