

ElasticSearch (ES) query acceleration method
A technology of query conditions and query results, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as occupancy, achieve efficient operations, improve indexing efficiency, and improve concurrent query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
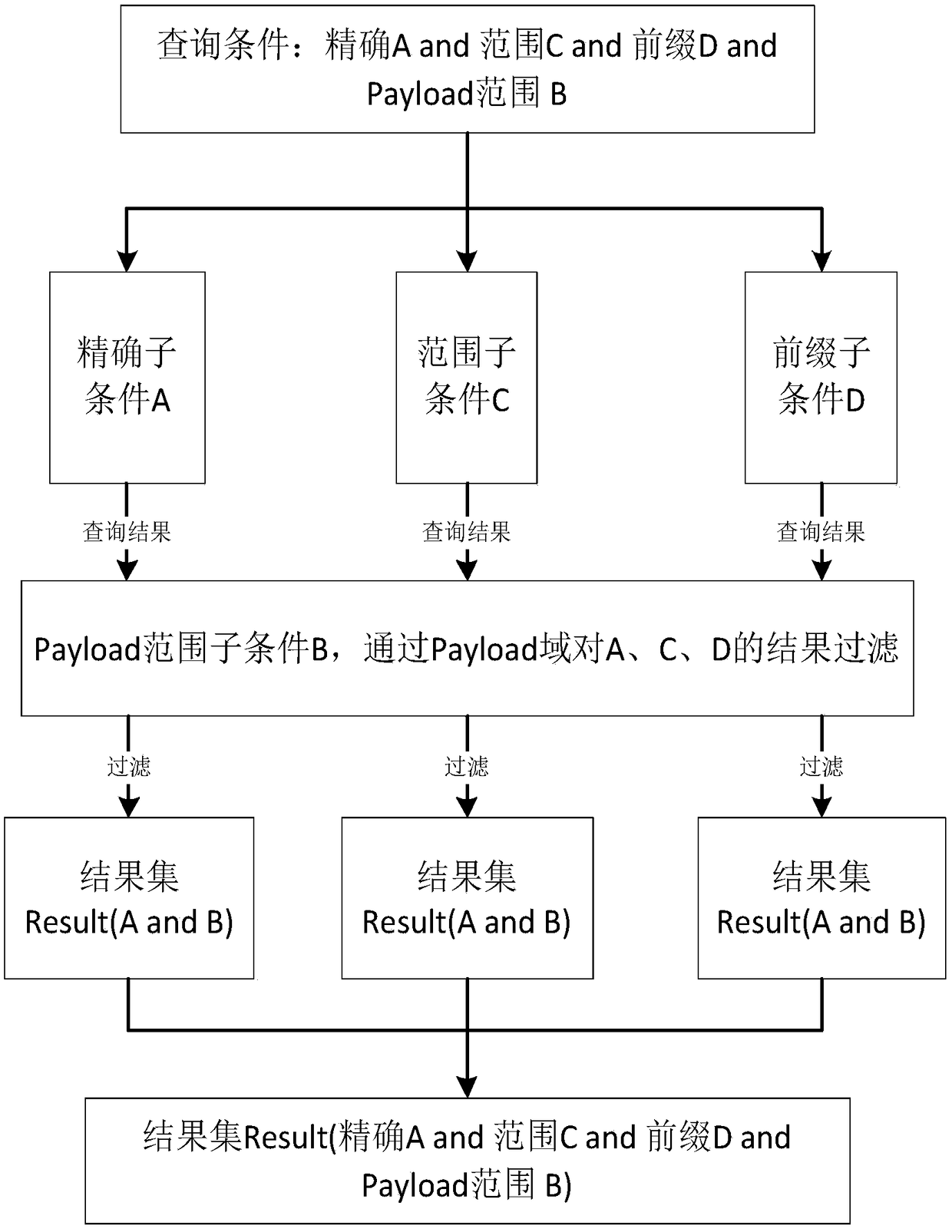
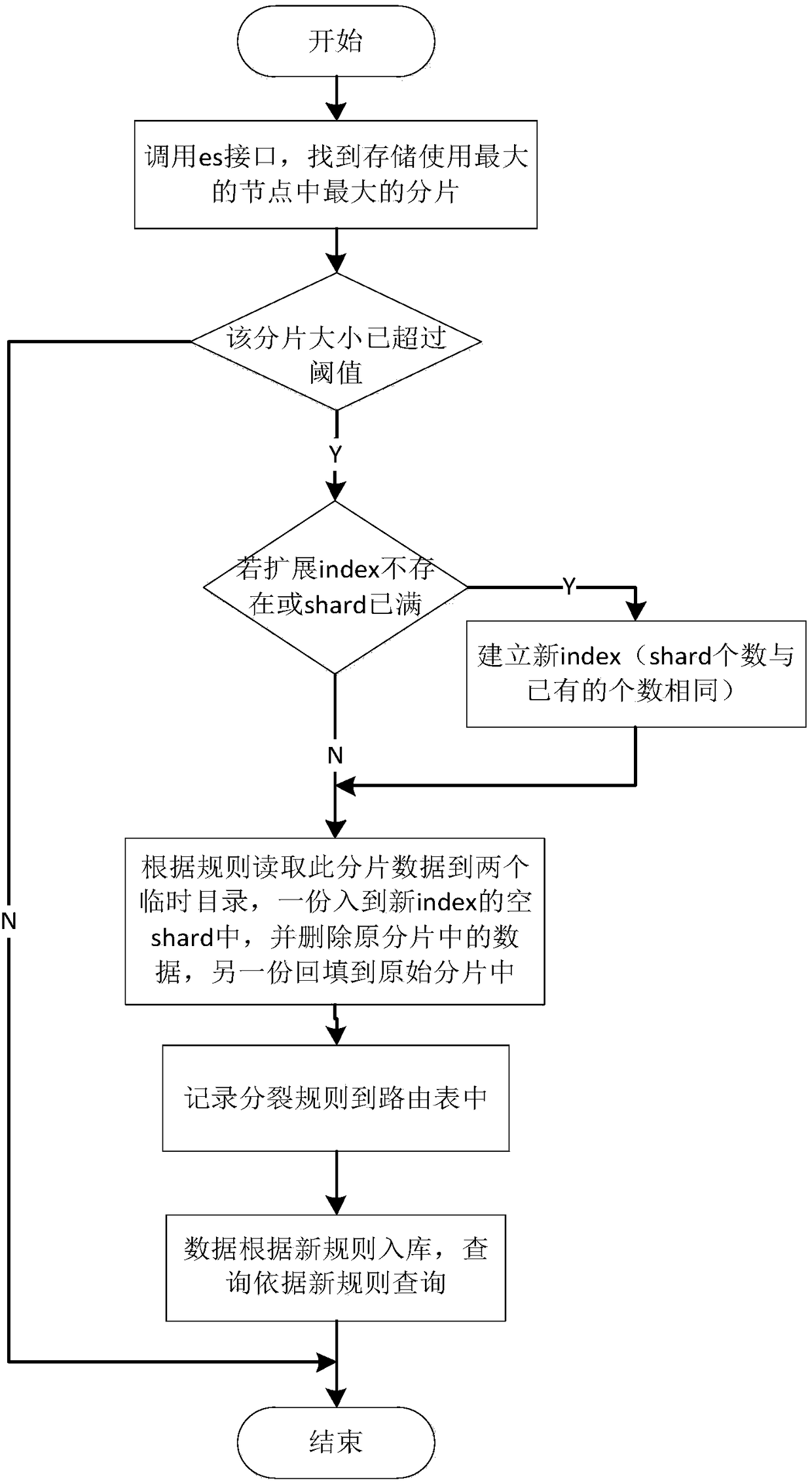
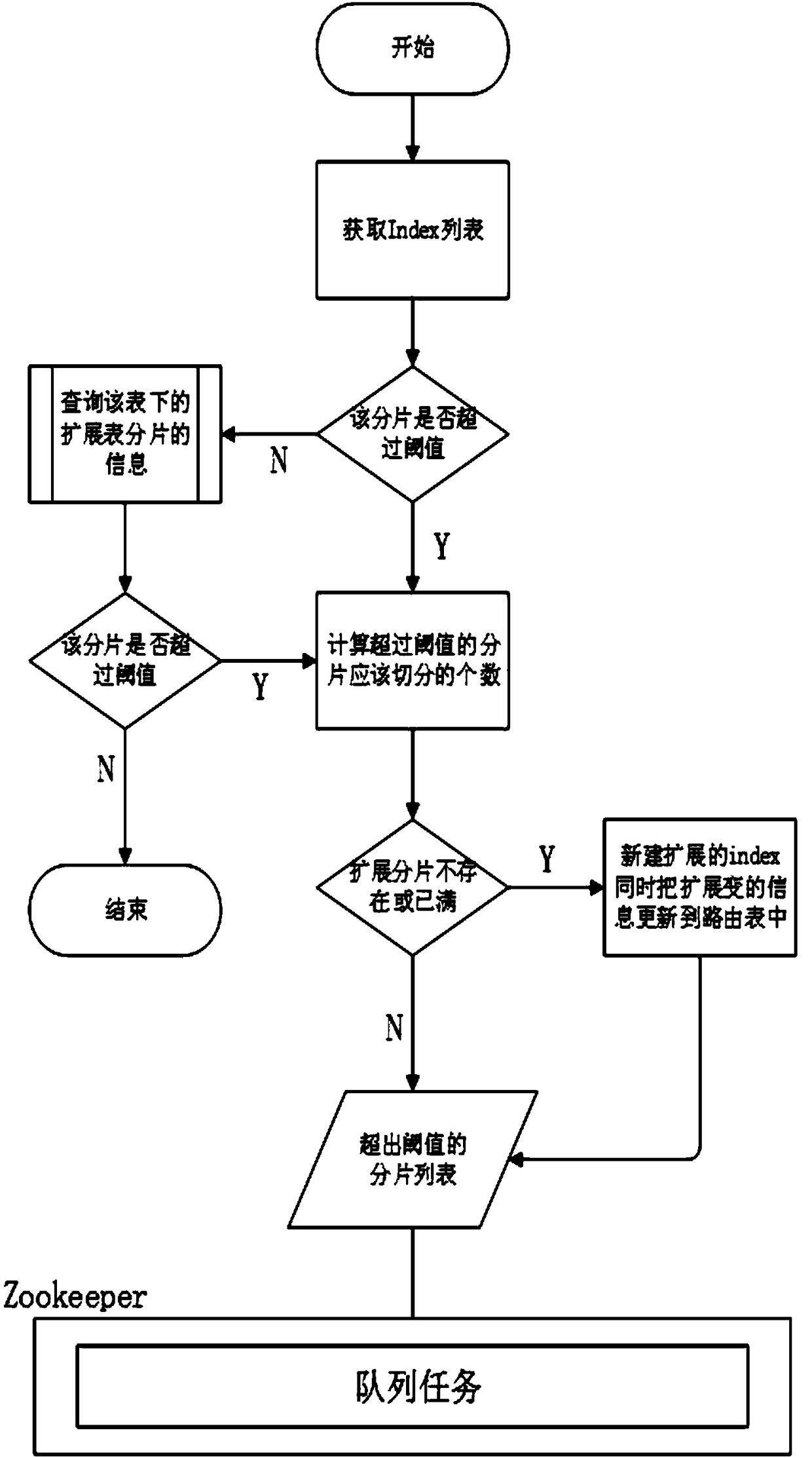
[0044] Such as Figure 1 to Figure 4 An ElasticSearch query acceleration method shown includes the following steps:
[0045] Step 1: Establish a full-text index system. The full-text index system includes a Hadoop storage server cluster, a WEB interface server, a data import server and a data collection terminal. The data collection terminal is connected to the data import server through the Internet, and both the WEB interface server and the data import server are connected through the Internet. Hadoop storage server cluster;
[0046] Step 2: Establish a full-text retrieval platform in the Hadoop storage server cluster through the Lucene full-text information retrieval tool, and allocate an ES cluster in the Hadoop storage server cluster through the Lucene full-text information retrieval tool;
[0047] Step 3: The data collection terminal inputs stream data or text data to the data import server, and the data import server sends the stream data or text data to the Hadoop sto...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More