Unlock instant, AI-driven research and patent intelligence for your innovation.
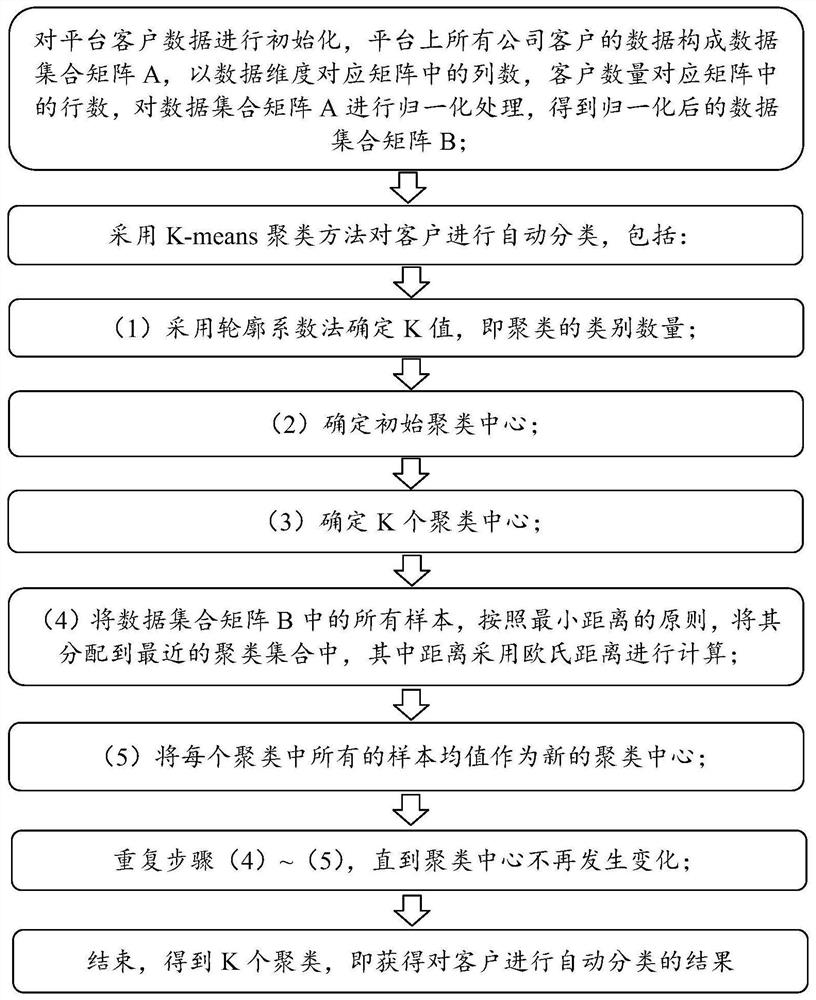
Automatic customer classification method based on K-Means clustering
What is Al technical title?
Al technical title is built by PatSnap Al team. It summarizes the technical point description of the patent document.
An automatic classification and customer technology, applied in the field of data processing, can solve problems such as poor objectivity, waste of resources, time-consuming, etc., to achieve the effect of improving customer experience, improving work efficiency, and saving customer time
Pending Publication Date: 2021-06-04
青岛檬豆网络科技有限公司
View PDF10 Cites 1 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
[0005] (1) The objectivity is not strong. In the classification process of different people, personal subjective factors will be mixed in it. At the same time, the classification standard for customers will also be limited and affected by human subjective factors, so it will cause the classification results of customers not objective
[0006] (2) Waste of resources. It takes a lot of time to classify a large number of customers manually, which will cause a waste of human resources for the platform.
