

Voice recognition method based on DBLSTM+CTC acoustic model
An acoustic model and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as overall performance degradation, inability to extract more discriminative features, and limited model fitting capabilities. The effect of anti-noise ability and high recognition rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0042] The following will clearly and completely describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are only a part of the present invention, not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the protection scope of the present invention.
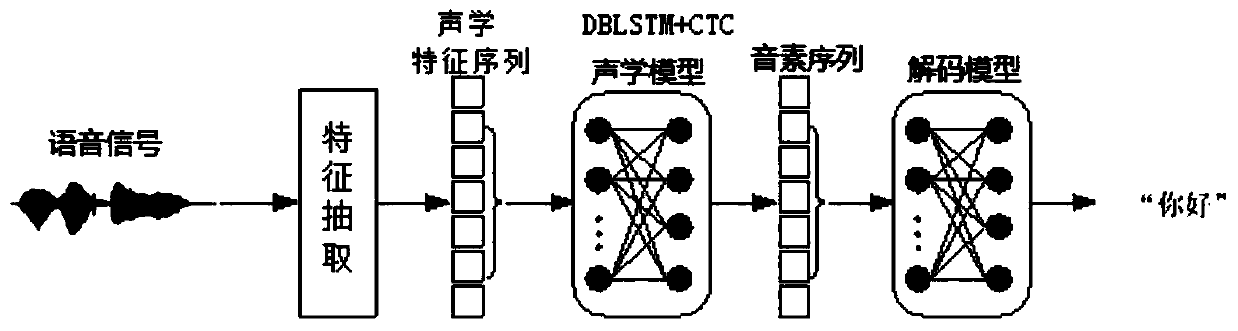
[0043] Such as figure 1 Shown, a kind of speech recognition method based on DBLSTM+CTC acoustic model provided by the present invention, described method comprises
[0044] Step 1, obtaining a real-time speech signal, performing feature extraction on the speech signal, and obtaining a frame-by-frame acoustic feature sequence;
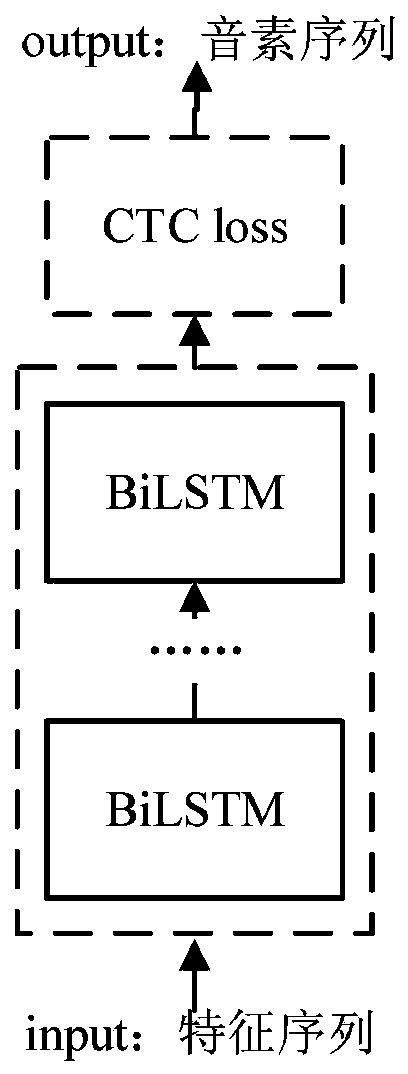
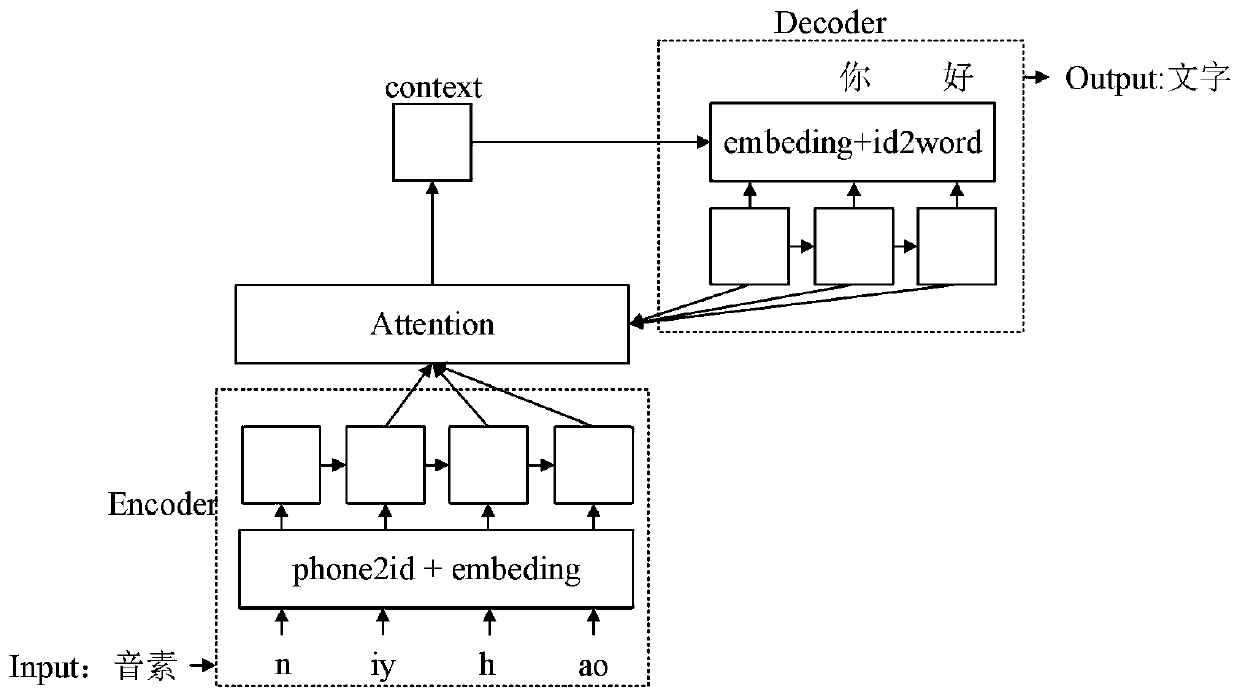
[0045] Step 2, using the acoustic feature sequence as the input of the DBLSTM+CTC acoustic model, and outputting the phoneme sequenc...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More