

A high-performance audio and video automatic sentence segmentation method and system
An audio and video, high-performance technology, applied in the field of high-performance audio and video automatic sentence segmentation method and system, can solve the problems of increasing time cost and labor cost, dislocation of start point and end point, slow speed of dictation, etc., and achieve saving Time cost and labor cost, eliminate the influence of noise or background sound, and improve processing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
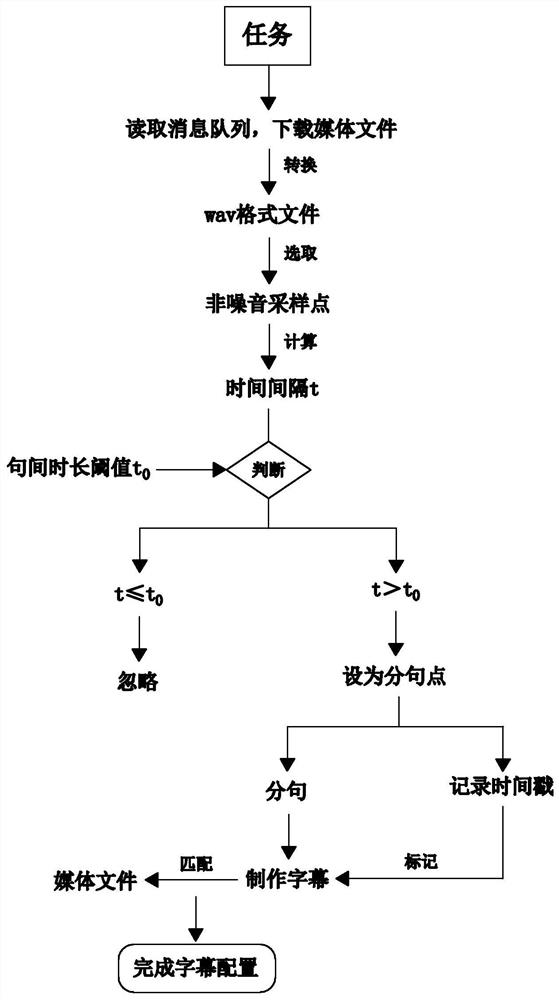
[0044] like figure 1 As shown, embodiment 1 of the present invention provides a kind of high-performance audio-video automatic sentence segmentation method, comprises the following steps:
[0045] S1: Read the message to be processed from the MNS message queue, and the working thread in the MNS downloads the corresponding media file according to the queue task, and converts it into a wav format file;
[0046] S2: Set a sentence duration threshold t 0, randomly select multiple non-noise sampling points from the wav format file, and calculate the time interval t between adjacent non-noise sampling points; when t>t 0 When , the previous non-noise sampling point is set as a period, and the timestamp of the period is recorded, and the interval between two adjacent periods is an independent clause;
[0047] S3: Make subtitles matching the wav format file, and segment and mark the subtitles according to the timestamp; match the segmented subtitles with the media file according to t...
Embodiment 2
[0051] Embodiment 2 discloses a high-performance audio-video automatic sentence segmentation method on the basis of Embodiment 1. This Embodiment 2 further defines that in step S1, the MNS message queue includes an input channel and at least two output channels, and the output channel It is the consumption process or the consumption thread of the task message, the consumption process==the number of CPUs, and the consumption thread==the number of CPUs.
[0052] The number of consumption processes or consumption threads is automatically set according to the number of server CPUs before startup. Generally, the default is the same as the number of CPUs to ensure that multiple consumption processes or consumption threads run at the same time without conflicts or conflicts. There will be idle resources.
