

A method and device for deduplication of big data
A big data and data technology, applied in the field of big data deduplication methods and devices, can solve problems such as poor accuracy, information pollution, data redundancy, etc., and achieve the effect of high deduplication accuracy, good versatility, and high precision
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
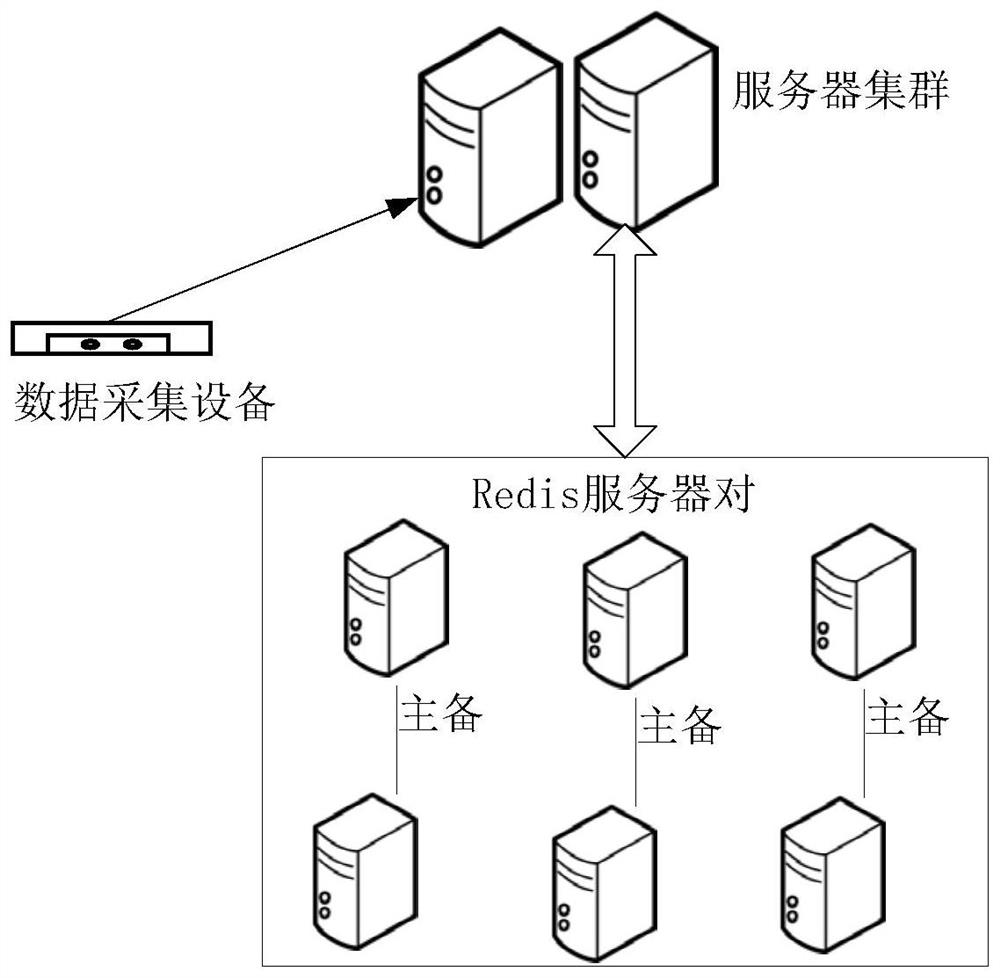
[0049] An embodiment of the present invention provides a large data deduplication method. see figure 1, the network architecture based on the method includes data acquisition equipment, server clusters and Redis server pairs. Wherein, the data collection device is used to collect data to be deduplicated, and upload the data to be deduplicated to the server cluster. The server cluster includes multiple servers, and the execution subject of the embodiment of the present invention is the server, and the deduplication work is distributed to different nodes in the cluster environment as much as possible through the server cluster, so as to obtain the maximum calculation amount. Multiple groups of Redis server pairs are set in the embodiment of the present invention, and each Redis server pair includes a Redis master server and a Redis backup server, stores the intermediate data in the large data deduplication process by the Redis server pair, and passes through the master server p...
