

High-dimensional data feature selection method based on filtering method and genetic algorithm
A feature selection method and genetic algorithm technology, applied in the field of data mining, can solve the problems of high probability of deleting useful features, inappropriate high-dimensional, small sample data, etc., and achieve the effect of high computational cost and high accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


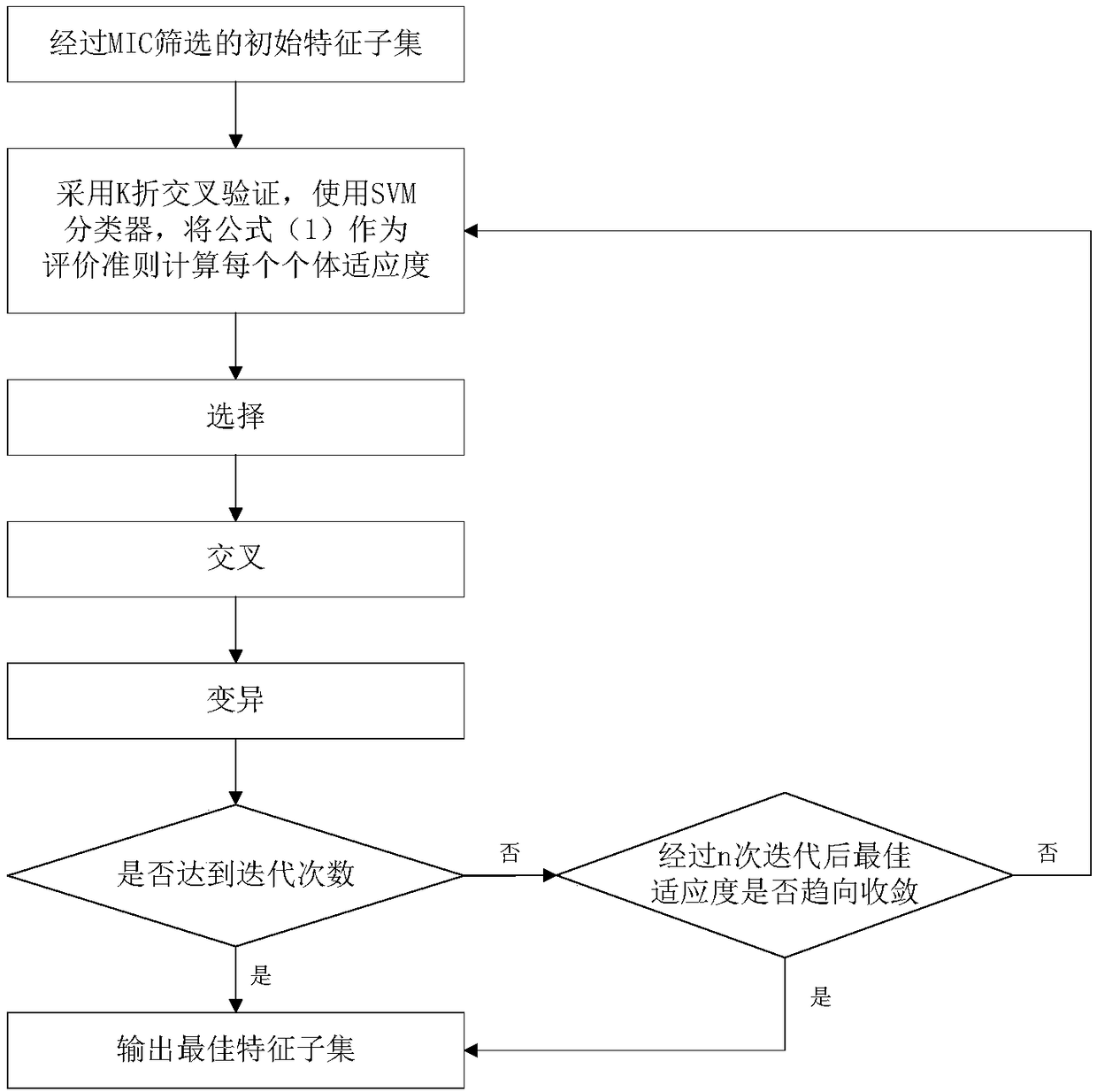
Examples
Embodiment Construction
[0023] For the parts that are not described in detail in this embodiment, please refer to the description of the summary of the invention.
