

Parallel Reasoning Algorithm for Streaming RDF Data Based on Spark Streaming
A data and algorithm technology, applied in the field of massive streaming RDF data reasoning, can solve the problems of low efficiency, inapplicability, and high consumption of pseudo-two-way network communication, and achieve the effect of ensuring completeness, reducing the number of tasks, and quickly reading
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
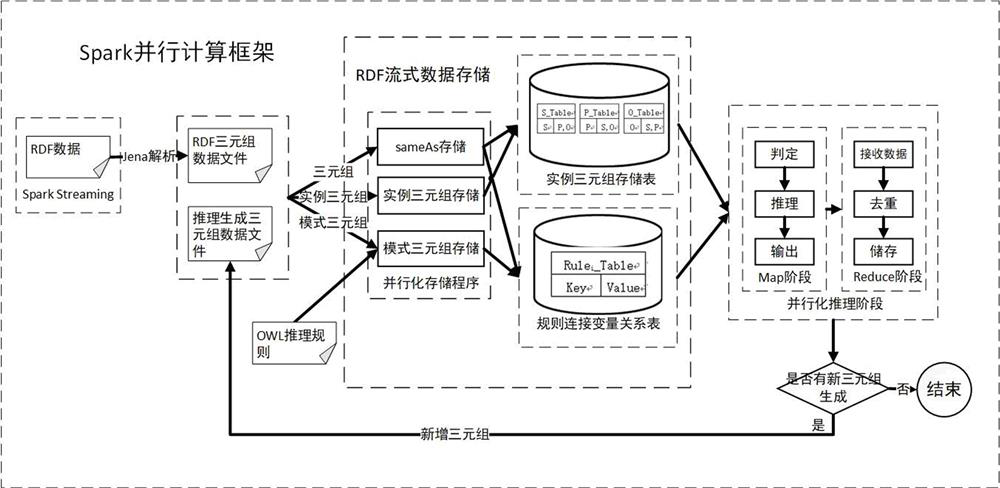
[0036] The technical solution of the present invention will be specifically described below in conjunction with the accompanying drawings.
[0037] The present invention provides a parallel reasoning algorithm for streaming RDF data based on Spark Streaming, comprising the following steps:
[0038] Step S1, combined with OWL Horst inference rules, constructing the corresponding rule-connected variable relationship table; in the iterative parallel inference stage, the batch new data in the Streaming data stream and the data generated by the previous inference are regularly obtained as input data, and the input pattern data and The instance data is sorted and stored in the corresponding Redis cluster;
[0039] Step S2, connect the variable relationship table according to the rules, determine the rules that can be activated in this reasoning, and combine the corresponding instance data to generate reasoning data;
[0040] Step S3, delete and store the duplicate data generated in...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More