Embodiment 2
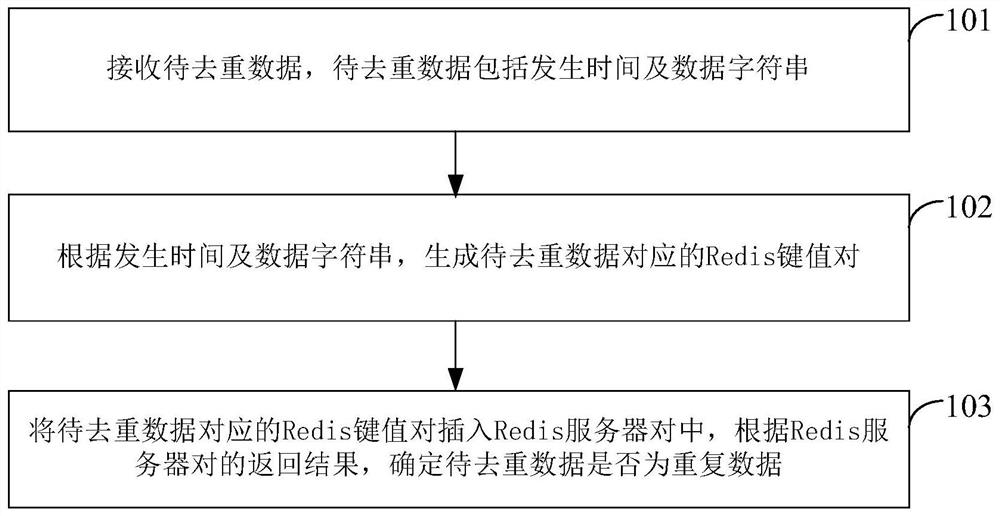
[0098] see Figure 5 , the embodiment of the present invention provides a big data deduplication device, which is used to implement the big data deduplication method provided in the above-mentioned embodiment 1, and the device includes:
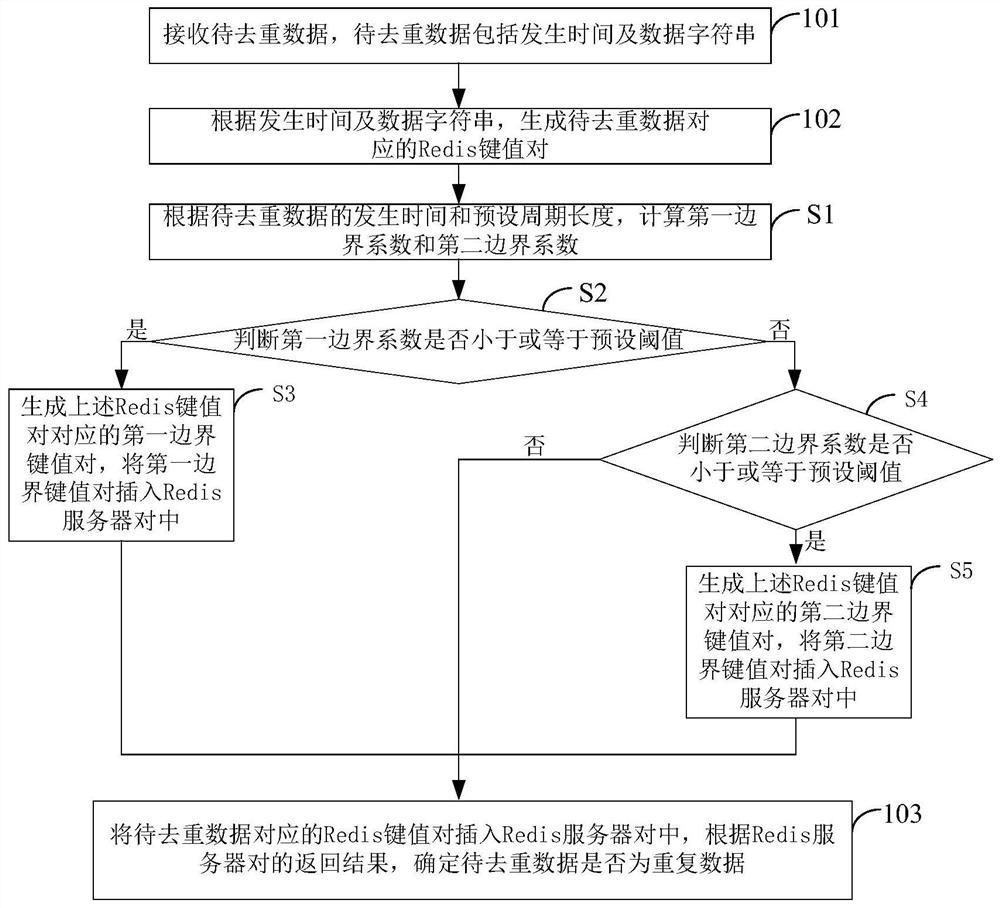
[0099] The receiving module 20 is used to receive data to be deduplicated, and the data to be deduplicated includes occurrence time and data string;
[0100] Generating module 21 is used for generating the Redis key-value pair corresponding to the data to be deduplicated according to the time of occurrence and the data string;
[0101] The determination module 22 is configured to insert the Redis key-value pair into the Redis server pair, and determine whether the data to be deduplicated is duplicate data according to the return result of the Redis server pair.
[0102] Above-mentioned generation module 21 comprises:
[0103] The generation unit is used to generate the Redis key corresponding to the data to be deduplicated according to the ...
Embodiment 3
[0111] An embodiment of the present invention provides a large data deduplication device, the device includes one or more processors, and one or more storage devices, one or more programs are stored in the one or more storage devices, the When the one or more programs are loaded and executed by the one or more processors, the method for deduplication of big data provided in Embodiment 1 above is implemented.
[0112] In the embodiment of the present invention, deduplication of big data is performed through server clusters, and data operations are distributed to different nodes in the cluster environment as much as possible. In addition, Redis, a key-value pair database with high concurrent access, is used for deduplication, which ensures that the deduplication operation occupies the minimum system resources from the perspective of space and time. By extending the occurrence time of the data to be deduplicated to multiple adjacent times, it can effectively filter out approximat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More