

Optimization system and method for shuffling stage in Hadoop MapReduce
An optimization method and shuffling technology, which is applied in the fields of big data and cloud computing, can solve the problems of not finding instructions or reports, affecting the task completion time, and not yet collecting data, so as to shorten the data reading time and optimize the task completion time , Optimize the effect of tail delay
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0033] The following is a detailed description of the embodiments of the present invention: this embodiment is implemented on the premise of the technical solution of the present invention, and provides detailed implementation methods and specific operation processes. It should be noted that those skilled in the art can make several modifications and improvements without departing from the concept of the present invention, and these all belong to the protection scope of the present invention.
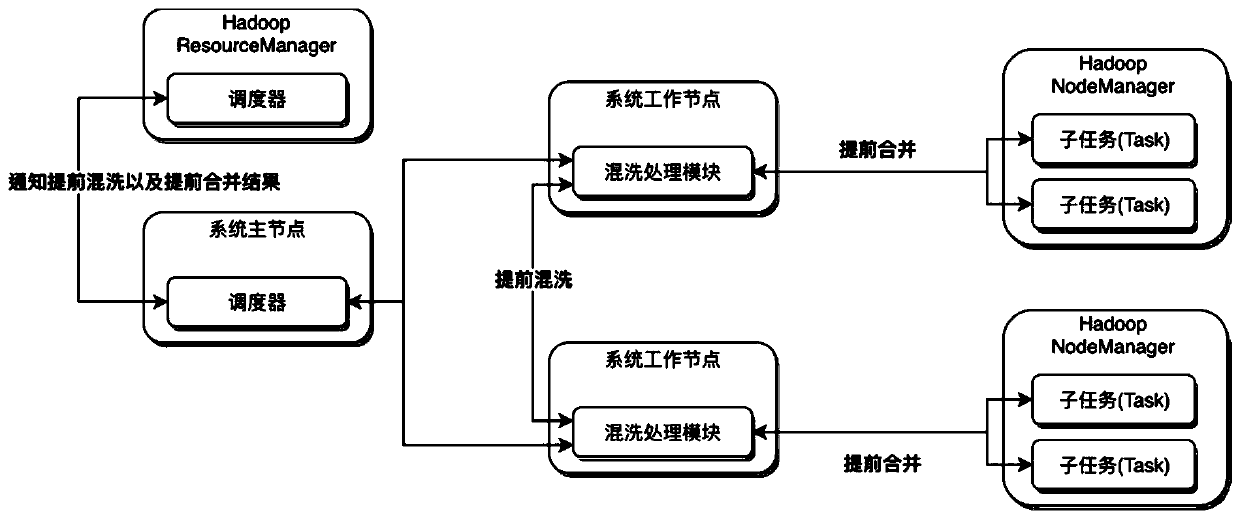
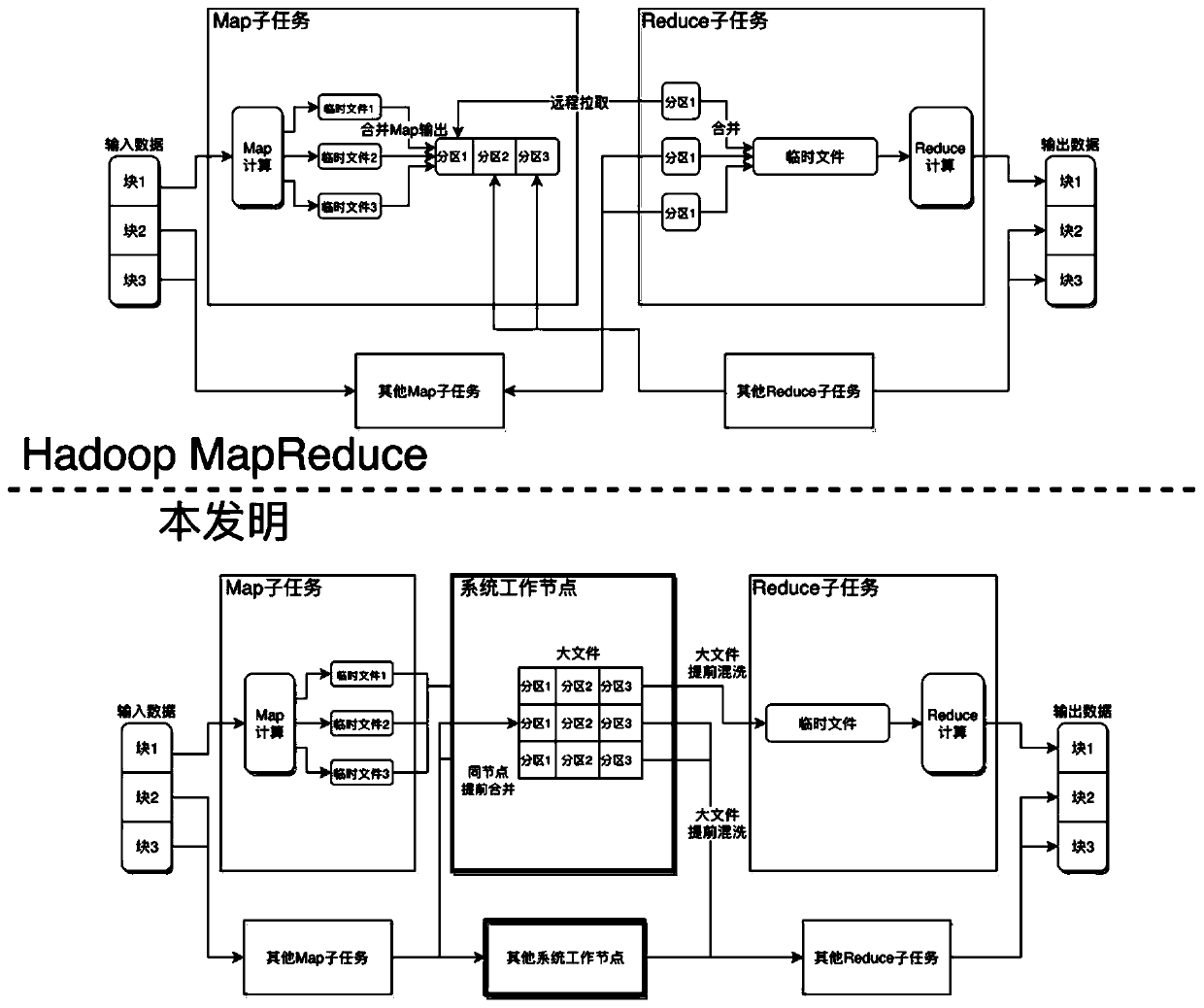
[0034] The embodiment of the present invention provides a kind of optimization system aiming at the shuffling phase in Hadoop MapReduce, including system master node and system work node; Wherein:
[0035] The main node of the system includes: a scheduler module and a communication module a, the scheduler module is used to schedule the time when partition files are merged in advance, the time for shuffling in advance, and the destination of the shuffling results; the communication module...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More