

Data acquisition system
A data acquisition system and data technology, applied in the direction of network data retrieval, network data query, and other database retrieval, etc., can solve problems such as inconvenient data source management, excessive data volume, and affecting data effectiveness, and reduce configuration complexity , reduced learning costs, and low performance requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
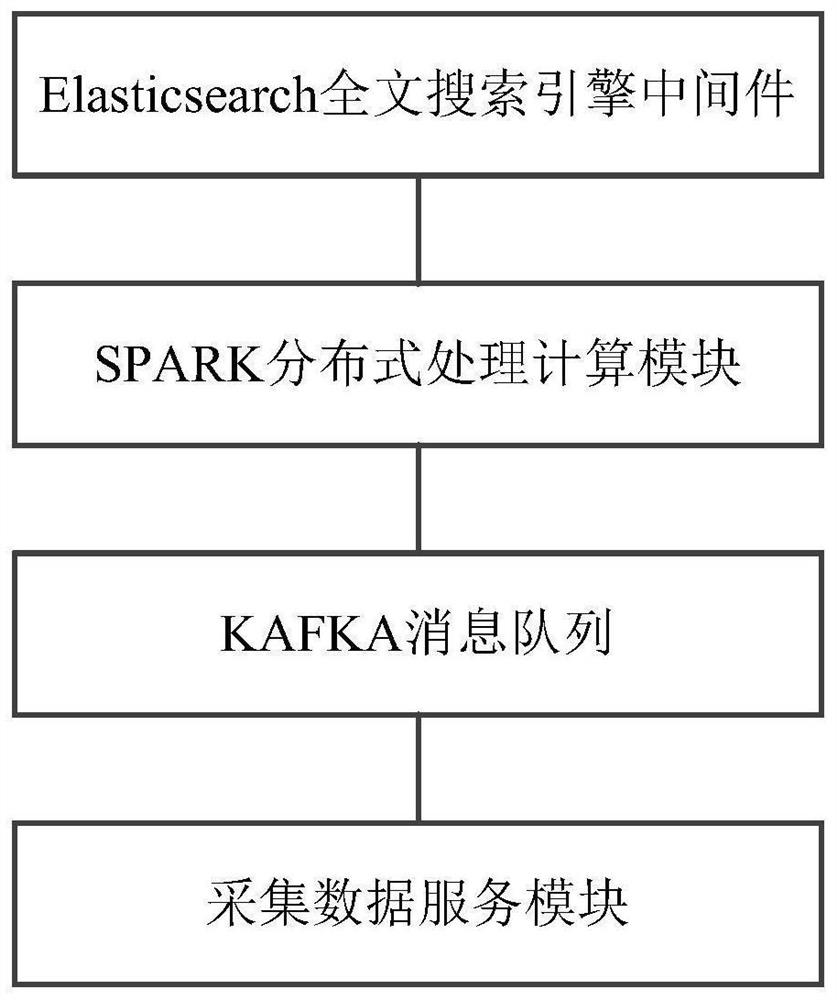
[0023] figure 1 A schematic structural diagram of the data acquisition system in Embodiment 1 of the present application is shown.
[0024] As shown in the figure, the data collection system includes: collection data service module, KAFKA message queue, SPARK distributed processing calculation module, and Elasticsearch full-text search engine middleware, wherein,
[0025] The data collection service module is developed by python language, and uses the pre-packaged driver class for different data sources to call the data in the form of parameters and send it to the designated partition of the KAFKA message queue after processing;
[0026] The KAFKA message queue includes multiple partitions for storing different types of data;
[0027] The SPARK distributed processing calculation module uses spark streaming to poll and calculate the data in KAFKA, and writes the calculated data into the Elasticsearch full-text search engine middleware;
[0028] The Elasticsearch full-text sea...
Embodiment 2
[0061] In order to facilitate the implementation of the present application, the embodiment of the present application is described with a specific example.
[0062] The embodiment of the present application provides a set of system for TV station new media data processing, including data collection service, KAFKA message queue, SPARK distributed processing calculation, Elasticsearch full-text search engine middleware.
[0063] 1. Data collection service
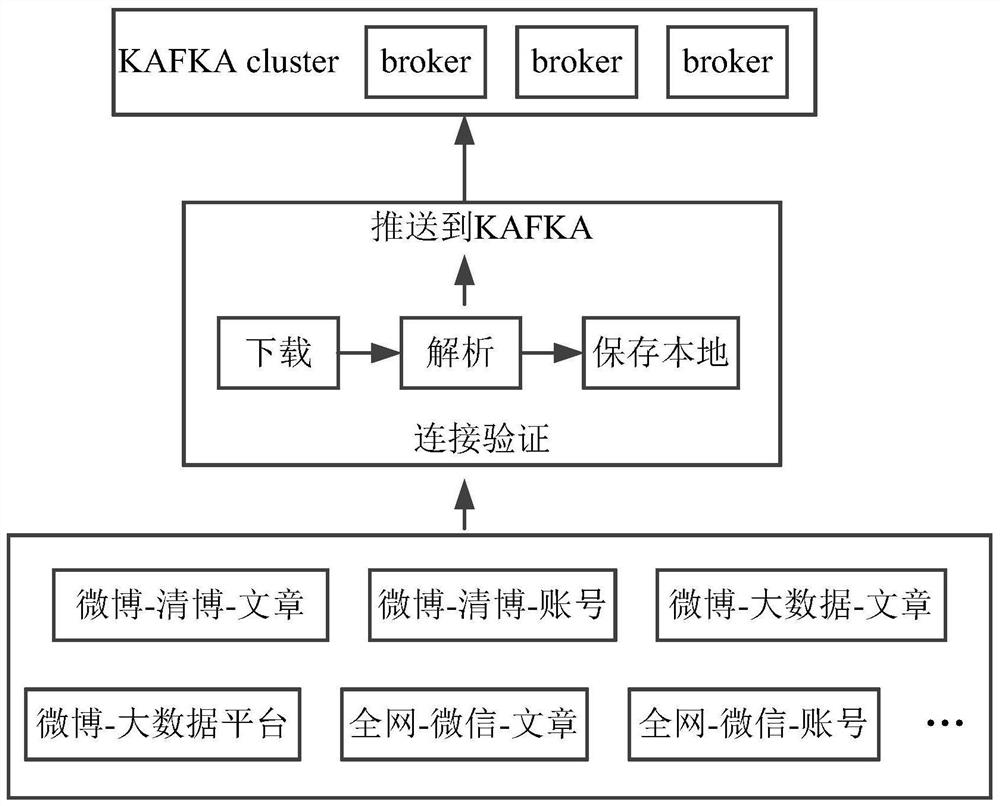
[0064] figure 2 A schematic diagram of the principles of the data collection service in Embodiment 2 of the present application is shown.
[0065] As shown in the figure, the data collection service in this embodiment of the application is developed using language. Python allows developers to focus on programming objects and thinking methods without having to worry about external factors such as syntax and types. Its clear and concise syntax also makes it much easier to debug than Java. For operations related to kafka, f...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More