

Data synchronization method, apparatus, storage medium, and electronic apparatus
A data synchronization and data storage space technology, applied in the computer field, can solve the problems of cumbersome and incremental synchronization tools not working properly, and achieve the effects of avoiding loss, simplifying the data synchronization process, and ensuring accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

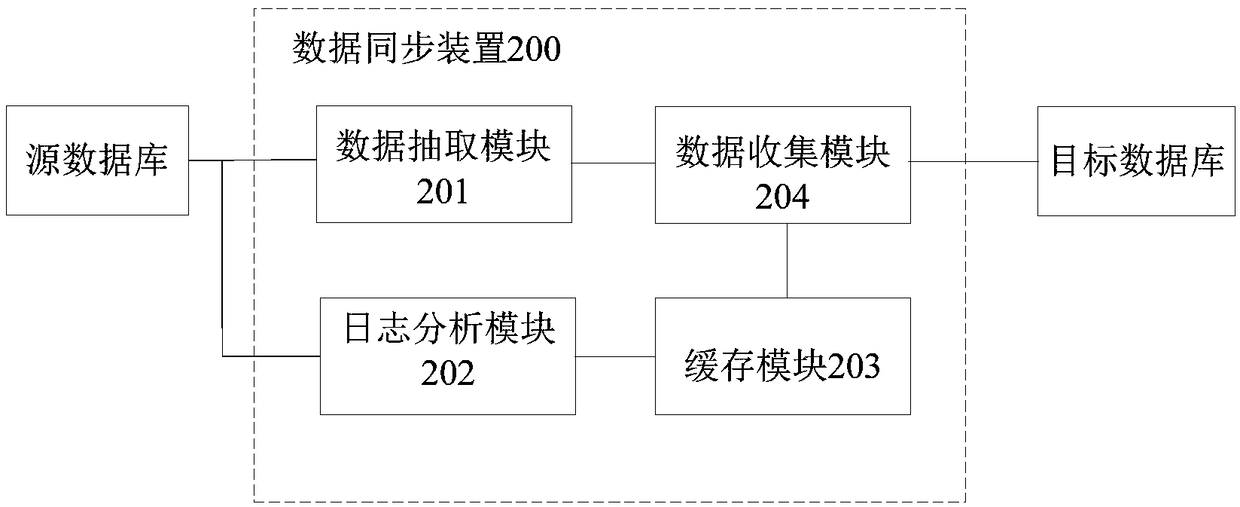
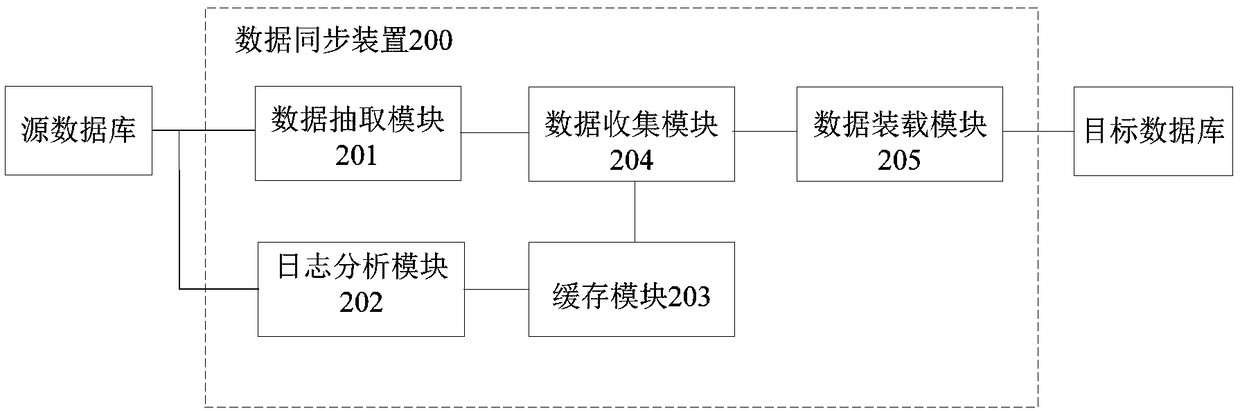
Examples
Embodiment Construction
[0071] Specific embodiments of the present disclosure will be described in detail below in conjunction with the accompanying drawings. It should be understood that the specific embodiments described here are only used to illustrate and explain the present disclosure, and are not intended to limit the present disclosure.
