

Data distribution method and device based on MapReduce as well as computer readable storage medium
A technology of data distribution and to-be-distributed, which is applied in the field of big data processing in the field of Internet information technology, and can solve the problems of small data volume, affecting job completion time, partition processing time and long partition processing time, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

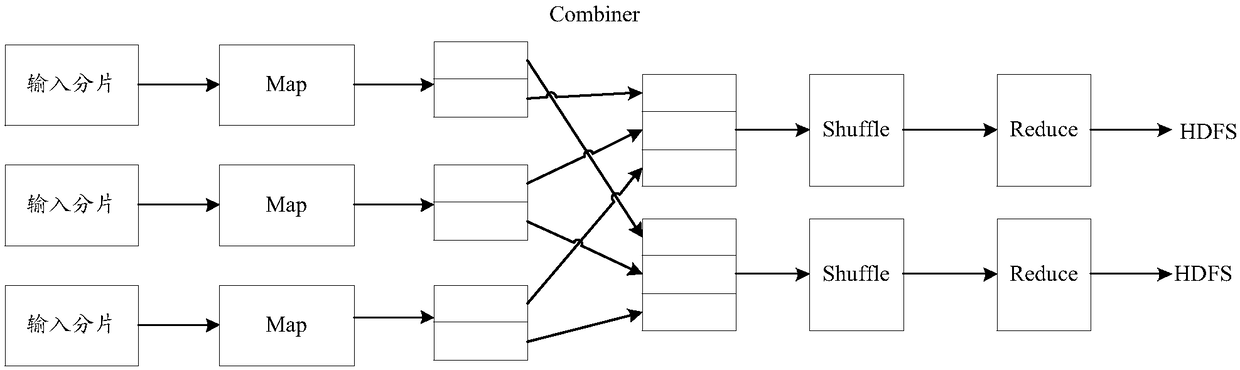
Examples
Embodiment 1
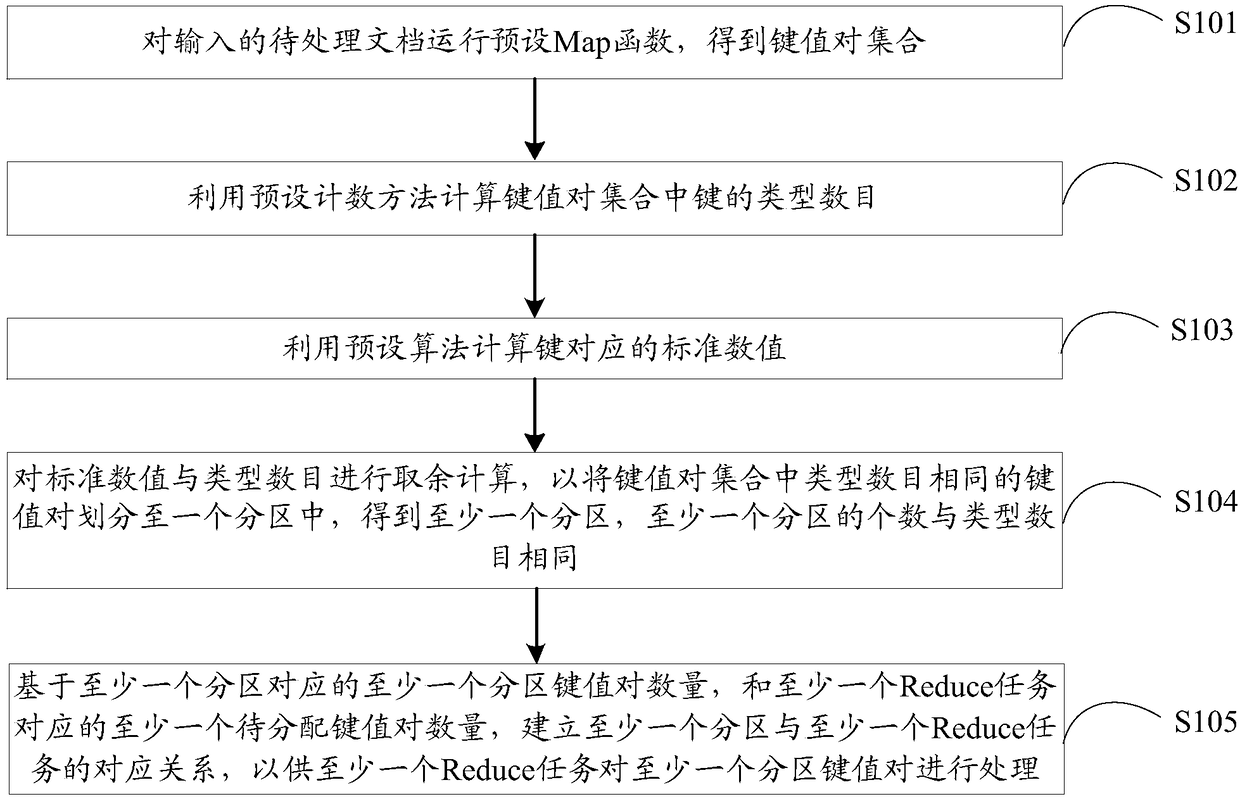
[0055] The embodiment of the present invention provides a data allocation method based on MapReduce, such as figure 2 As shown, the method may include:
[0056] S101. Execute a preset Map function on the input document to be processed to obtain a set of key-value pairs.
[0057] The data allocation method provided by the embodiment of the present invention is applicable to the scenario where the partitoner operation is used to perform data partitioning when the MapReduce computing model is used to process large data.
[0058] In the embodiment of the present invention, MapReduce calculates input slices according to the documents to be processed, and each input slice corresponds to a map task, and map processes the input slices according to the map() method (preset Map function) to obtain a set of key-value pairs .
