

Unbalanced data set oversampling method based on genetic algorithm and k-means clustering
A genetic algorithm and data set technology, applied in the field of computer data mining, can solve the problems of reduced prediction accuracy, model overfitting, fuzzy overlapping of sample boundaries, etc., to reduce risks, distribute evenly, and improve the recognition rate.
Pending Publication Date: 2020-01-10
NANJING UNIV OF SCI & TECH
View PDF0 Cites 11 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
The more classic sampling algorithms include SMOTE, Borderline-SMOTE, MWMOTE, etc., but these algorithms indiscriminately sample all samples based on the distance of the data samples, without considering the distribution characteristics of the positive samples, resulting in fuzzy overlapping of sample boundaries , it is easy to overfit the model, resulting in lower prediction accuracy
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples

Examples
Experimental program
Comparison scheme
Effect test
Embodiment
[0082] 1. Simulation environment
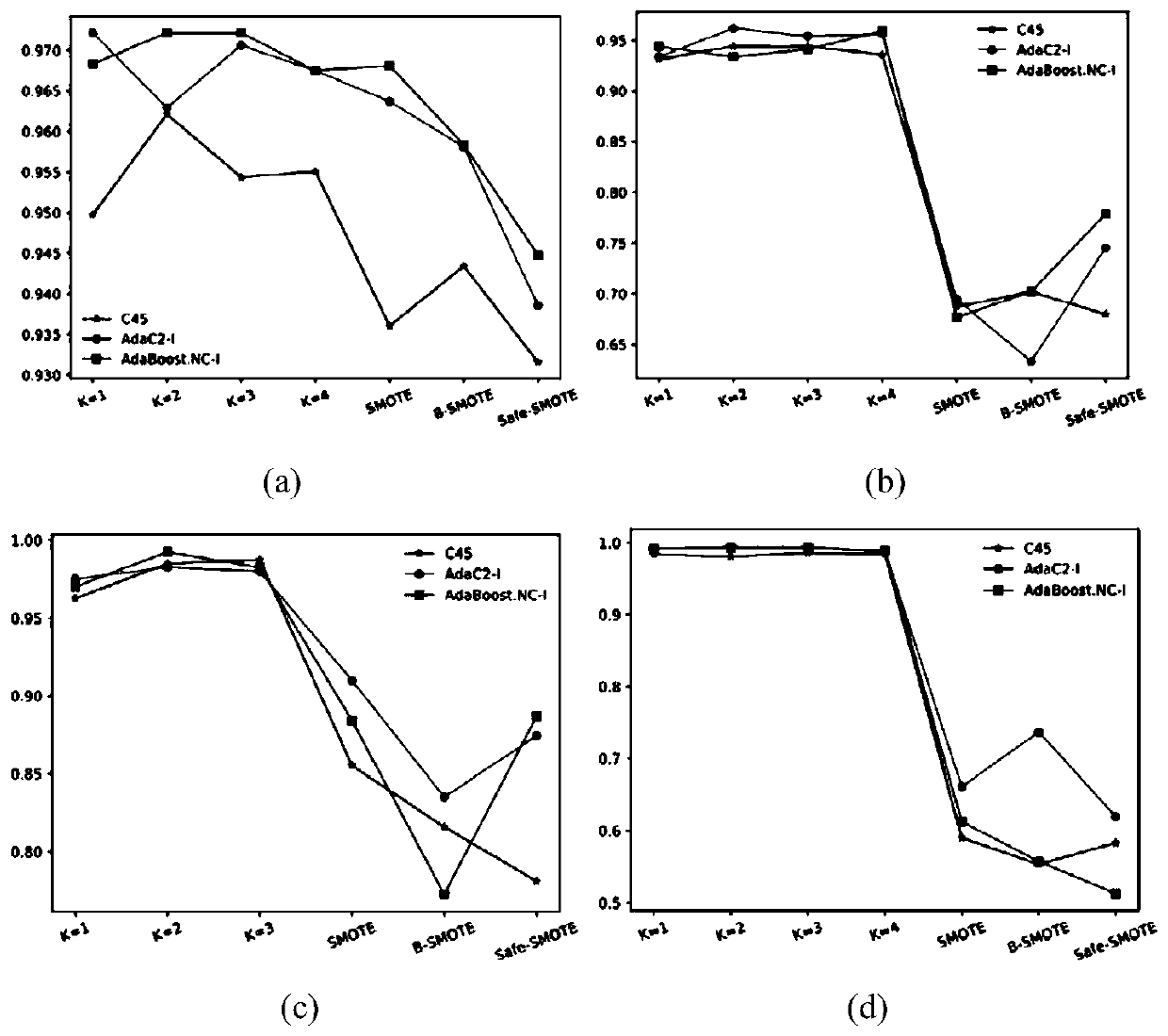
[0083] In this embodiment, the Python 3.5 programming language and KEEL software are used for testing. The experimental environment is a 64-bit Windows operating system, and the hardware configuration is Intel(R) Core i5-7300HQ CPU@2.50GHz, 8G memory.