[0007] However, there is a lack of suitable automatic classification methods in the prior art
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
example 2
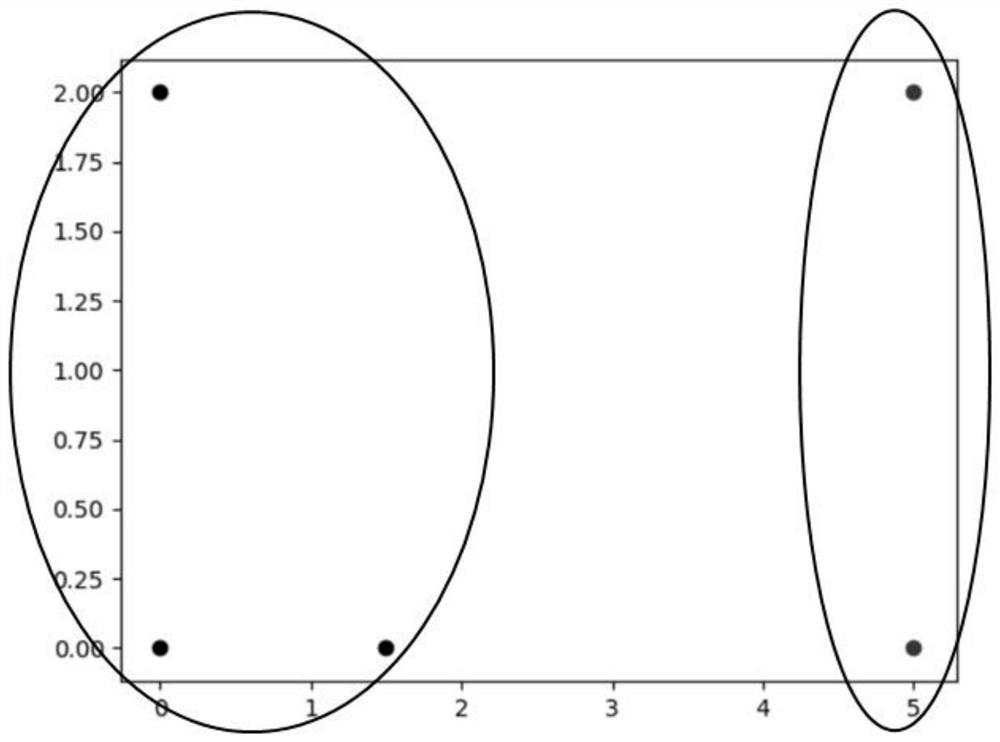
[0172] Example 2. Calculation example of K-Means clustering algorithm
[0173] Suppose there is data as follows:
[0174] o 1 (0, 2), O 2 (0,0),O 3 (1.5, 0), O 4 (5,0),O 5 (5, 2)
[0175] 1. Choose O 1 (0, 2), O 2 (0, 0) is the initial cluster center, namely M 1 =O 1 =(0,2), M 2 =O 2 =(0,0).
[0176] 2. For each remaining object, assign it to the nearest class according to its distance from each cluster center.
[0177] to O 3 :
[0178]
[0179]
[0180] Since d(M 2 , O 3 )≤d(M 1 , O 3 ), so the O 3 assigned to C 2 .
[0181] to O 4 :
[0182]
[0183]
[0184] Since d(M 2 , O 4 )≤d(M 1 , O 4 ), so the O 4 assigned to C 2 .
[0185] to O 5 :
[0186]
[0187]
[0188] Since d(M 1 , O 5 )≤d(M 2 , O 5 ), so the O 5 assigned to C 1 .
[0189] Update, get new class C 1 ={O 1 , O 5} and C 2 ={O 2 , O 3 , O 4}, the center is M 1 =(0,2), M 2 =(0,0). Compute the squared error criterion, for a single variance:
[0190...
