Method and device using high layer syntax architecture for coding and decoding
A codec and syntax technology, applied in image communication, digital video signal modification, electrical components, etc., which can solve the problems of inefficient concealment of lost slices, and reduced decodability of slice independence.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
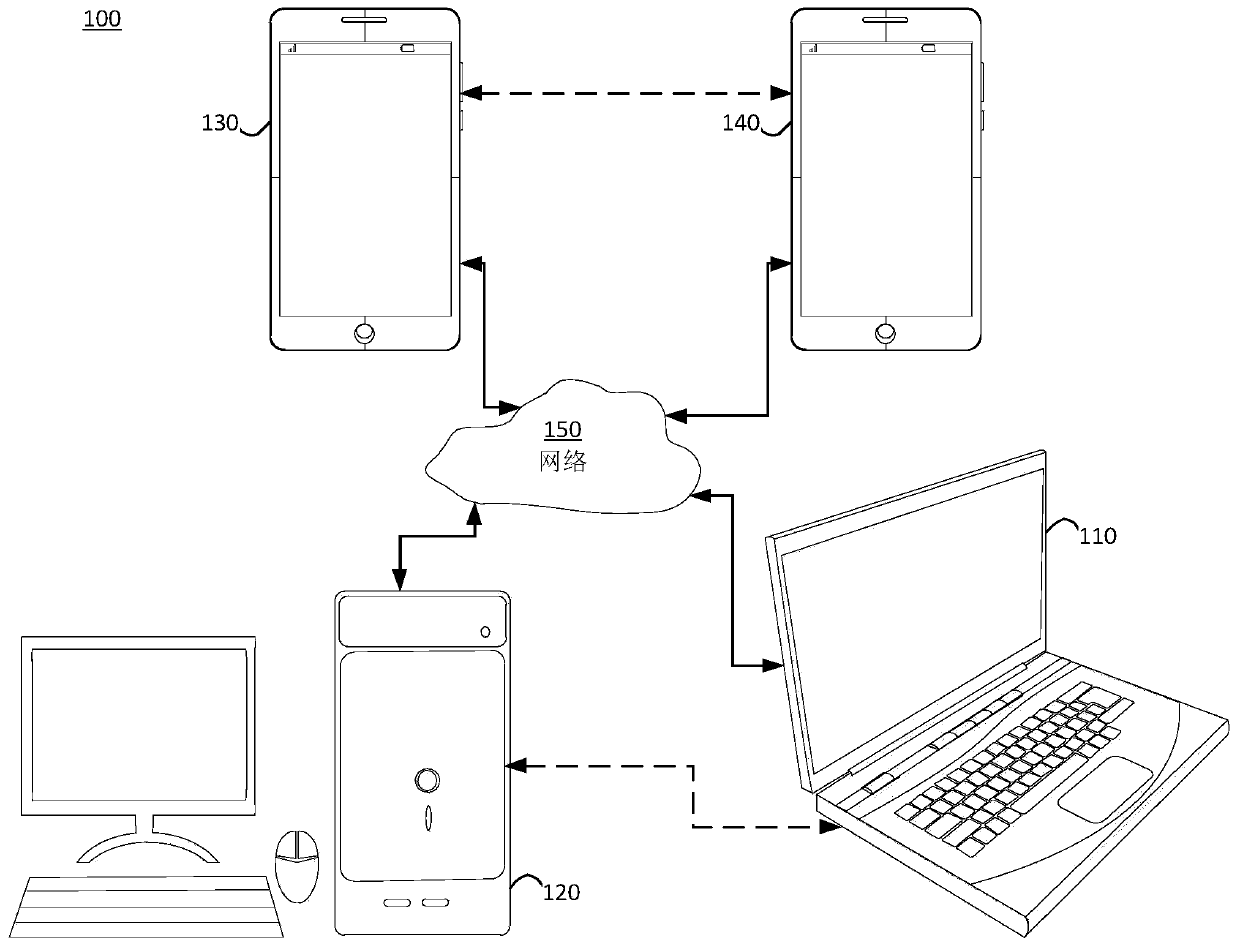
[0023] figure 1 A simplified block diagram of a communication system (100) of an embodiment of the disclosure is shown. The system (100) may include at least two terminals (110-120) interconnected by a network (150). For one-way data transmission, a first terminal (110) may encode video data at a local location for transmission to another terminal (120) over a network (150). The second terminal (120) may receive encoded video data of another terminal from the network (150), decode the encoded data and display the restored video data. One-way data transfer is often used in media service applications, etc.
[0024] figure 1 A simplified block diagram of a communication system (100) of an embodiment of the application is shown. The system (100) may include at least two terminals (110-120) interconnected by a network (150). For one-way data transmission, a first terminal (110) may encode video data at a local location for transmission to another terminal (120) over a network ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