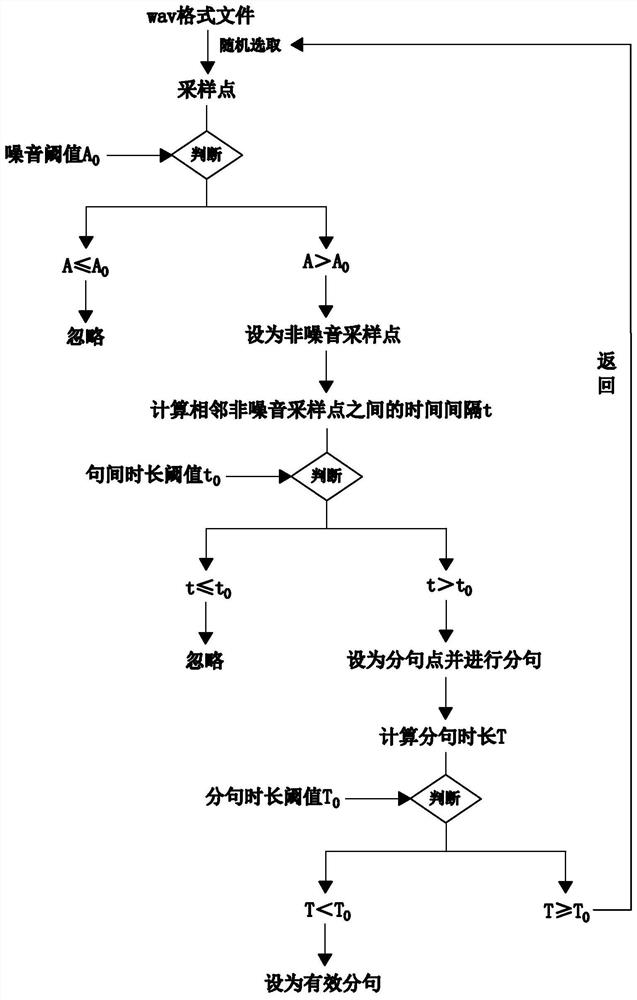
[0053] Such as figure 2 As shown, the specific method of step S2 is as follows:
[0054] S2.1: Set an amplitude threshold as the noise threshold A 0 , randomly select multiple ...
Embodiment 3
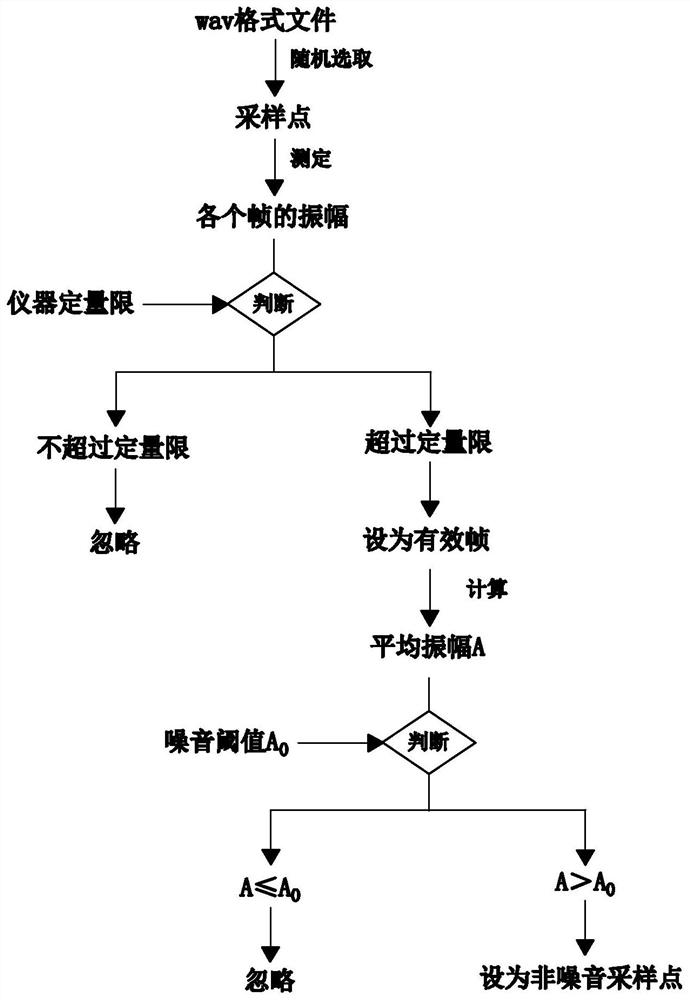
[0062] Embodiment 3 discloses a high-performance audio-video automatic sentence segmentation method on the basis of Embodiment 1. This embodiment 3 further defines the sampling point as a continuous frame, and the number of frames of each sampling point is equal. At this time In order to ensure that the data is valid and reliable, the amplitude A is the maximum amplitude of all valid frames in the sampling point, t is the time interval between the last frame of the previous sampling point and the first frame of the subsequent sampling point, and T is the preceding period The duration between the last frame of and the first frame after the period, and the timestamp is the time point of the last frame of the period.
[0063] Such as image 3 As shown, based on the above premise, the specific method of step S2.1 is as follows:
[0064] S2.1.1: Set an amplitude threshold as the noise threshold A 0 , randomly select a plurality of sampling points from the wav format file;
[006...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More