example 3
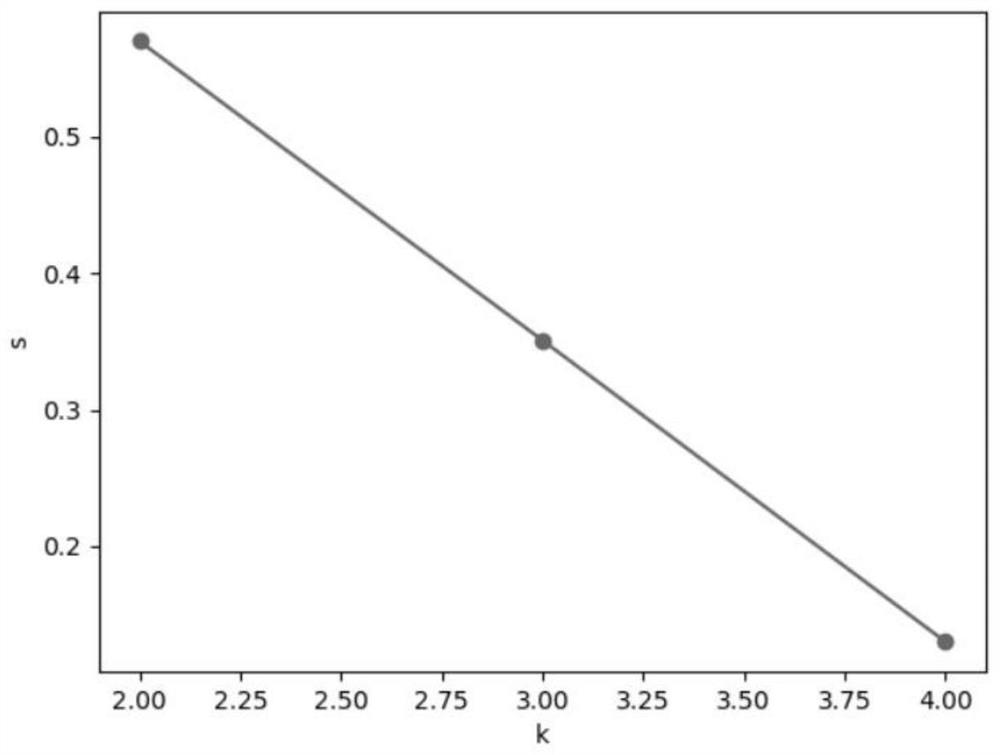
[0202] Example 3. Calculation example of K value determined by contour coefficient method
example 1
[0203] Example 1: According to the result after clustering in Example 2: K=2, clustering result C 1 ={O 1 , O 5} and C 2 ={O 2 , O 3 , O 4}, where O 1 (0, 2), O 2 (0,0),O 3 (1.5, 0), O 4 (5,0),O 5 (5, 2).
[0204] 1. Calculate the degree of dissimilarity within the sample class (calculate O 1 , O 2 Intra-class dissimilarity as an example):
[0205]
[0206]
[0207] 2. Calculate the dissimilarity between sample classes (calculate O 1 ,O 2 The dissimilarity between classes is taken as an example):
[0208] Since K=2 in this example, that is, the inter-class dissimilarity is the inter-class dissimilarity between the sample and another class.
[0209]
[0210]
[0211] 3. Calculate the silhouette coefficient of the sample (calculate O 1 ,O 2 The dissimilarity between classes is taken as an example):
[0212]
[0213]
[0214] 4. Calculate the overall silhouette coefficient of the cluster when K=2:
[0215]
[0216] Silhouette coefficient p...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention provides an automatic customer classification method based on K-Means clustering. The method comprises the steps: carrying out the initialization of platform customer data, forming a data set matrix A through the data of all company customers on a platform, enabling the data dimension to correspond to the column number in the matrix, enabling the customer number to correspond to the line number in the matrix, carrying out the normalization processing of the data set matrix A, and carrying out the classification of the customer data. Obtaining a normalized data set matrix B; a K-means clustering method is adopted to automatically classify clients, a contour coefficient method is adopted to determine a K value, and then an initial clustering center and K clustering centers are determined; all samples in the data set matrix B are distributed to the nearest clustering set according to the principle of minimum distance, and the mean value of all the samples in each cluster serves as a new clustering center; and repeating the above steps until the clustering center does not change any more, and obtaining K clusters, namely, a result of automatically classifying the clients. According to the method, objectivity of classification results can be guaranteed, and labor cost is saved.
Description
technical field [0001] The invention belongs to the technical field of data processing, and in particular relates to an automatic customer classification method based on K-Means clustering. Background technique [0002] In the field of education, Confucius put forward the educational concept of "teaching students according to their aptitude", and personalized learning is the ideal state pursued by education. For the service industry, personalized service is the ideal state it pursues. [0003] With the rapid development of the Internet, the network provides technical support for the personalized service of the Internet platform with its powerful interactive and distributed characteristics. There is a large amount of customer data in the database of the Internet e-commerce platform. Using these data to classify customers and provide more personalized services to different types of customers can bring more benefits to the platform. [0004] For the classification of existing...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More