[0059] In the embodiment of the present invention, the storage format of the key-value pair is , where key is a key and value is a value.
[0060] S102. Calcul...
Embodiment 2
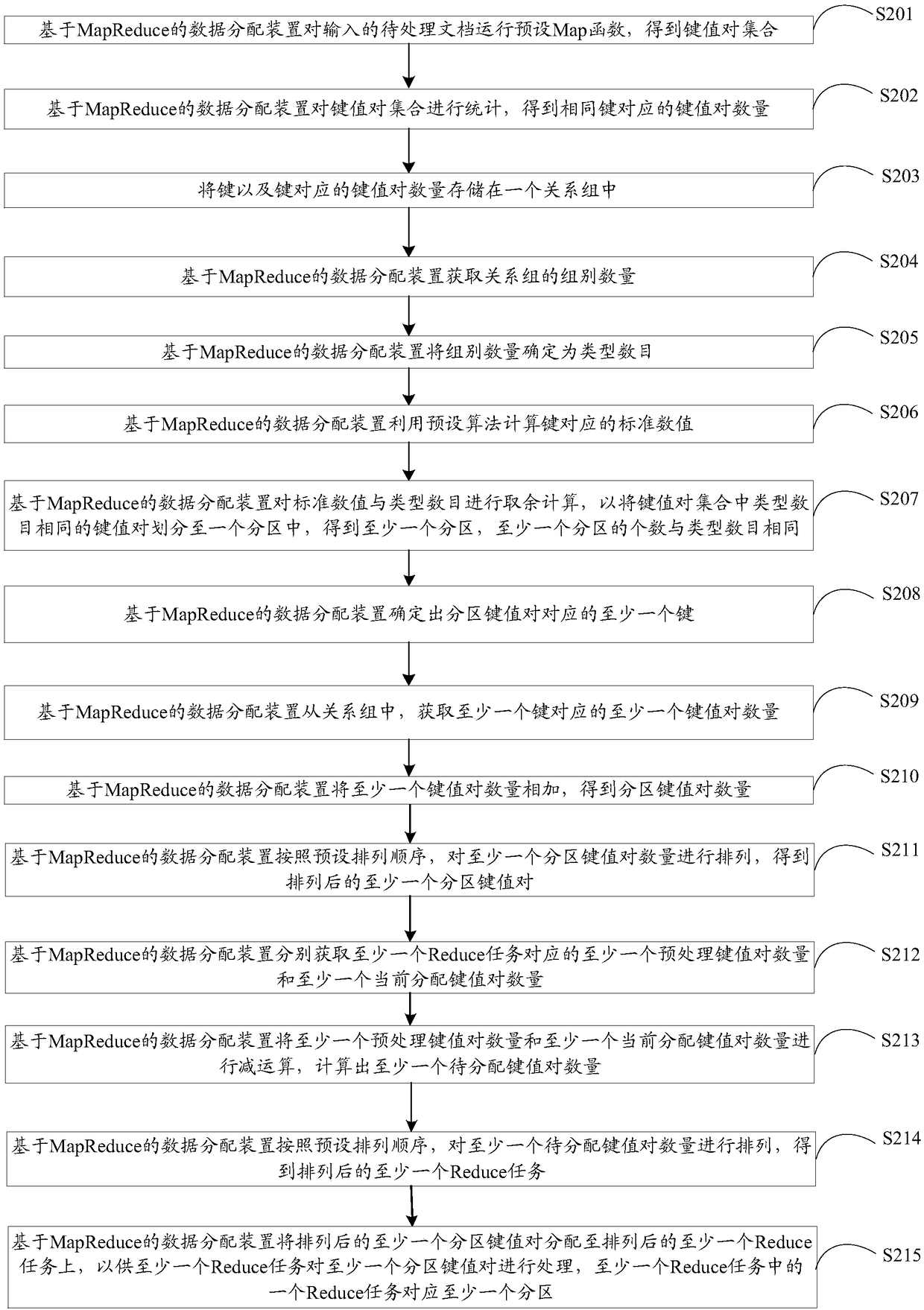
[0095] The embodiment of the present invention provides a data allocation method based on MapReduce, such as image 3 As shown, the method may include:
[0096] S201. The MapReduce-based data distribution device runs a preset Map function on an input document to be processed to obtain a set of key-value pairs.
[0097] The data allocation method provided by the embodiment of the present invention is applicable to the scenario where the partitoner operation is used to perform data partitioning when the MapReduce computing model is used to process large data.
[0098] In the embodiment of the present invention, MapReduce calculates input slices according to the documents to be processed, and each input slice corresponds to a map task, and map processes the input slices according to the map() method (preset Map function) to obtain a set of key-value pairs , map uses the count() method to count the set of key-value pairs to obtain the number of key-value pairs corresponding to th...
Embodiment 3
[0173] Figure 4 Schematic diagram of the composition and structure of the MapReduce-based data distribution device proposed for the embodiment of the present invention Figure 1 , in practical application, based on the same inventive concept of Embodiment 1 to Embodiment 2, such as Figure 4 As shown, the MapReduce-based data distribution device 1 of the embodiment of the present invention includes: a processor 10 , a memory 11 and a communication bus 12 . In the process of a specific embodiment, the above-mentioned processor 10 may be an application-specific integrated circuit (ASIC, Application Specific Integrated Circuit), a digital signal processor (DSP, Digital Signal Processor), a digital signal processing device (DSPD, Digital Signal Processing Device ), a programmable logic device (PLD, Programmable Logic Device), a field programmable gate array (FPGA, Field Programmable Gate Array), a CPU, a controller, a microcontroller, and a microprocessor. It can be understood ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More