

Open source data processing method and system based on adversarial samples
A data processing system and anti-sample technology, applied in the computer field, can solve the problems of bad blacklist setting, easy accidental injury to normal users, increase the difficulty of data identification, etc., and achieve the effect of improving the difficulty and cost of cracking
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0035]下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0036]需要说明的是,文中的步骤编号,仅为了方便具体实施例的解释,不作为限定步骤执行先后顺序的作用。本实施例提供的方法可以由相关的服务器执行,且下文均以服务器作为执行主体为例进行说明。
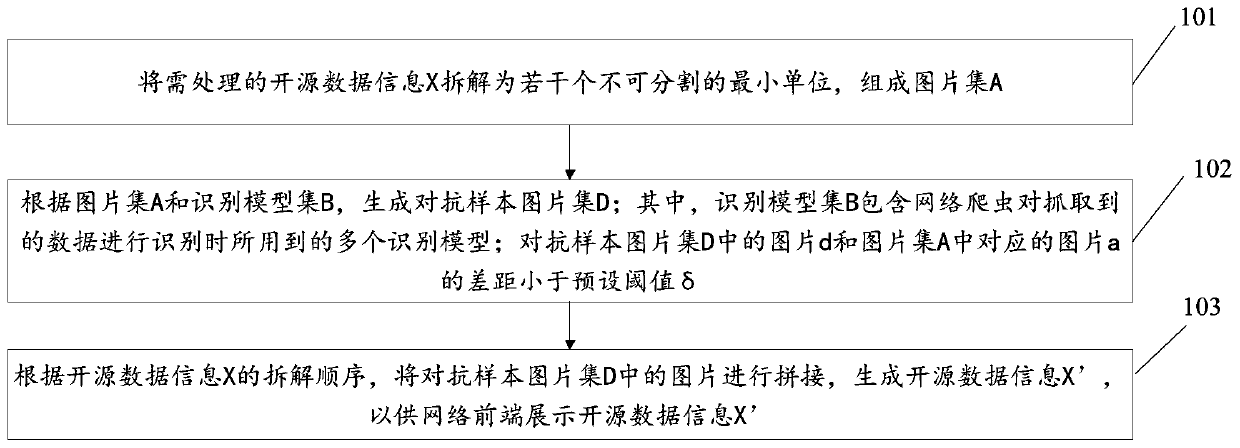
[0037]参见图1,图1是本发明提供的基于对抗样本的开源数据处理方法的一种实施例的流程示意图。如图1所示,该方法包括步骤101至步骤103,各步骤具体如下:
[0038]步骤101:将需处理的开源数据信息X拆解为若干个不可分割的最小单位,组成图片集A。
[0039]在本实施例中,开源数据信息X包括:数字、英文、中文或图片。当开源数据信息X为数字时,拆解的最小单位为每一个数字;当开源数据信息X为英文时,拆解的最小单位为每一个字母;当开源数据信息X为中文时,拆解的最小单位为每一个汉字;当开源数据信息X为图片时,拆解的最小单位为固定尺寸大小的图片。
[0040]在本实施例中,拆解后的一个最小单位对应一个图片,而为了便于后续的数据处理,每个图片可以设置一个固定尺寸。由拆解后的多个图片组成图片集A,对应普通用户而言,无论网络前端展示的是X还是A都能够通过肉眼正常识别。
[0041]步骤102:根据图片集A和识别模型集B,生成对抗样本图片集D;其中,识别模型集B包含网络爬虫对抓取到的数据进行识别时所用到的多个识别模型;对抗样本图片集D中的图片d和图片集A中对应的图片a的差距小于预设阈值δ。
[0042]在本实施例中,步骤102具体为:将图片集A和识别模型集B作为输入,对输入添加干扰噪声,生成对抗样本图片集D;其中,每张图片a∈A生成对应的对抗样本图片d,且满足|d-a|≤δ。
[0043]本实施例的识别模型集B包含多个识别模型,这些识别模型是网络爬虫对抓取到的数据进行识别时所用到的。对应网络爬虫而言,无论展示的是X还是A,其抓取到的数据都图片集A中的一个个元素,再通过常用的识别模型对图片集A进行还原,成为能够供网络爬虫认可或识别的数据,才能进行后续处理。这些模型能够对图片集A以较高的准确率进行识别,将这些模型作为模型集B。
[0044]在本实施...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More