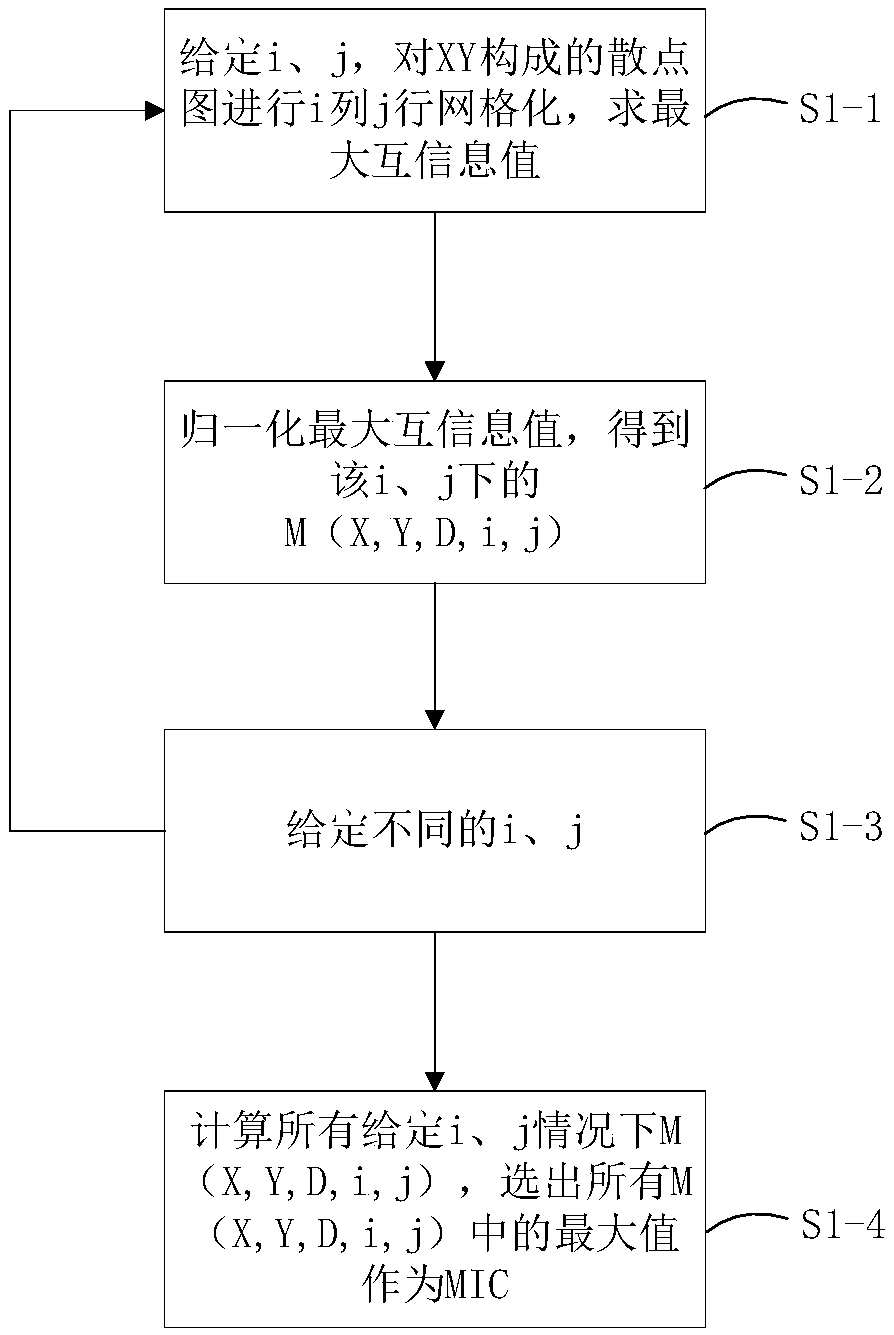
[0024] like figure 1 As shown, a high-dimensional data feature selection method based on filtering method and genetic algorithm, the specific steps are as follows:
[0025] Step 1. Input the data set Gastric1, the number of samples is 144, and the number of features is 22283, of which the number of non-cardia gastric cancer samples is 72, and the number of normal samples is 72. Gastric1 (accession: GSE29272) was downloaded in the NCBI GeneExpression Omnibus (GEO) database.
[0026] Step 2, using the maximum information coefficient (MIC) to calculate the correlation between each gene expression profile feature and the class label. First, a column of gene expression profile features is recorded as a vector X, and a column of class labels is recorded as a vector Y, and an x scalar in X corresponds to a y scalar in Y to form a sample. Co...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More