Outdoor construction site-oriented dangerous source intelligent identification system and method
A construction site, intelligent identification technology, applied in closed-circuit television systems, neural learning methods, character and pattern recognition, etc., can solve the problem of not being able to meet the monitoring requirements of general hazards on the construction site and special hazards for outdoor construction at the same time, and unable to understand the construction scene Complicated, rich semantics, unable to meet the needs of complex outdoor construction scenes, etc., to achieve the effect of improving diversity and comprehensiveness, increasing the pass rate, and improving the qualification pass rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

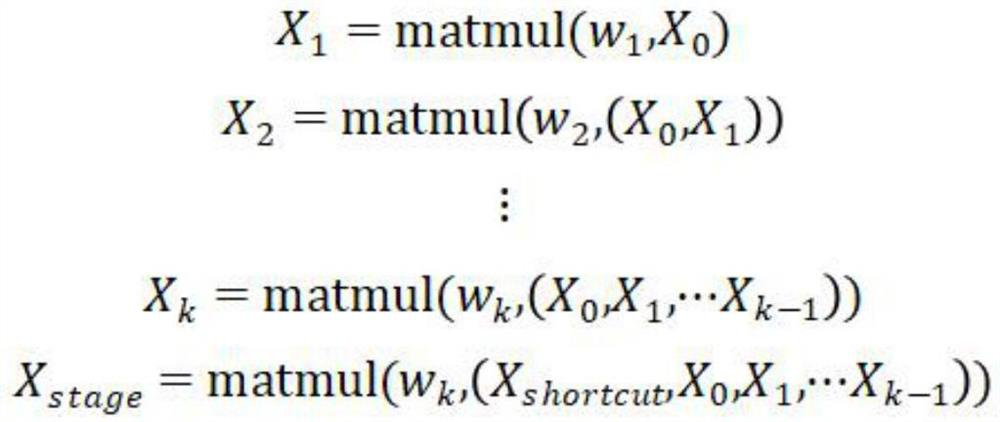
Examples
Embodiment 1
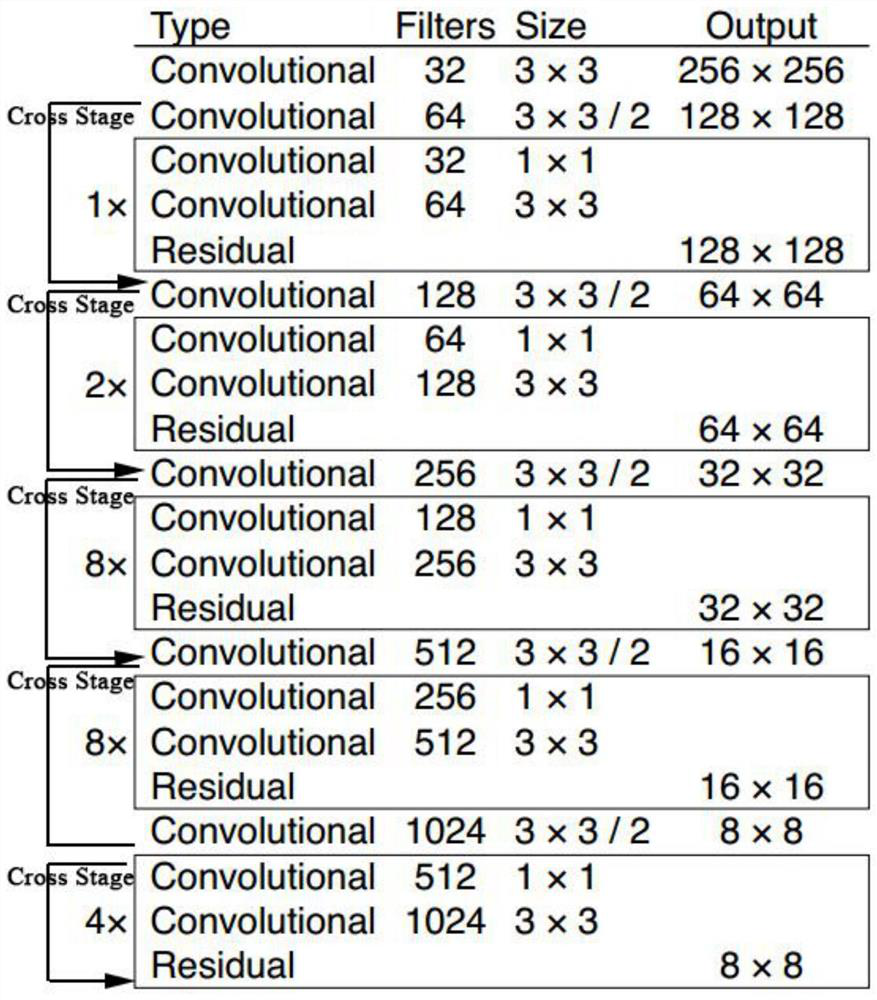
[0053] Supported by the research and development funds of the Artificial Intelligence Research and Development Center of China Post Construction Consulting Co., Ltd., this invention uses deep learning and computer vision technology to focus on the application of artificial intelligence in the field of construction site safety management and control. Committed to using high-performance image processing technology to intelligently detect the construction site, to study, judge and deal with potential risk factors, to ensure the timeliness and comprehensiveness of the construction site safety information feedback.
