

A Big Data Query Method Based on Data Distribution
A query method and data distribution technology, applied in the field of big data query, can solve problems such as high cost, query response time exceeding users, and query algorithm is difficult to further optimize, to ensure randomness, good scalability and maintainability, improve The effect of query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0046] The specific implementation manners of the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. The following examples are used to illustrate the present invention, but are not intended to limit the scope of the present invention.
[0047] This implementation uses the data requested to visit the 1998 World Cup sports event web site (WorldCup98, the website is http: / / ita.ee.lbl.gov / html / contrib / WorldCup.html) as an example, using the data distribution based method of the present invention The big data query method queries the data. This data is massive data with multiple attribute values, including attribute values such as time stamp, server, visitor IP address, and data request type.
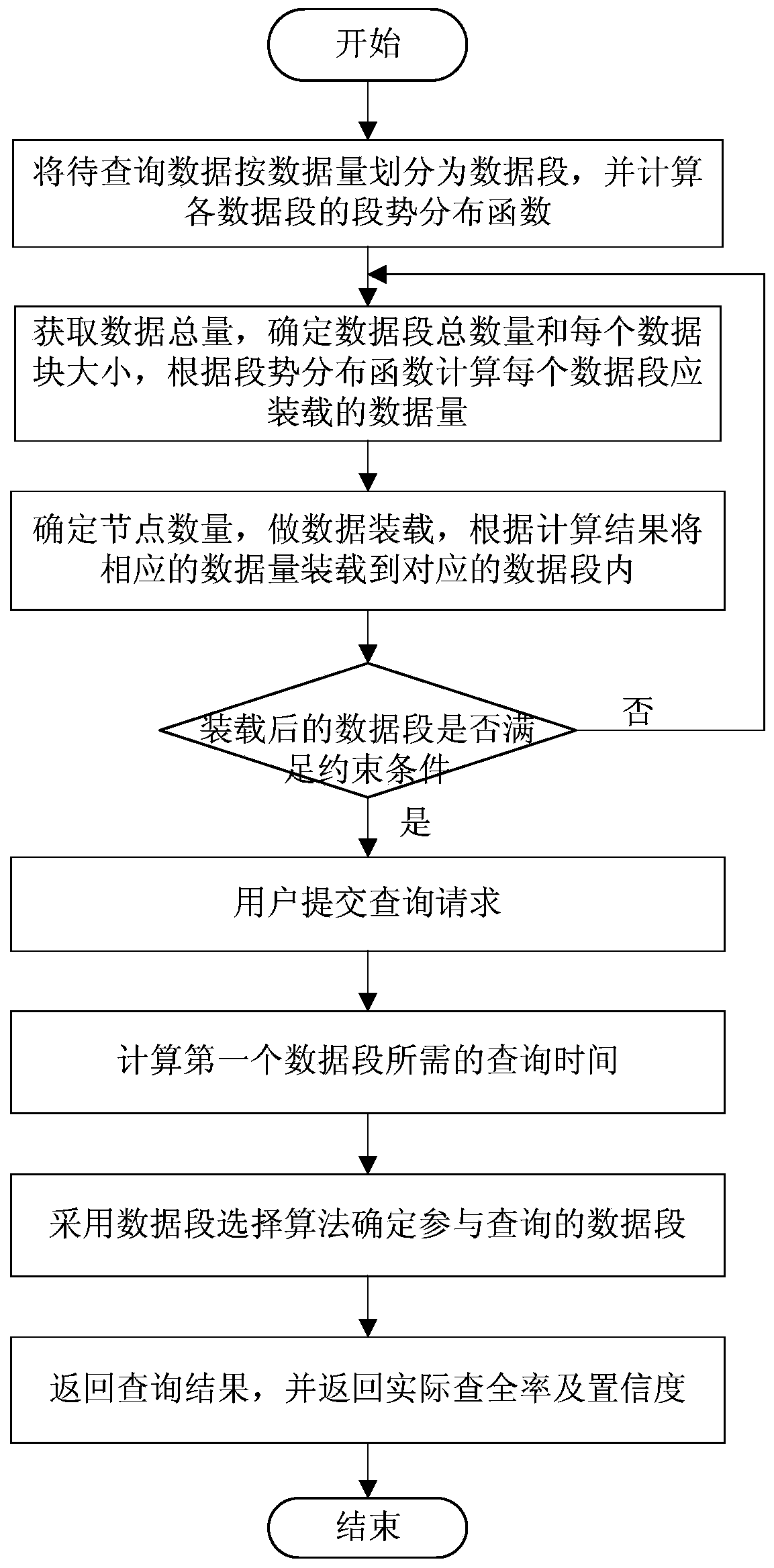
[0048] A big data query method based on data distribution, such as figure 1 shown, including the following steps:
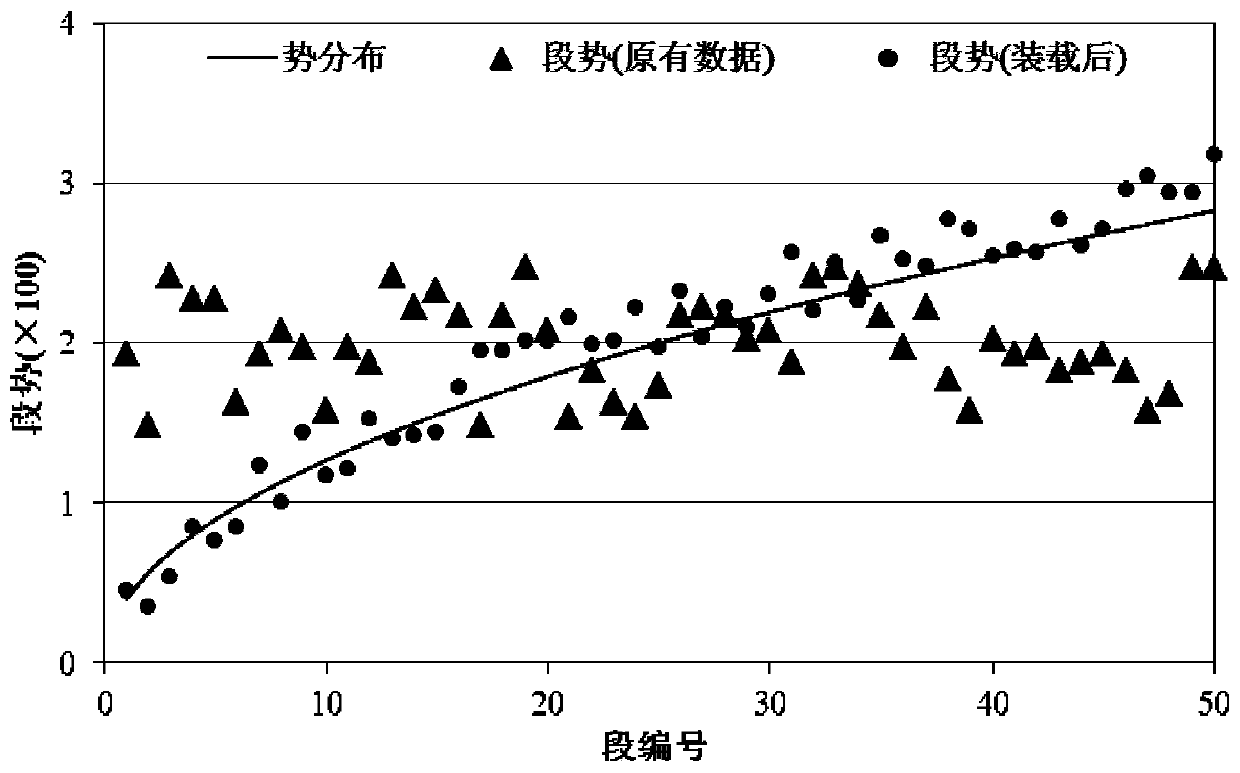
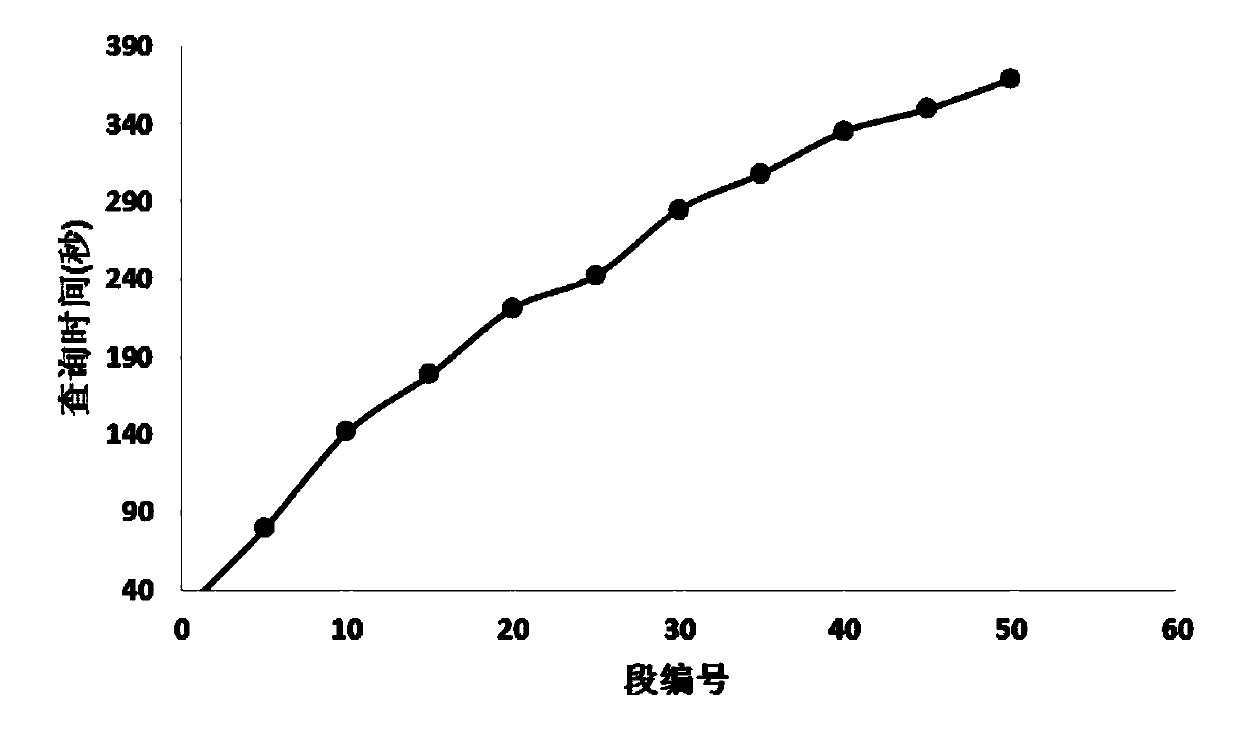
[0049] Step 1. Divide the data to be queried into data segments according to the data volume, and ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More