

A Verb Phrase Omission Resolution Method Based on Deep Learning
A technology of verb phrases and deep learning, which is applied in natural language data processing, instruments, biological neural network models, etc., can solve the problem of low recognition accuracy of trigger word judgment precedent phrases, and achieve the effect of improving recognition accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
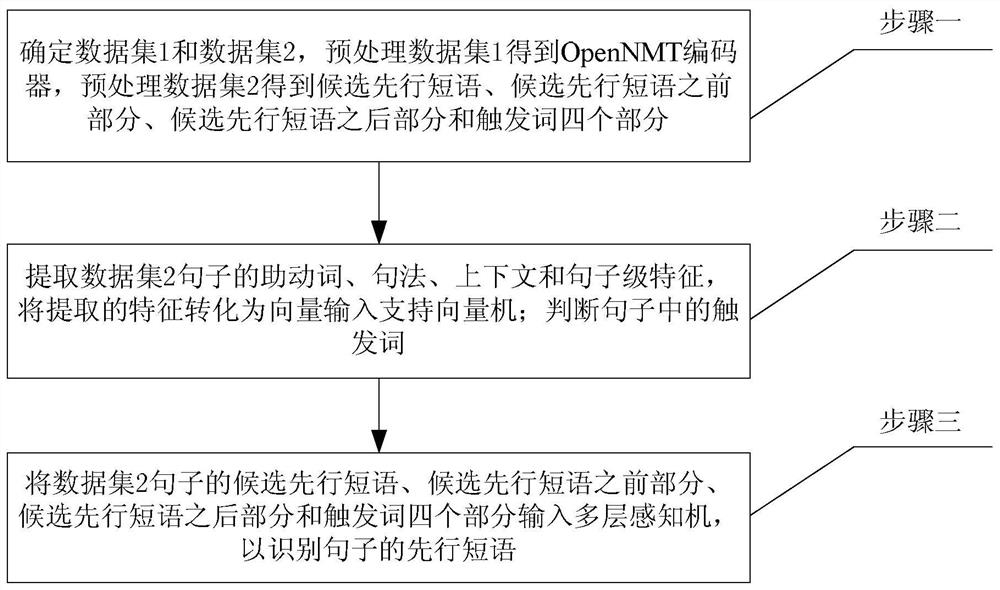
[0025] Specific implementation mode one: a kind of deep learning-based method for omitting verb phrases described in this implementation mode, the specific steps of the method are:
[0026] Step 1, determine the sentences contained in dataset 1 (Penn Treebank 2Wall Street Journal) and dataset 2 (Anannotated corpus for the analysis of VP ellipsis By Johan Bos and JenniferSpenader);
[0027] When preprocessing the sentences in dataset 1, the OpenNMT encoder is obtained;
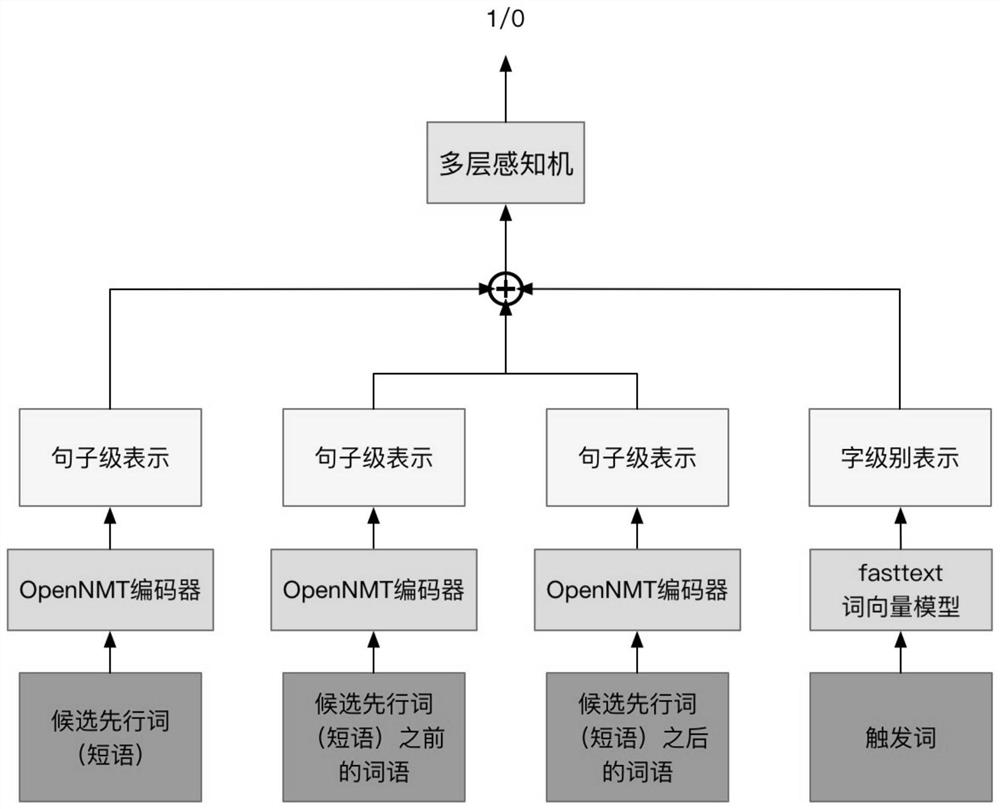
[0028] When preprocessing the sentences in Dataset 2, the verb phrases and adjective phrases in each sentence are used as the candidate antecedent phrases of the sentence in turn, and the sentence is correspondingly divided into candidate antecedent phrases, candidate antecedent phrases, candidate antecedent phrases, and candidate antecedent phrases. Four parts after the phrase and the trigger word;
[0029] Step 2, extract the auxiliary verb features, syntactic features, context features and sentence-level fe...
