

Software defect prediction method based on class imbalance learning algorithm
A software defect prediction and learning algorithm technology, applied in neural learning methods, integrated learning, computer components, etc., can solve problems such as imbalance, and achieve the effect of avoiding subjectivity and reducing costs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
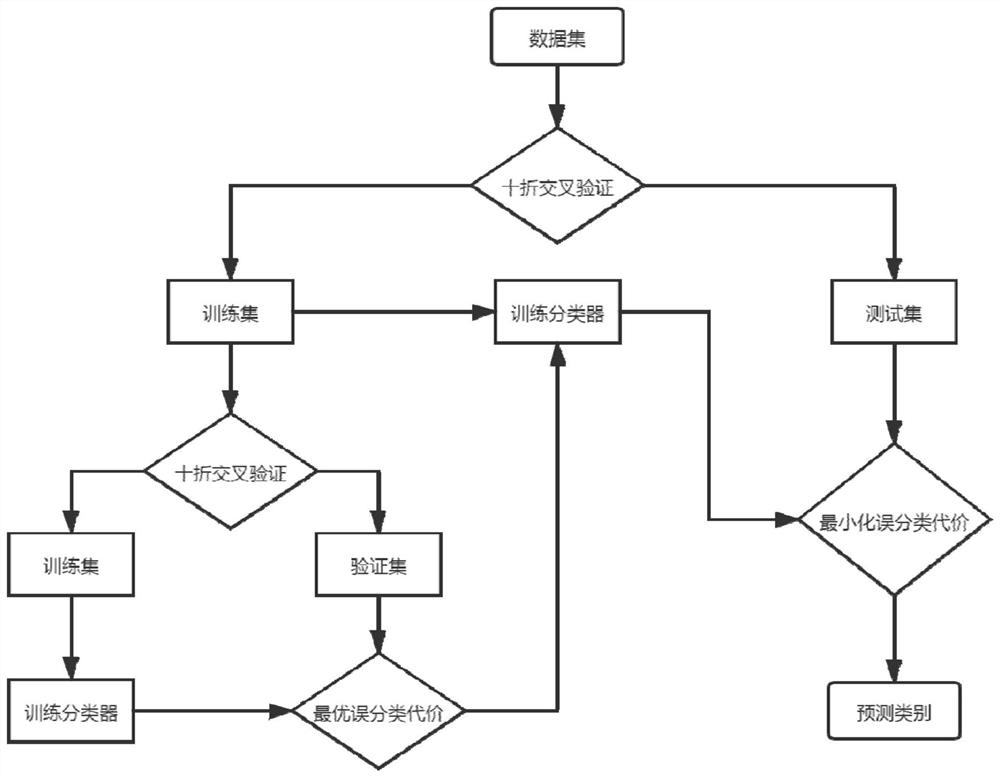
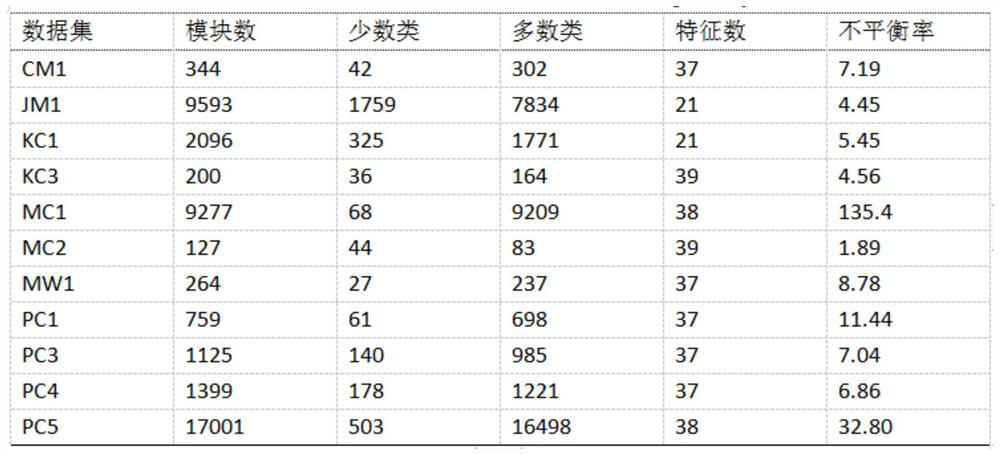
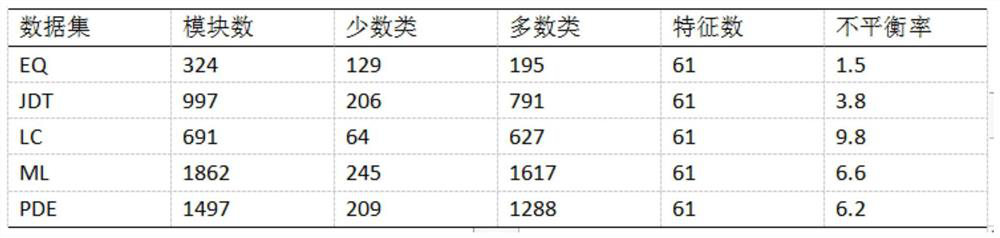
[0041] combine figure 2 and image 3 , the NASA defect prediction data set and the AEEEM defect prediction data set illustrate the present invention in detail. Overall process of the present invention is as accompanying drawing figure 1 As shown, the specific steps are as follows:
[0042] Step 1. Use the SWIM oversampling method to synthesize minority class samples, and then combine the generated minority class samples with the original data to obtain a data set with a low imbalance rate.
[0043] Step 2. Use the ten-fold cross-validation method to divide the data set in step 1 into a training set and a test set for the prediction accuracy of the training model and the test model. Then use the ten-fold cross-validation method to divide the training set into a training set and a validation set, which is used to calculate the most suitable minority class misclassification cost for the current data set.
[0044]Step 3. Use the training set obtained from the second division ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More