[0084] 2. Simulation content and result analysis
[0085] The data sets used in this example are all from the unbalanced data sets in the KEEL database, and their feature dimensions and unbalanced rates are different. The specific information is shown in Table 1 below.
[0086] Table 1 Experimental data set
[0087]
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More PUM
 Login to View More
Login to View More Abstract
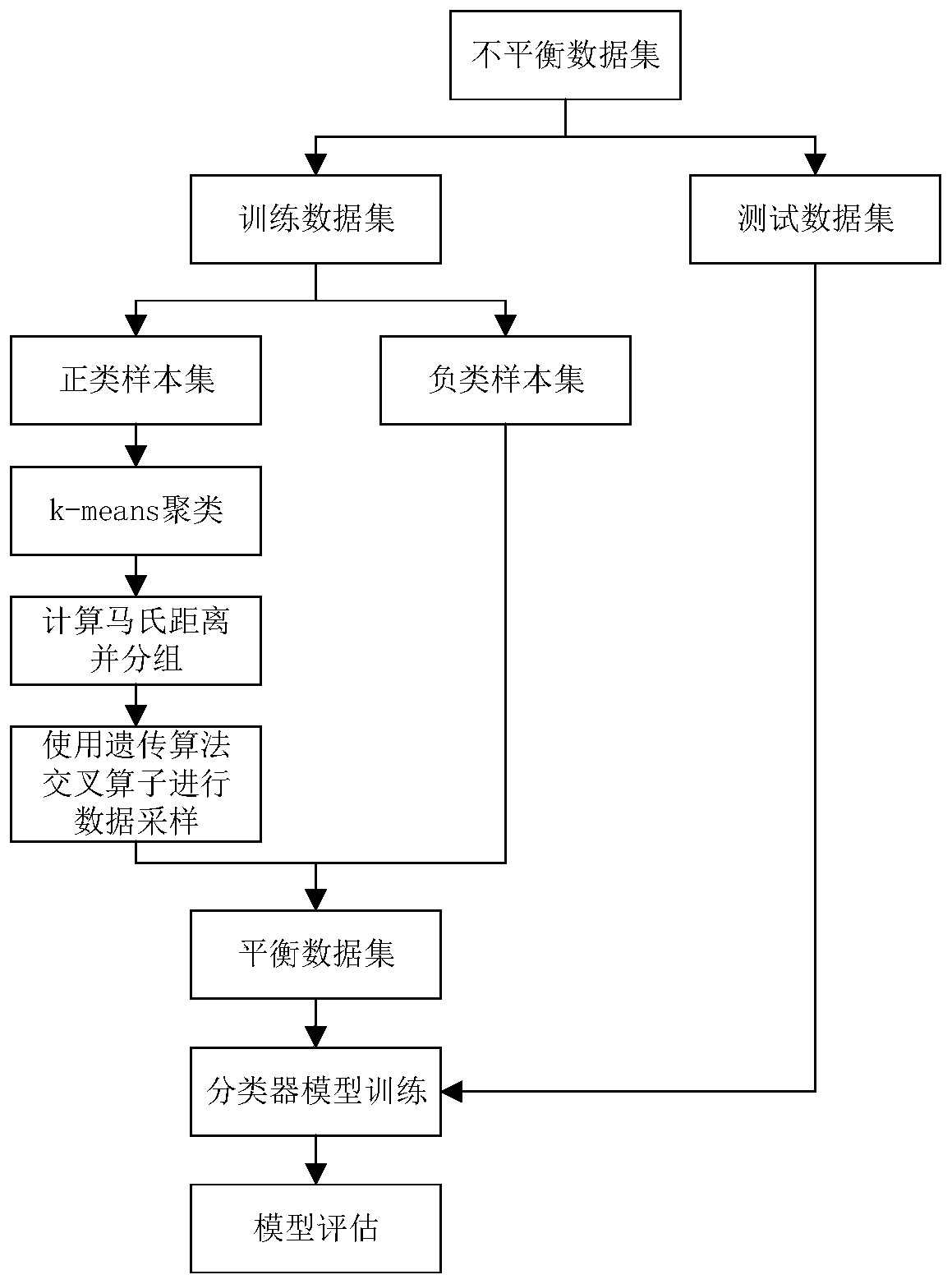
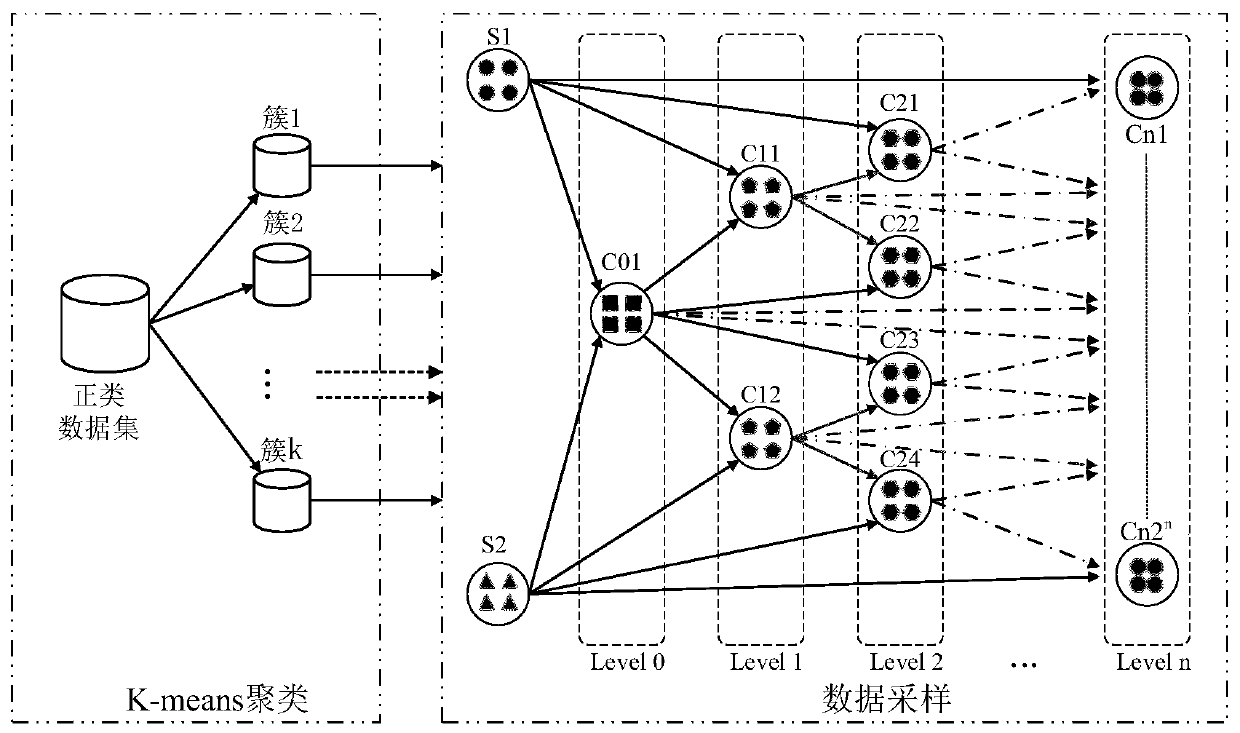
The invention discloses an unbalanced data set oversampling method based on a genetic algorithm and k-means clustering, and the method comprises the following steps: inputting an original unbalanced data set, and dividing the unbalanced data set into a training data set and a testing data set; dividing the training data set into a positive class sample set and a negative class sample set; clustering the positive class sample set by using a k-means clustering algorithm to obtain a plurality of different clusters; allocating corresponding sampling weights to the number of samples in each cluster; calculating the Mahalanobis distance of the sample data in each cluster, and dividing the sample data into two groups of parent class sample data sets according to the Mahalanobis distance; according to a crossover operator in the genetic algorithm, forming a new positive class sample by by utilizing the parent class sample data set; combining the newly synthesized positive class sample and theoriginal training data set into a balanced data set; training a classifier model by utilizing the balance data set; and evaluating the performance of the classifier model by utilizing the test data set. According to the method, the classification accuracy of the classifier model on the positive samples in the unbalanced data set can be effectively improved.
Description
technical field [0001] The invention belongs to the field of computer data mining, and relates to an oversampling classification method of unbalanced data sets, in particular to an oversampling method of unbalanced data sets based on genetic algorithm and k-means clustering. Background technique [0002] In the field of data classification, there is such a situation: in the data set, the number of samples of different categories varies greatly, among which samples with a large number are called multi-class samples, samples with a small number are called few-class samples, and multi-class samples are called It is called the negative class, and the minority class sample is called the positive class. Usually, Imbalance Rate (IR) is used to measure the degree of imbalance of a data set, which refers to the ratio of the number of negative samples to the number of positive samples in the data set. In many practical application fields, the cost of obtaining positive sample data is...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More IPC IPC(8): G06K9/62G06N3/12
CPCG06N3/126G06F18/23213G06F18/24
Inventor张永方立超李世博张鑫鑫戴旺邢宗义
OwnerNANJING UNIV OF SCI & TECH