Judgment document-based bidirectional encoder characterization quantity model optimization method and device
A characterization and encoder technology, applied in the field of bidirectional encoder characterization model optimization based on judgment documents, can solve problems such as low data quality, poor model effect, and unreasonable task selection, and achieve improved application effects and good support. Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0058] In order to make the purpose, technical solution and advantages of the present application clearer, the present application will be further described in detail below in conjunction with the accompanying drawings and embodiments. It should be understood that the specific embodiments described here are only used to explain the present application, and are not intended to limit the present application.
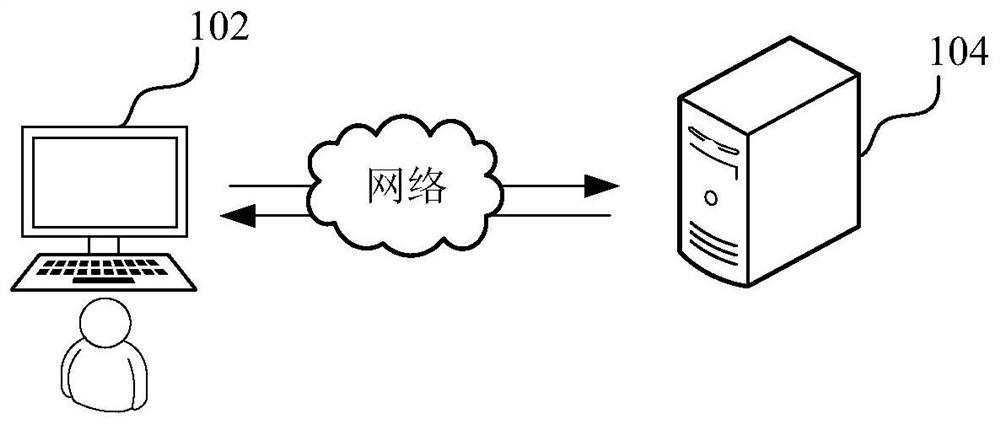
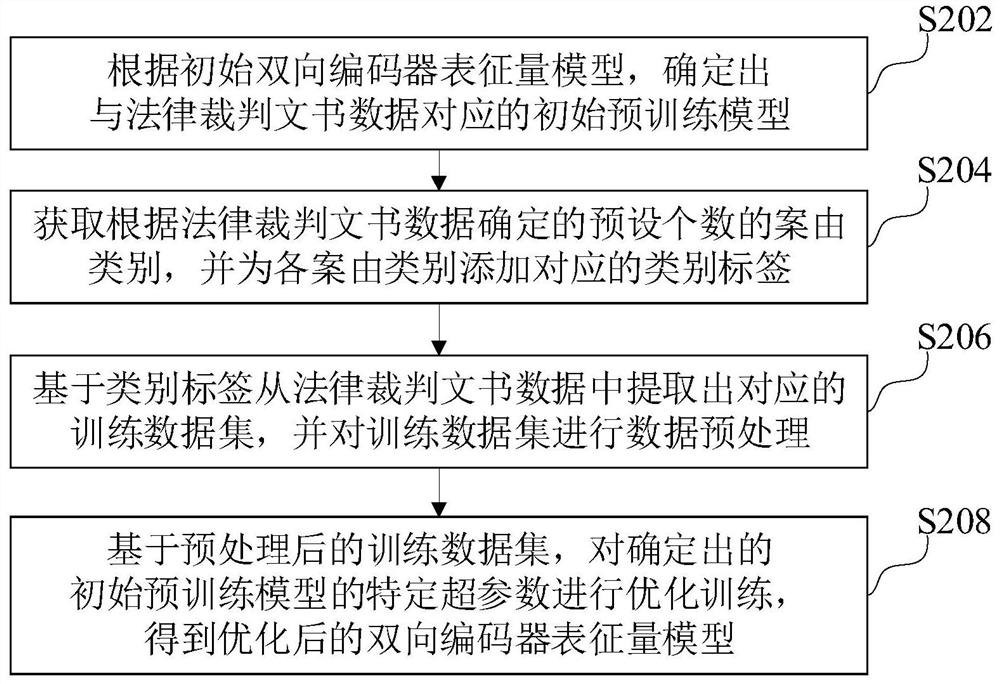
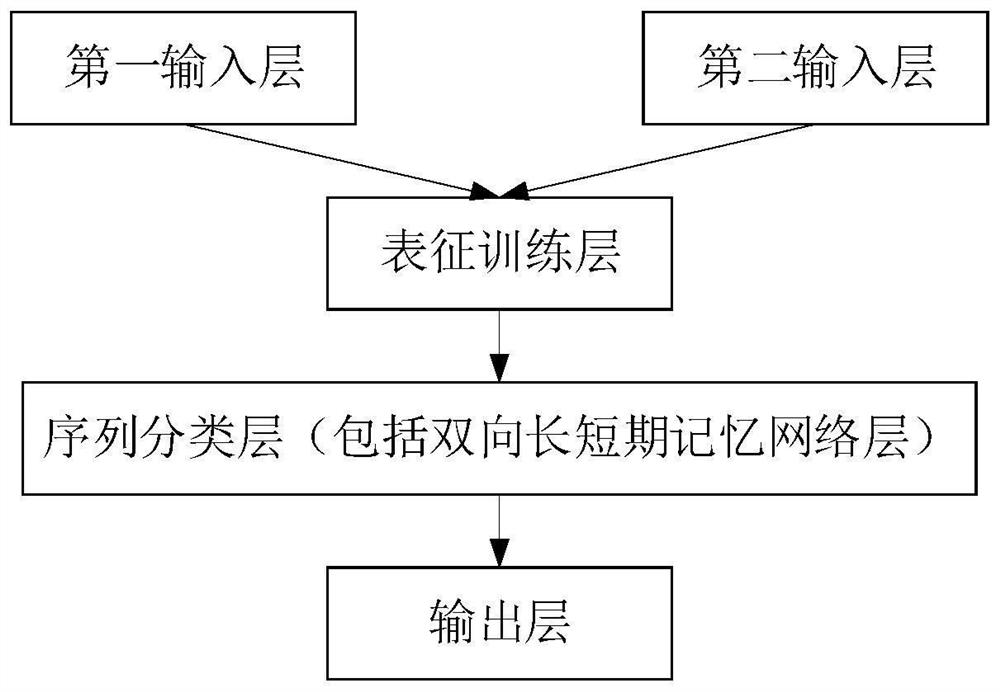
[0059] The bidirectional encoder characterization model optimization method based on referee documents provided by this application can be applied to such as figure 1 shown in the application environment. Wherein, the terminal 102 communicates with the server 104 through the network. According to the initial two-way encoder characterization model, determine the initial pre-training model corresponding to the legal judgment document data, wherein the legal judgment document data can be stored in the local storage where the terminal 102 is located, or when a corresponding m...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More