

Attitude transformation data processing method and device, computer equipment and storage medium
An attitude transformation and data processing technology, applied in the field of image processing, can solve the problems of low image quality of attitude transformation, difficult to obtain satisfactory results, unable to solve the problem of occlusion, etc., and achieve the effect of high robustness and accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

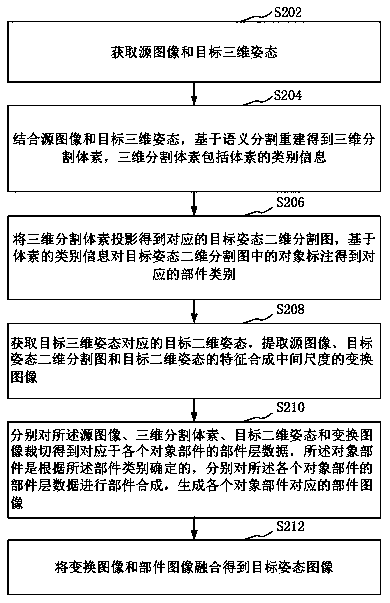
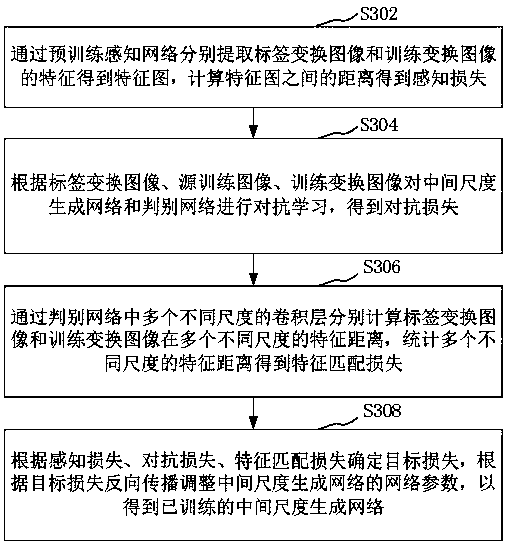
Examples
Embodiment Construction
[0025] In order to make the purpose, technical solution and advantages of the present application clearer, the present application will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present application, and are not intended to limit the present application.
[0026] It can be understood that the terms "first", "second" and the like used in the present application may be used to describe various elements herein, but unless otherwise specified, these elements are not limited by these terms. These terms are only used to distinguish one element from another element.
[0027] Artificial Intelligence (AI) is a theory, method, technology and application system that uses digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use kn...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More