

Data query method and device, electronic equipment and readable storage medium
A data query and query request technology, applied in database indexing, electronic digital data processing, structured data retrieval, etc., can solve problems such as poor timeliness of data query, long MR task development cycle, and inability to meet rapid business iteration, etc., to meet The effect of rapid business iteration and improved timeliness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
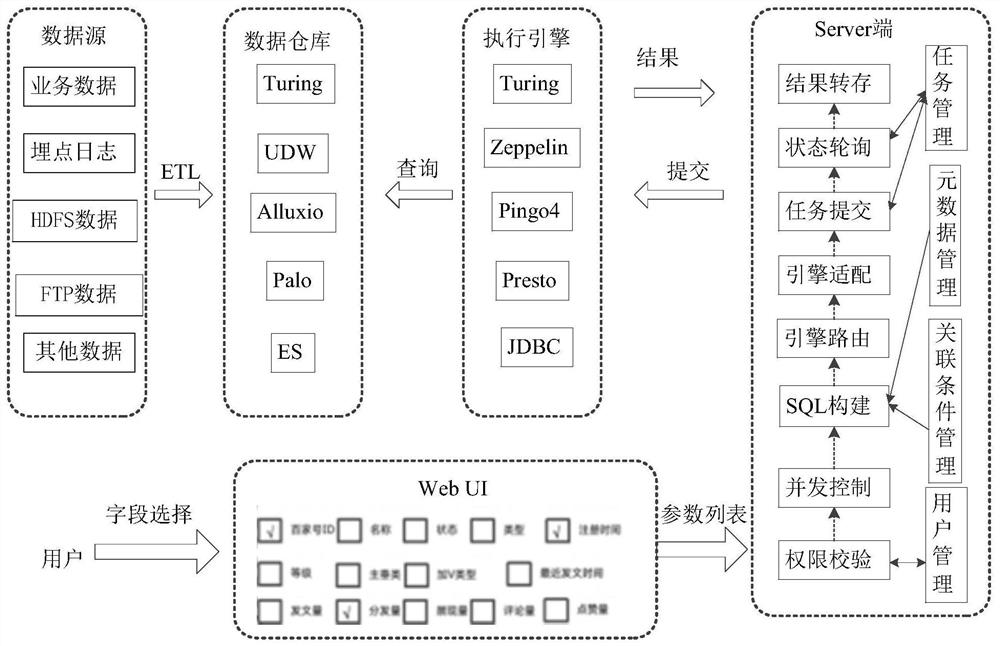
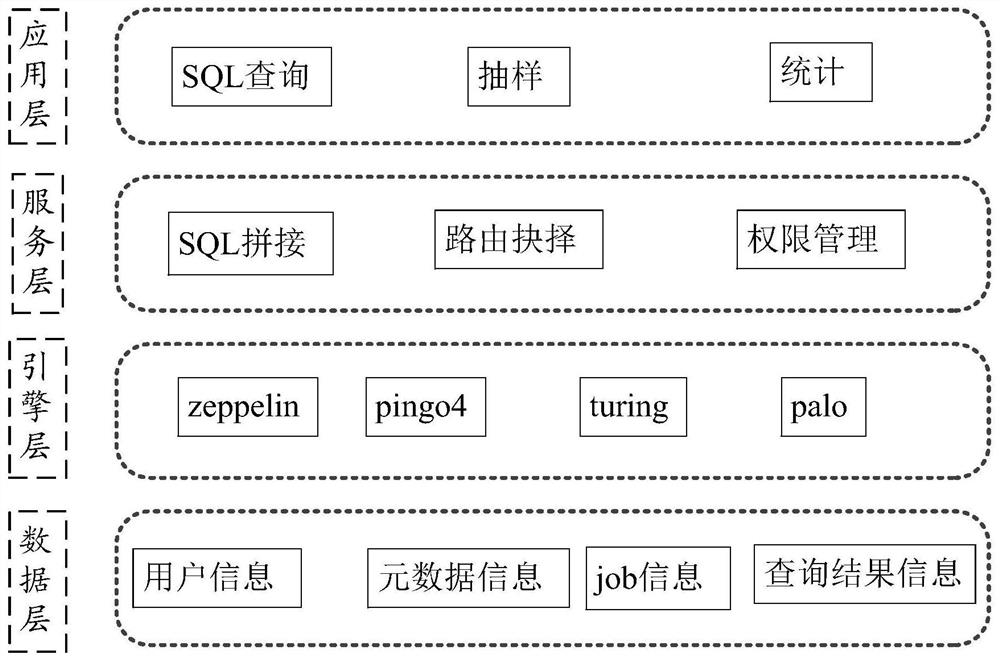
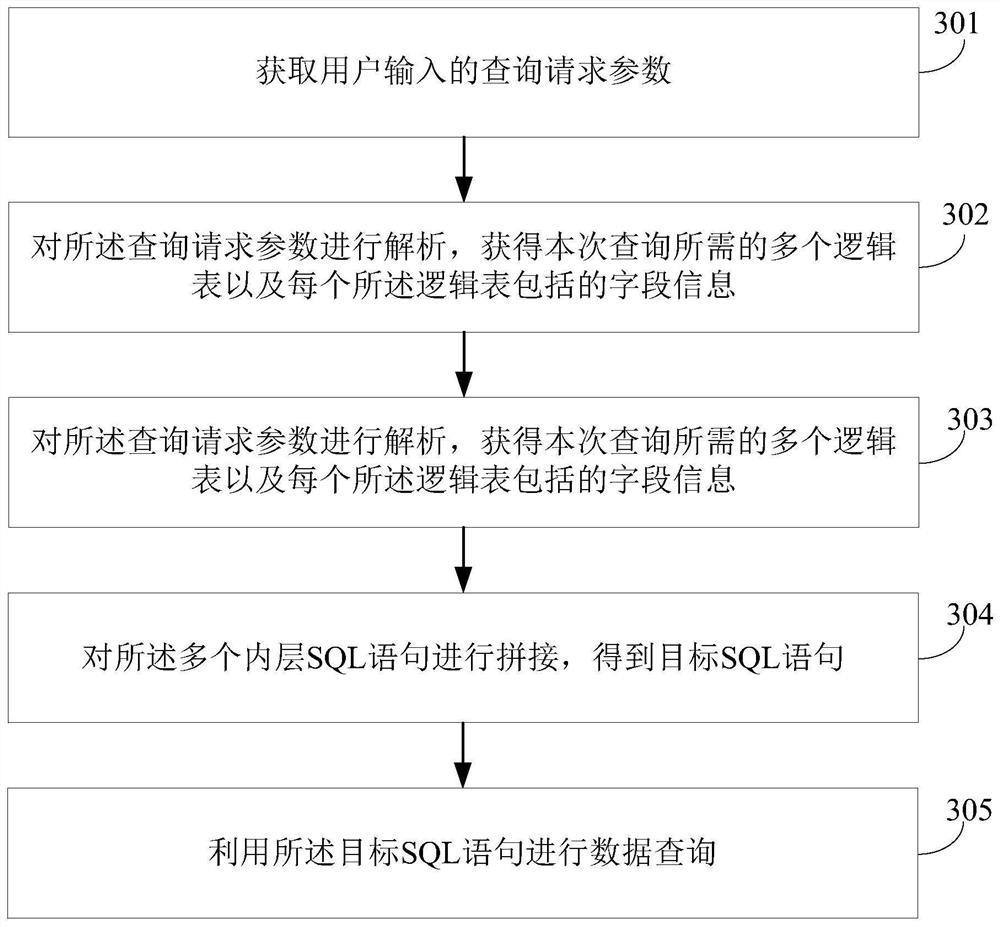
[0033] Exemplary embodiments of the present application are described below in conjunction with the accompanying drawings, which include various details of the embodiments of the present application to facilitate understanding, and they should be regarded as exemplary only. Accordingly, those of ordinary skill in the art will recognize that various changes and modifications of the embodiments described herein can be made without departing from the scope and spirit of the application. Also, descriptions of well-known functions and constructions are omitted in the following description for clarity and conciseness.
[0034] The terms "first", "second" and the like in the specification and claims of the present application are used to distinguish similar objects, and are not necessarily used to describe a specific order or sequence. It is to be understood that the data so used are interchangeable under appropriate circumstances such that the embodiments of the application describe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More