

Abnormal instance detection method and device for distributed system, equipment and medium
A distributed system and abnormal technology, applied in the computer field, can solve problems such as difficulty in achieving the accuracy of abnormal instances, and achieve the effect of improving pertinence and repairing efficiency, solving the problem of low determination efficiency, efficient and accurate positioning
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
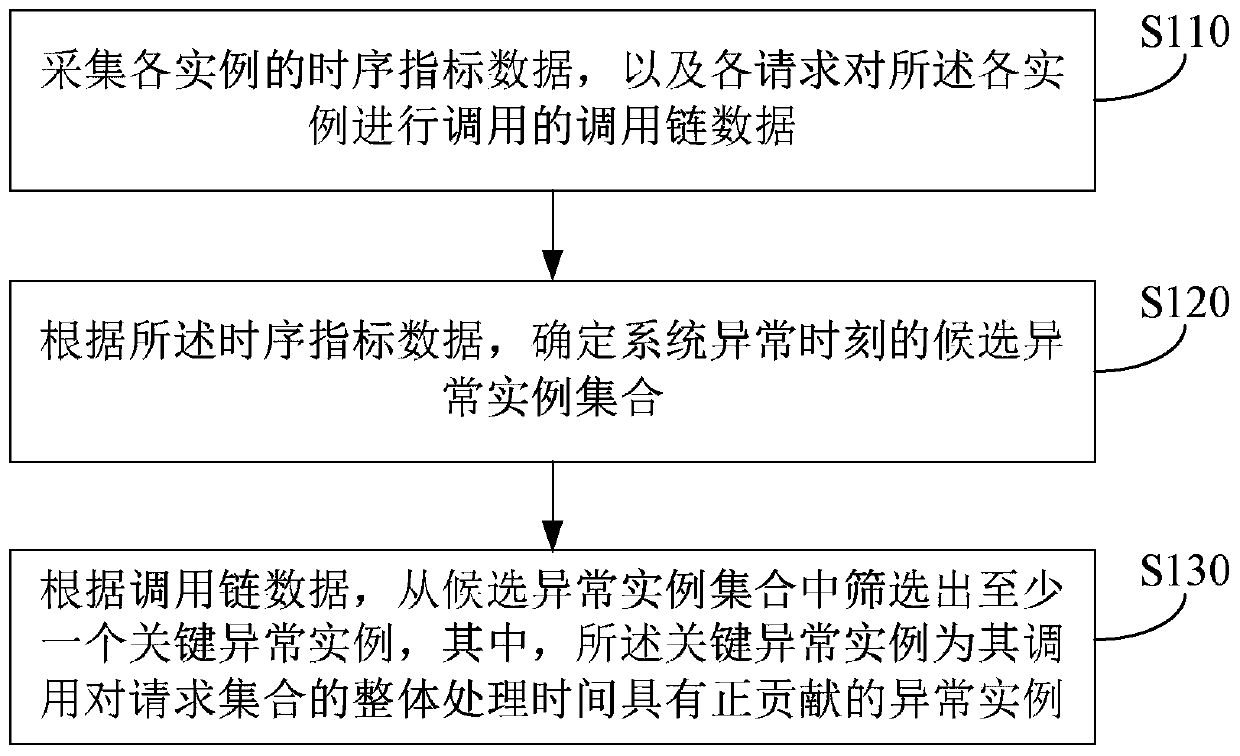
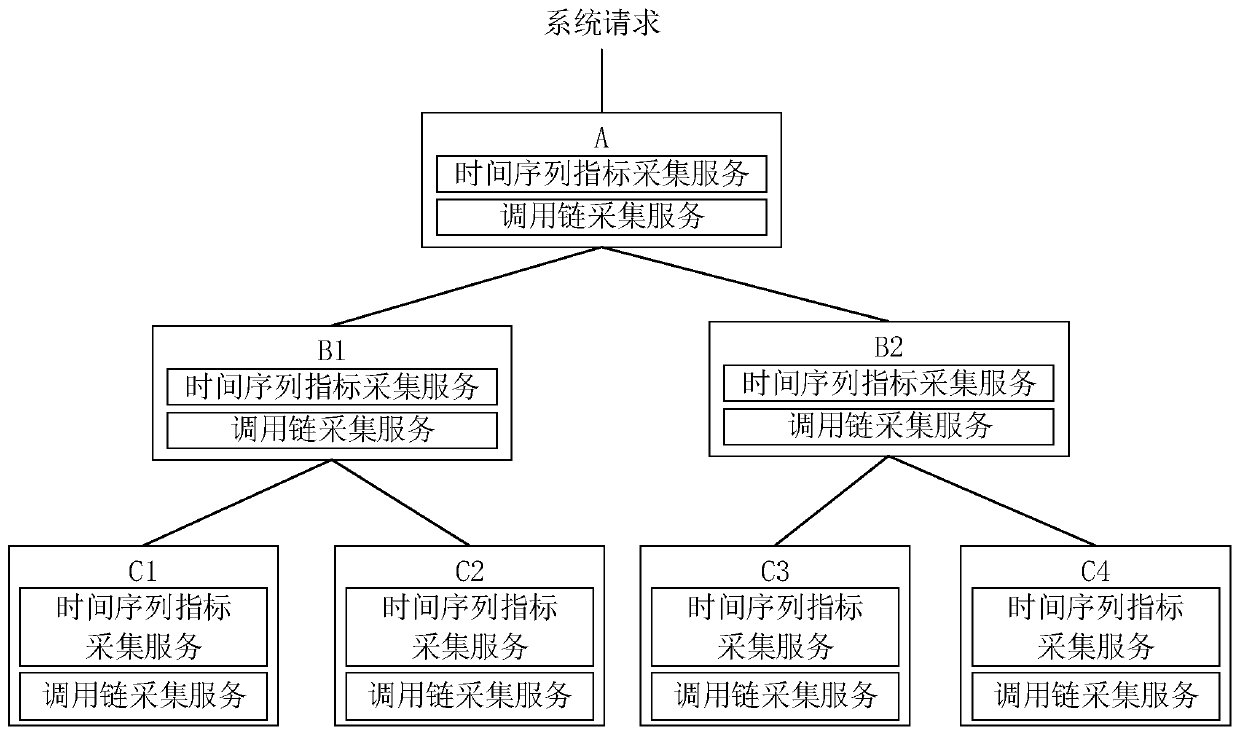
[0030] Figure 1a It is a flow chart of the abnormal instance detection method for distributed systems provided by Embodiment 1 of the present invention. This embodiment is applicable to abnormal instances in distributed systems (or distributed clusters), and requests the system as a whole according to the abnormal instances. In the case of screening due to the impact of processing time, the method can be implemented by an abnormal instance detection device for distributed systems, which can be implemented in software and / or hardware, and can be integrated in any device with computing power , including but not limited to servers, etc. The distributed system in the embodiment of the present invention includes multiple services (that is, multiple business modules), each service includes at least one instance, and different instances can process different data fragments.
[0031] like Figure 1a As shown, the abnormal instance detection method for distributed systems provided in ...
