

Data acquisition method and device based on Spark computing framework
A computing framework and data acquisition technology, applied in the computer field, can solve problems such as insufficient performance of JdbcRDD functions, affecting spark data import performance, etc., to achieve the effect of improving data import performance, reducing data transmission overhead, and improving computing performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0023] The present invention will be described in further detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present invention, not to limit the present invention.
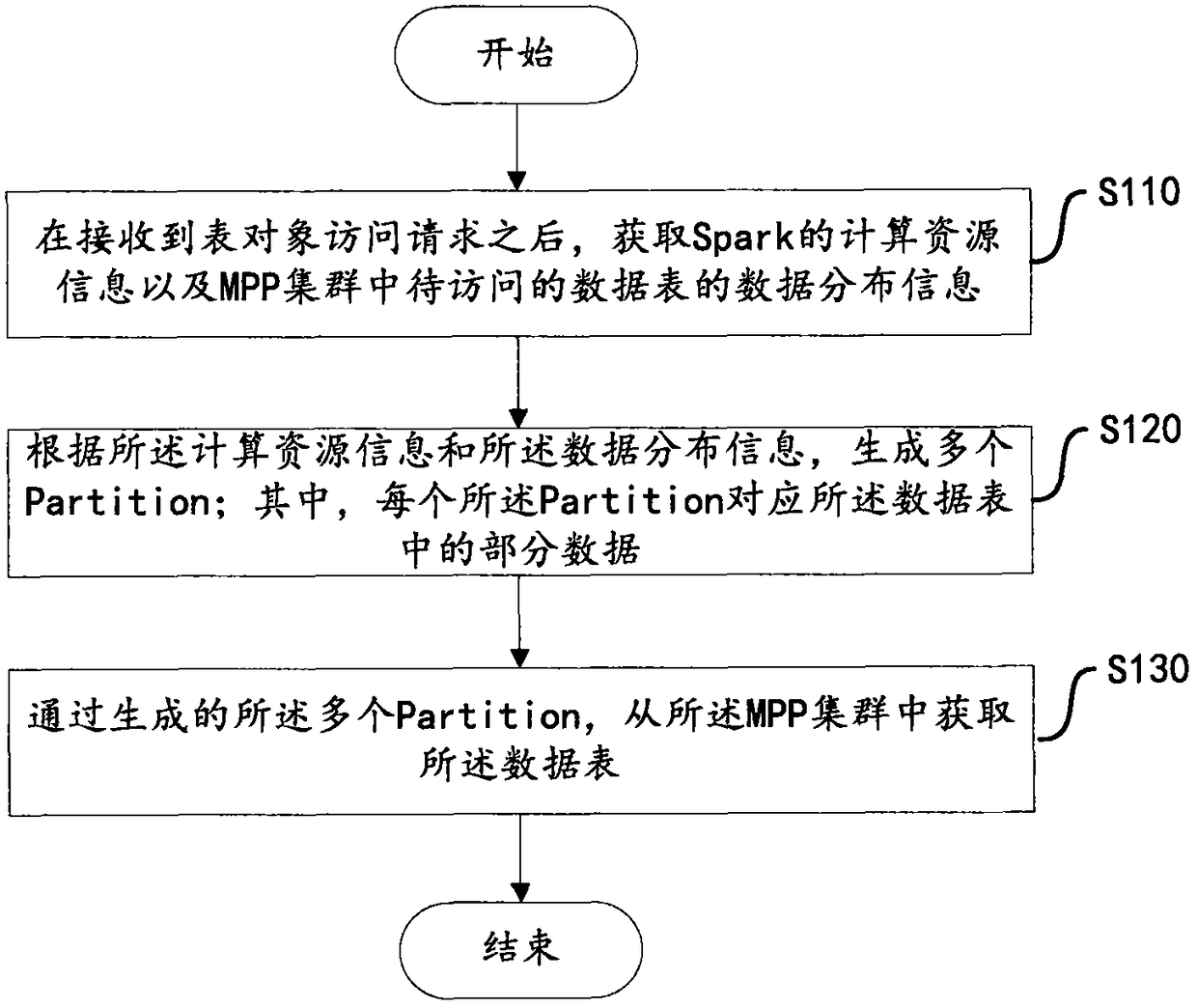
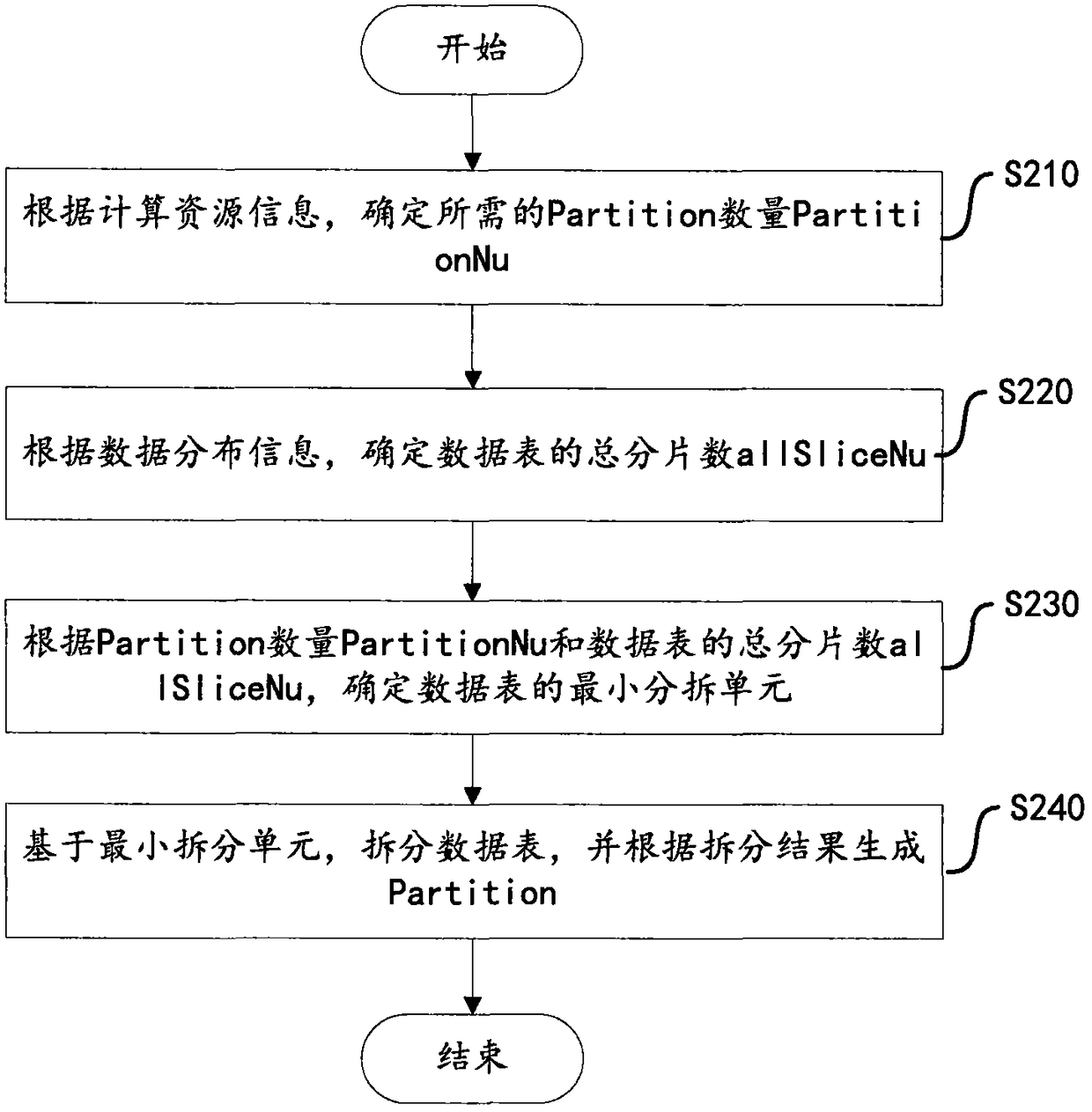
[0024] This embodiment provides a data acquisition method based on the Spark computing framework. This embodiment is executed on the Spark side. like figure 1 Shown is a flowchart of a data acquisition method based on the Spark computing framework according to an embodiment of the present invention.
[0025] Step S110, after receiving the table object access request, obtain the computing resource information of Spark and the data distribution information of the data tables to be accessed in the MPP cluster (also called MPP database cluster).
[0026] The table object access request is used to request to access the data tables stored in the MPP cluster. According to the table object access ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More