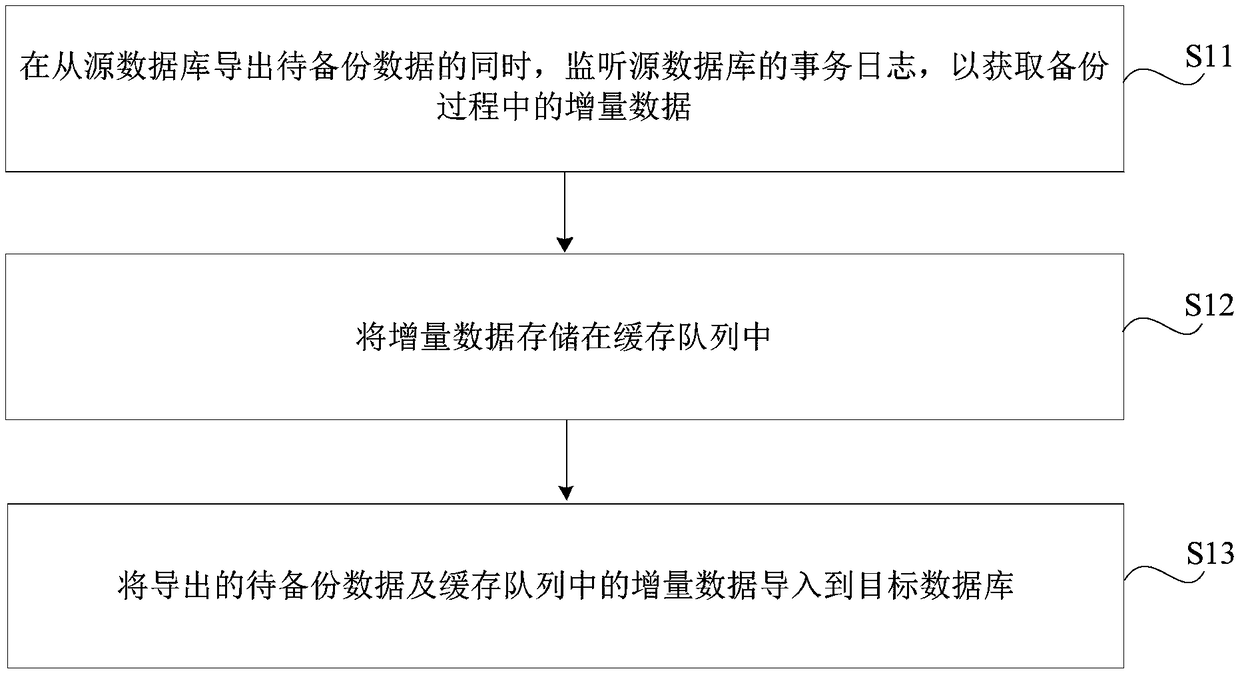
[0072] figure 1 is a flowchart of a data synchronization method shown according to an exemplary embodiment, such as figure 1 As shown, the data synchronization method can be applied to a computer, and includes the following steps.
[0073] Step S11: While exporting the data to be backed up from the source database, monitor the transaction log of the source database to obtain incremental data during the backup process.
[0074] Step S12: Store the incremental data in the cache queue.
[0075] Step S13: Import the exported data to be backed up and the incremental data in the cache queue to the target database.
[0076] The data stored in the database (inclu...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More