specific Embodiment approach 2
[0053] Specific embodiment 2: This embodiment further defines a method for ellipsis and resolution of verb phrases based on deep learning described in Embodiment 1. The data set 2 in step 1 (An annotated corpus for the analysis of VP ellipsis By Johan Bos and Jennifer Spenader) are annotated by JohanBos and Jennifer Spenader to provide antecedent phrases and trigger words, and the sentences in Dataset 2 all have verb phrase omissions.
[0054] The sentences in the data set 2 in this embodiment all have verb phrase omissions, which are used to train the trigger word judgment model in step 2 and the preceding phrase recognition model in step 3. Among them, Johan Bos and Jennifer Spenader are the names of the authors of the English literature (An annotated corpus for the analysis of VP ellipsis ByJohan Bos and Jennifer Spenader) from Dataset 2.
specific Embodiment approach 3
[0055] Specific Embodiment 3: This embodiment further limits the method of verb phrase omission and resolution based on deep learning described in Embodiment 2. The steps in this embodiment perform preprocessing on Dataset 1 and Dataset 2. The process is:
[0056] Use word_tokenize in the NLTK tool to segment the sentences in dataset 1; use OpenNMT-py to train the results of word segmentation in dataset 1 to obtain the OpenNMT encoder;
[0057] The OpenNMT encoder has two outputs, one of which outputs the hidden layer state output corresponding to the last word, and the other output is the hidden layer state output corresponding to each word;
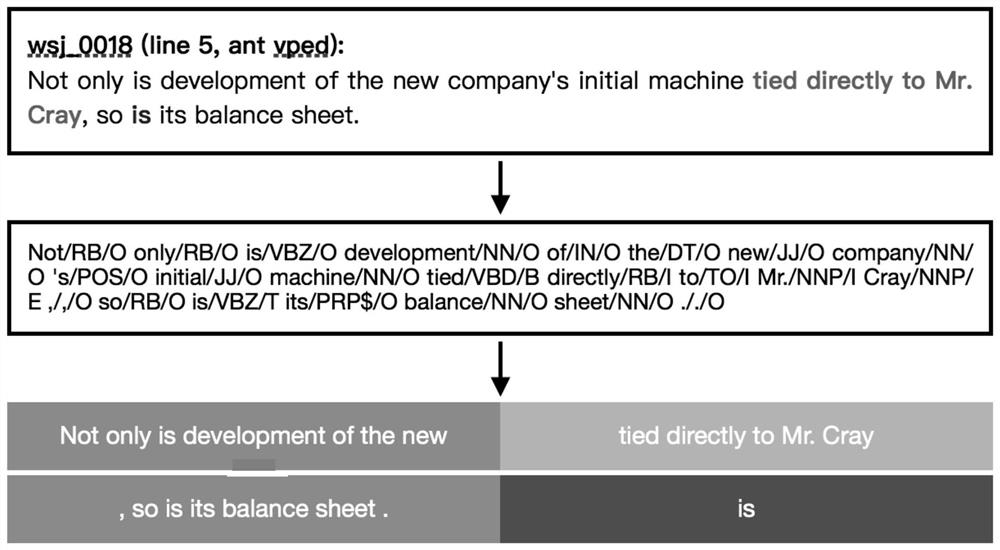
[0058] Extract the dataset 2 labeled by Johan Bos and Jennifer Spenader, use BIOEST to label each sentence in the extracted dataset 2, and divide each labeled sentence into antecedent phrase, part before the antecedent phrase, part after the antecedent phrase, and trigger The four parts of the word, the antecedent phrase, the part befo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More