

Compression method and platform of pre-trained language model based on knowledge distillation
A technology of language model and compression method, which is applied in the field of compression method and platform of pre-trained language model, which can solve the problems of difficult generalization of small samples, increase of deep learning network scale, and increase of computational complexity, so as to improve the efficiency of model compression Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

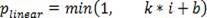
Examples
Embodiment Construction
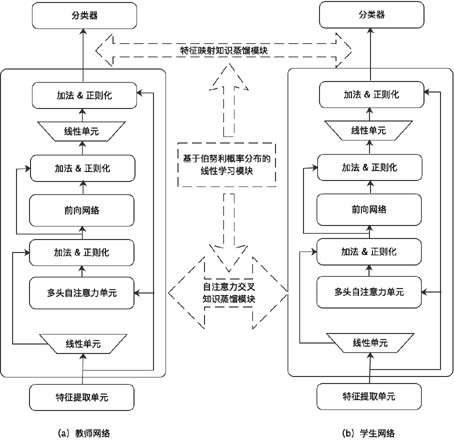
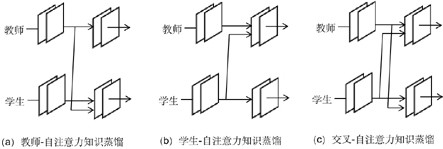
[0026] Such as figure 1 As shown, a compression method of pre-trained language model based on knowledge distillation includes feature map knowledge distillation module, self-attention cross knowledge distillation module and linear learning module based on Bernoulli probability distribution. Among them, the feature map knowledge distillation module is a universal knowledge distillation strategy for feature transfer. In the process of distilling the knowledge of the teacher model to the student model, the feature map of each layer of the student model is approached to the characteristics of the teacher, and the student model is more accurate. Pay more attention to the mid-level features of the teacher model and use these features to guide the student model. The self-attention cross-knowledge distillation module, that is, through the self-attention module of the cross-connection teacher and student network, realizes the deep mutual learning of the teacher model and the student mo...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More