Embodiment 2
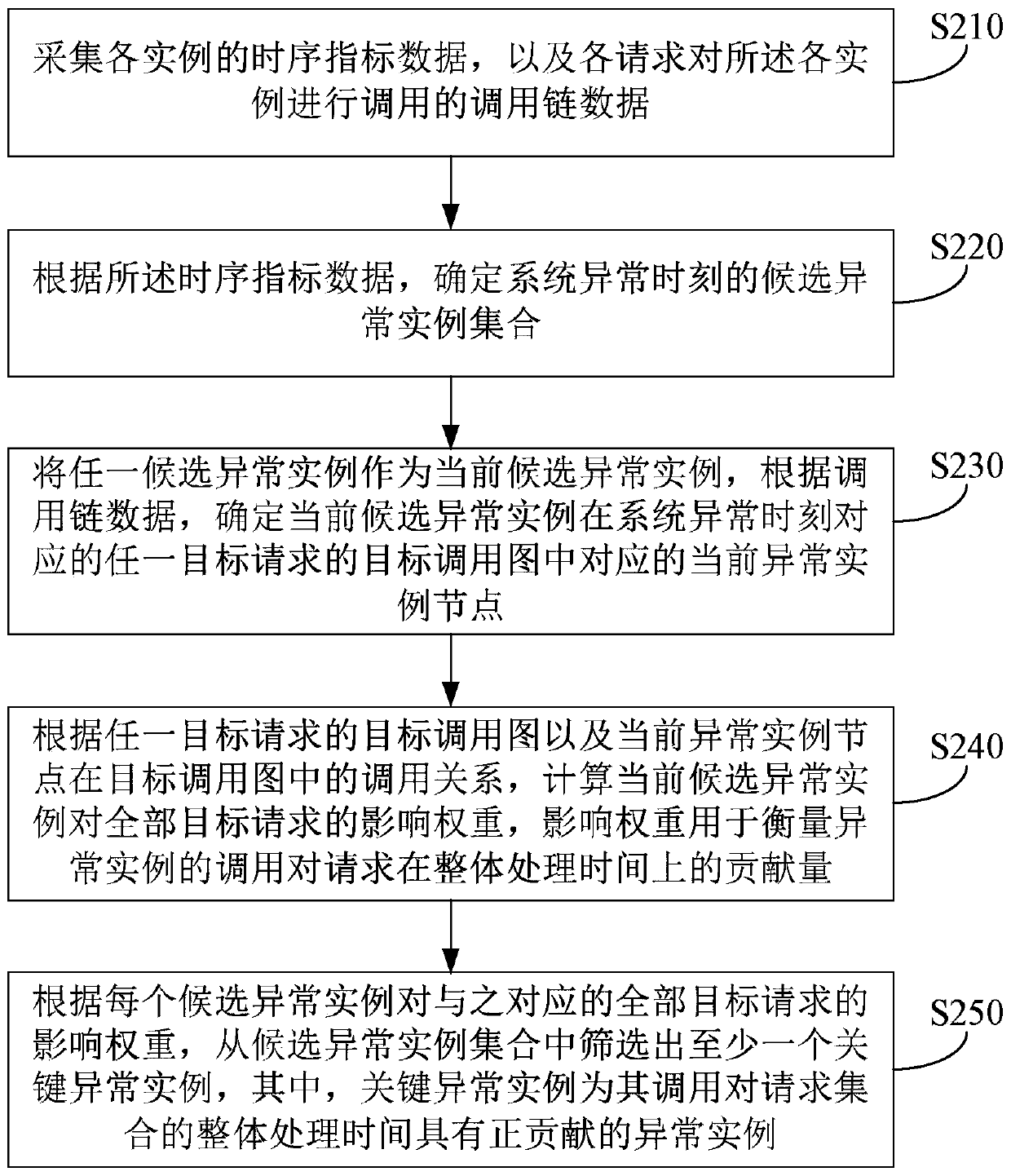
[0051] figure 2 It is a flow chart of the abnormal instance detection method for distributed systems provided by Embodiment 2 of the present invention. This embodiment further optimizes and expands on the basis of the above embodiments. Such as figure 2 As shown, the method includes:
[0052] S210. Collect timing index data of each instance, and call chain data of calls made by each request to each instance.
[0053] Among them, the call chain data includes a call chain representing the call relationship between the request and the instance and the instance and the instance. Each call chain includes at least the start timestamp and the end timestamp of the call chain. The complete call chain of each request constitutes a call graph. .
[0054] S220. According to the timing index data, determine a set of candidate abnormal instances at the time of system abnormality.
[0055] S230. Taking any candidate exception instance as the current candidate exception instance, and ac...
Embodiment 3
[0070] Figure 3a It is a flow chart of the abnormal instance detection method for distributed systems provided by Embodiment 3 of the present invention. This embodiment further optimizes and expands on the basis of the foregoing embodiments. Such as Figure 3a As shown, the method includes:
[0071] S310. Collect timing index data of each instance, and call chain data of calls made by each request to each instance.
[0072] Among them, the call chain data includes a call chain representing the call relationship between the request and the instance and the instance and the instance. Each call chain includes at least the start timestamp and the end timestamp of the call chain. The complete call chain of each request constitutes a call graph. .
[0073] S320. According to the timing index data, determine a set of candidate abnormal instances at the time of system abnormality.
[0074] S330. Using any candidate exception instance as the current candidate exception instance, d...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More