Professional dance evaluation method for realizing human body posture detection based on deep transfer learning
A technology of transfer learning and human body posture, applied in the direction of neural learning methods, instruments, biological neural network models, etc., can solve problems such as inability to achieve accurate scoring, wrong recognition, and missed recognition, and achieve improved recognition accuracy, low cost, and improved efficiency effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0037] The present invention will be described in detail below in conjunction with the drawings and specific embodiments. This embodiment is carried out on the premise of the technical solution of the present invention, and detailed implementation and specific operation process are given, but the protection scope of the present invention is not limited to the following embodiments.
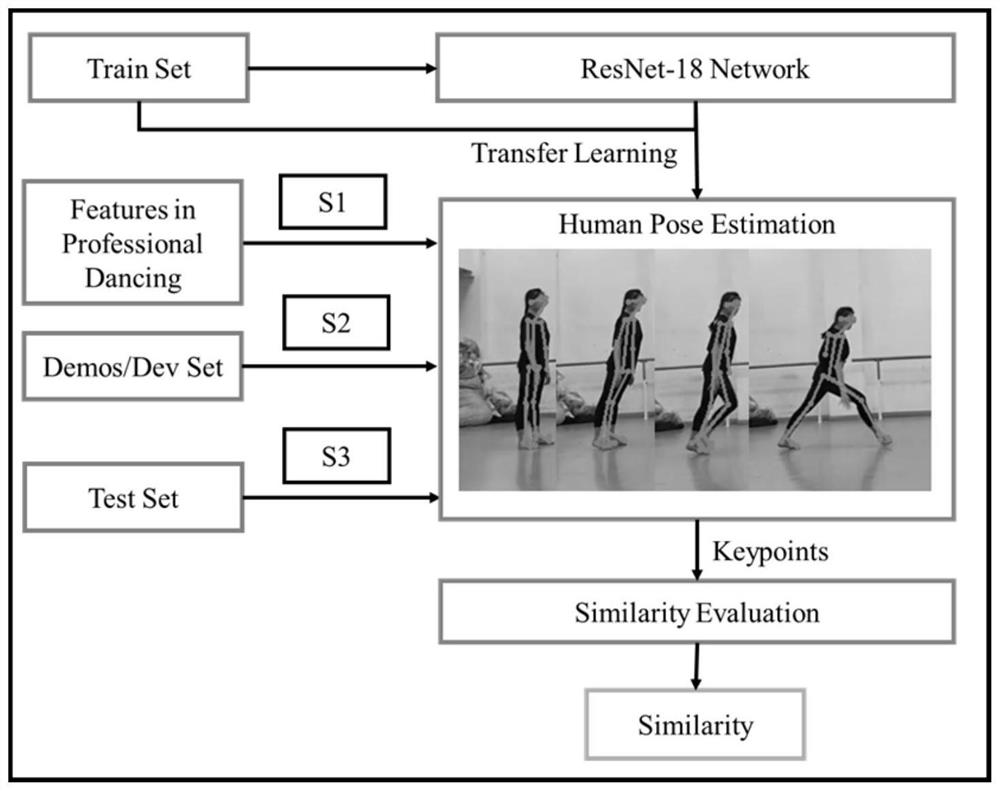
[0038] Such as figure 1 Shown:
[0039] A professional dance evaluation method based on deep transfer learning to realize human posture detection, the following process:
[0040] Step S1: Using the principle of deep transfer learning, combined with the posture characteristics of professional dance training to establish a special human posture detection model;
[0041] Step S11: using the pre-trained convolutional neural network model and the source domain training set to extract the features of the image hierarchy and realize the recognition of human body joints;
[0042] The data set used in t...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com