

Method for implementing repeated data deletion technology based on single-hash averaging Bloom filter
A technology for data deduplication and implementation methods, applied in the computer field, can solve the problems of increased resources consumed by Bloom filters, lower cost performance, and lower computing power, and achieve mutual independence, low computing consumption, and fast filtering Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment
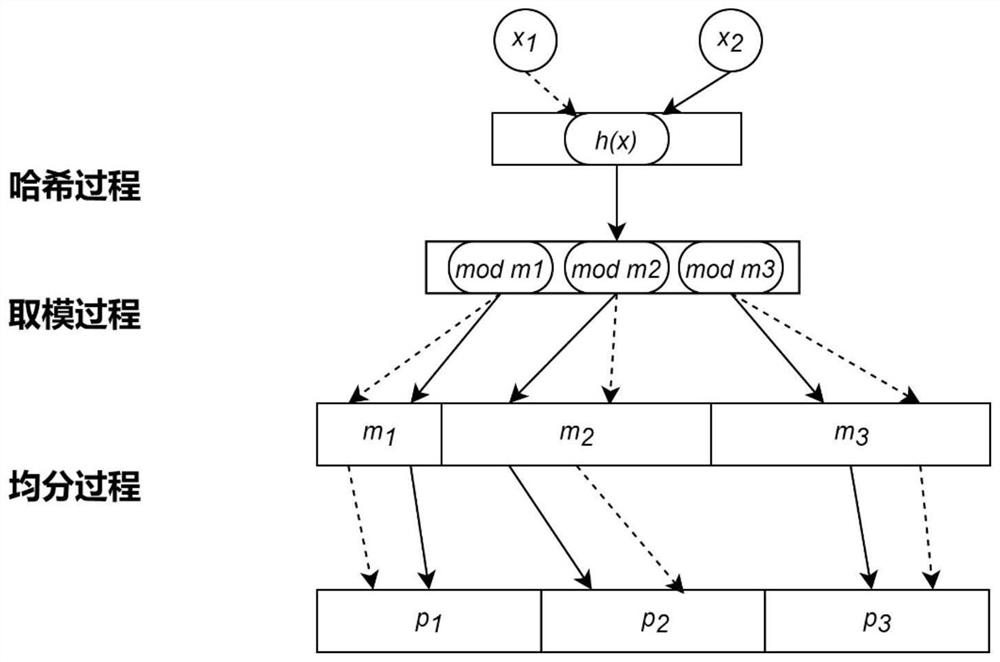
[0050] The implementation method of deduplication technology based on single hash uniform distributed long filter, such as figure 1 shown, including the following steps:
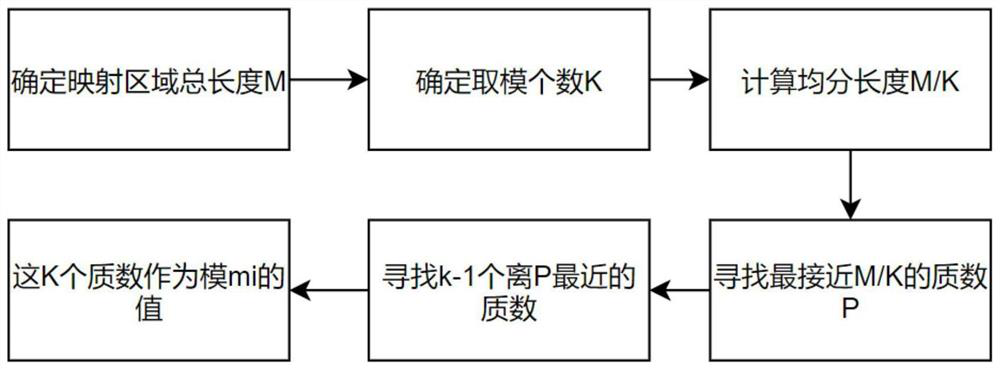
[0051] S1. Determine the length of the storage area, determine the length of the partition, determine the first data set D1 including D data that needs to be stored, set j=1, and determine the second data set D2 to be queried;
[0052] The length of the storage area is the storage size M of the single-hash uniform distribution filter, then the final length of each partition is the integer part of M / k, and the length of the last partition can be less than M / k.
[0053] In this embodiment, the first data set D1 contains a data x 1 , the storage area length is 24, k is 3, and 3 partitions p 1 ,p 2 ,p 3 The length of each is 8;
[0054] S2. Select a high-demand hash function within the scope of the storage area, and take the j-th data d in the first data set D1 j Carry out hash calculation and obtain hash ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More