

A method and system for quickly retrieving changing data segments from massive data
A technology of massive data and changing data, applied in the field of data processing, can solve the problem of large global search workload and other problems
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
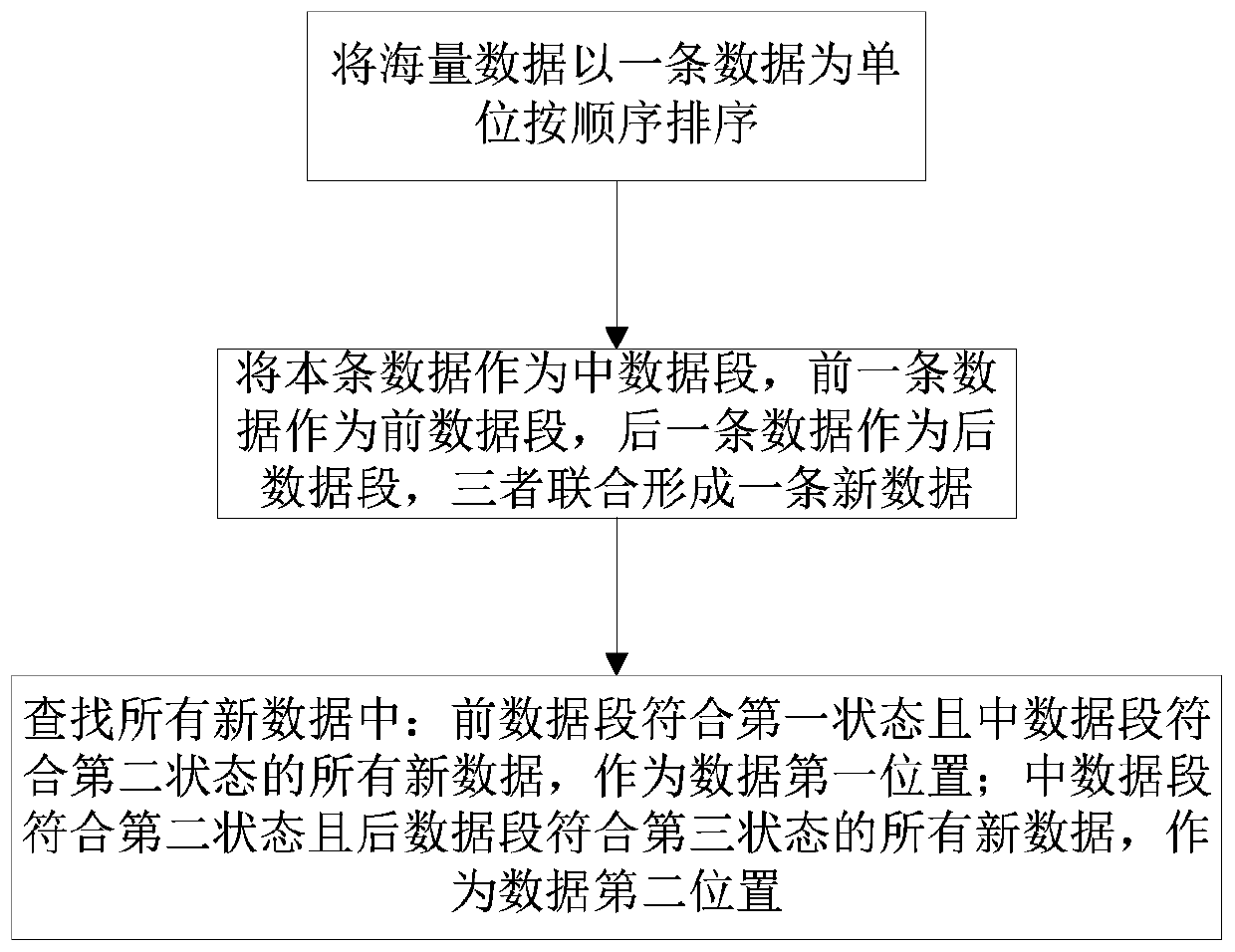
[0030] The method for quickly retrieving changing data segments from massive data of the present invention comprises the following steps:
[0031] S1: Sort massive data in order by one piece of data;
[0032] S2: Use this data as the middle data segment, the previous data as the previous data segment, and the latter data as the latter data segment, and the three combine to form a new data segment;
[0033] S3: Find all the new data: all new data in which the former data segment conforms to the first state and the middle data segment conforms to the second state, as the first position of the data, numbered in sequence (the first item is numbered 1, and the second item is numbered as 2, and so on), to get all new data sets in the first position of the data; all new data in which the middle data segment conforms to the second state and the subsequent data segment conforms to the third state, as the second position of the data, numbered in sequence (1st bar is numbered 1, bar 2 i...
Embodiment 2
[0037] In this embodiment, the method for quickly retrieving changing data segments from massive data includes the following steps:
[0038] In this embodiment, a data record (hereinafter referred to as a record) is used for illustration. A data record data includes data items such as serial number id, time time, state state, and value. In this embodiment, similar SQL statements are used to represent algorithm implementation.
[0039] 1. After sorting the records in order, for each record, combine its own data (denoted as S) with the previous 1 data (denoted as P) and the next 1 data (denoted as N) to form a new record. For The data P before the first item is empty; the data N after the last item is empty.
[0040] Combine each record with previous and subsequent records to get a new record jointData:
[0041] select id,value,state,lag(value,1)over(order by time)as pValue,lag(state,1)over(order by time)as pState,lead(value,1)over(order by time)asnValue ,lead(state,1)over(or...
Embodiment 3
[0053] A system for quickly retrieving changing data segments from massive data in this embodiment includes a memory, a processor, and a computer program stored in the memory and operable on the processor. When the processor executes the computer program, any of the above-mentioned implementations can be realized. example steps.
[0054] In summary, the present invention transforms the comparison between different data records into a comparison between different data fields in a record by combining each piece of data with the previous and subsequent data, so that the jobs that originally required global search can be distributed Distributed execution on multiple nodes, quickly retrieve the start and end ranges of data changes and their data, and is also applicable to the retrieval of data with multiple data items and multi-state values.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More