

Visual rich document information extraction method for actual OCR scene
An information extraction, rich document technology, applied in the field of visual information extraction, which can solve the problems of complex OCR prediction, unclear named entity boundaries, and positioning frame extraction.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
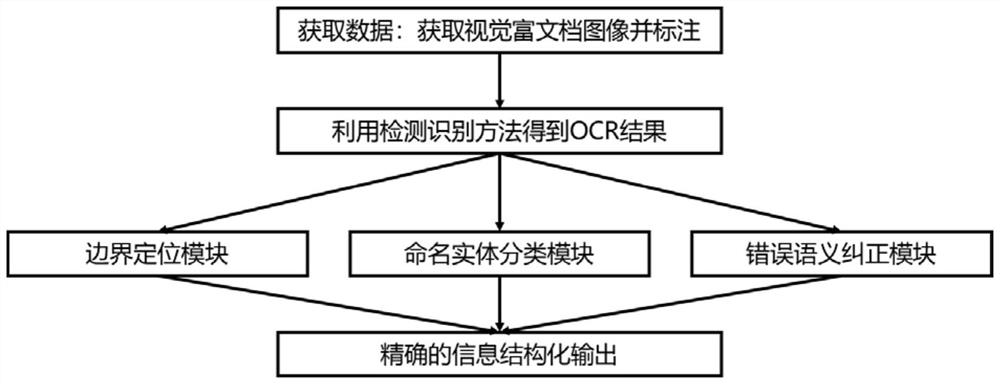
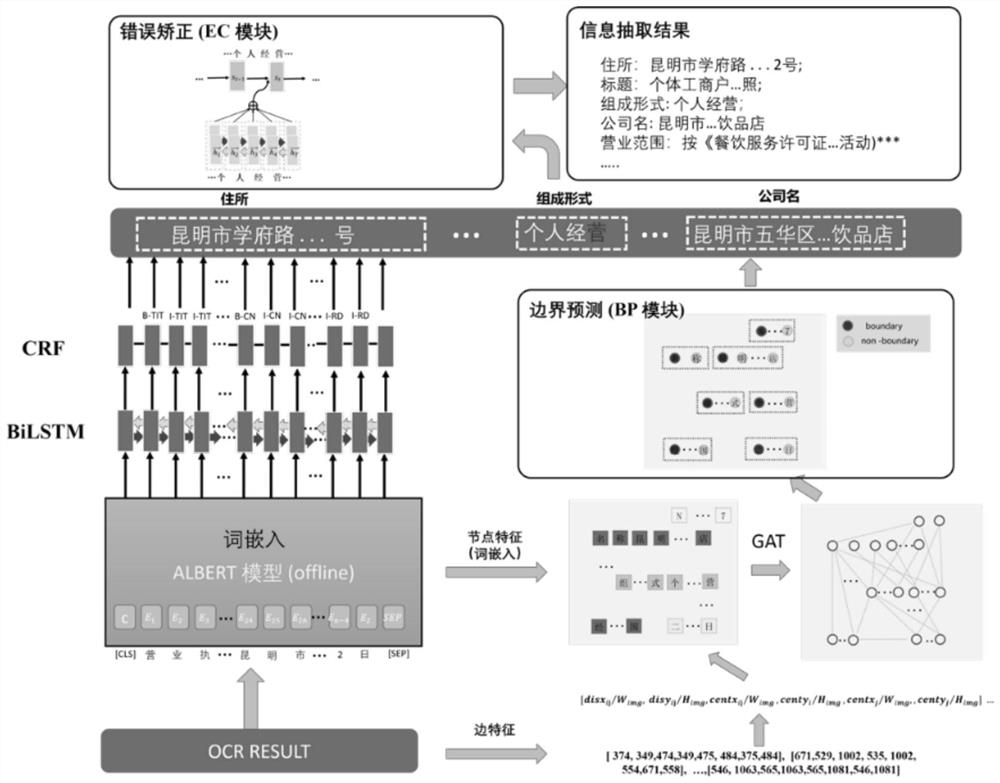
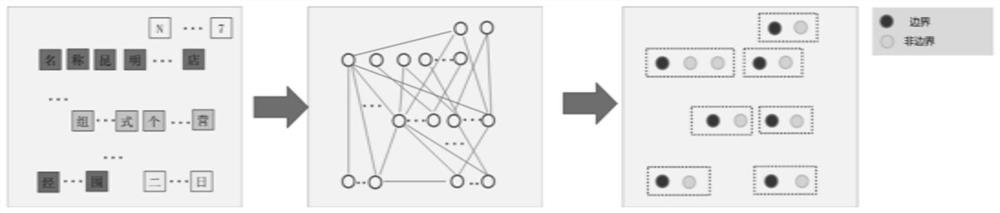
[0052] Such as figure 1 , figure 2 As shown, in the present invention, a method for extracting visually rich document information in an actual OCR scene comprises the following steps:
[0053] S1. Collect visual rich text images with key information in the actual scene, and label the collected images with text lines, specifically:
[0054] In this embodiment, the visually rich text image data set includes data of a simple layout and a complex layout, which are respectively composed of bills, train tickets, passports and other data. Contains 4306, 1500, and 2331 in sequence, a total of 8137 images.
[0055] S11. Carry out labeling of text line position, text content and named entity attributes on the collected images, specifically:
[0056] The labeling of the named entity attribute is specifically for the named entity label under the actual OCR result, and the named entity label refers to the labeling of the sentence word using the sequence labeling method of BIO tagging; ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More