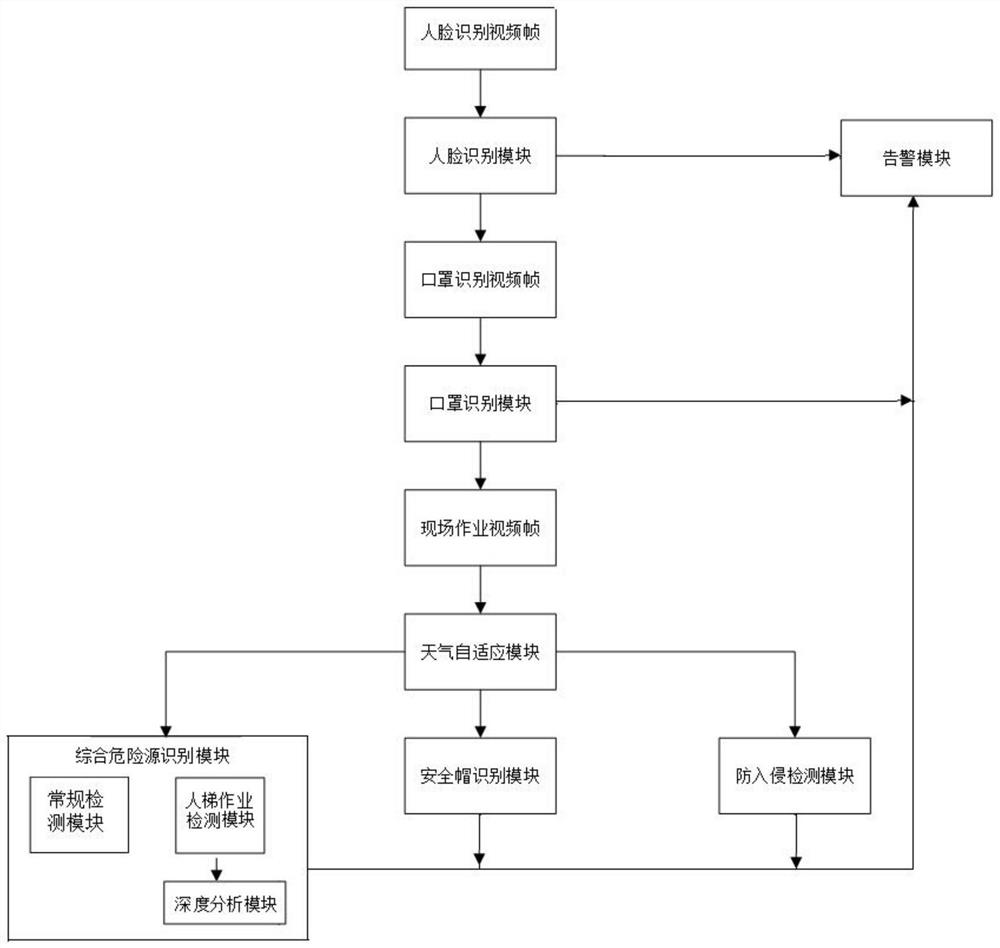
[0054] Such as figure 1 , 2 As shown, the hazard source intelligent identification system for outdoor construction sites includes: video surveillance module, face recognition module, mask recognition module, comprehensive hazard source recognition module, anti-intrusion detection module, safety helmet recognition module and alarm module, alarm module They are respecti...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com