

Speaking face video generation method and device based on convolutional neural network
A convolutional neural network and speaker technology, applied in the field of voice-driven speaking face video generation, can solve the problem of low authenticity of the speaking face video
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
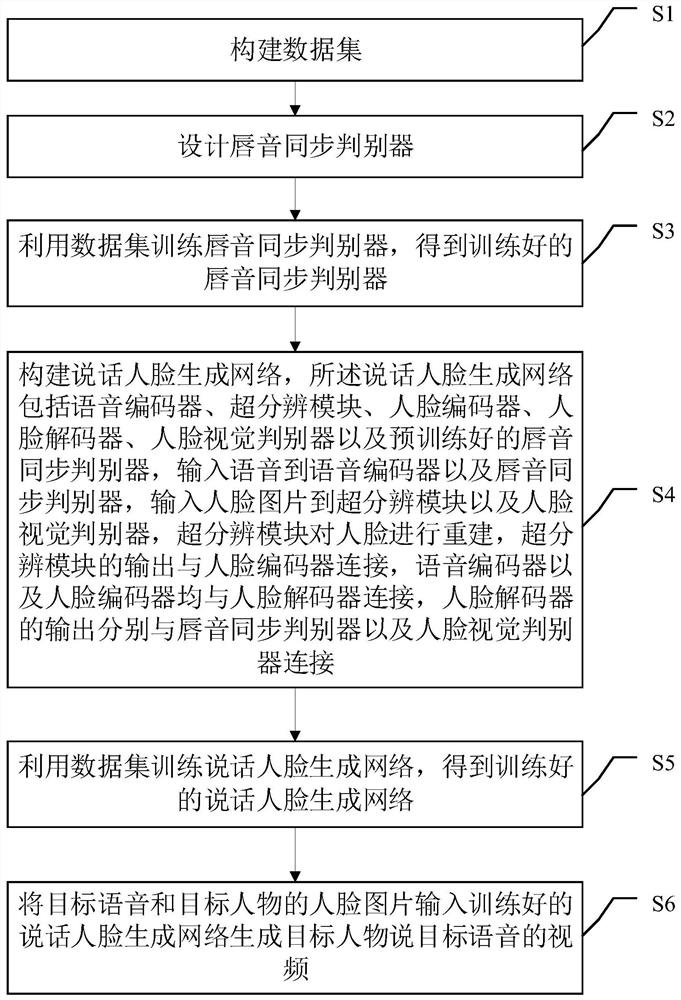
[0049] Such as figure 1 Shown, a kind of speech face video generation method based on convolutional neural network, described method comprises:
[0050] S1: Construct the data set; the specific process is: about 200 hours of raw video data are collected, and the frame rate of video transmission per second is 25fps. Use the MTCNN model to identify the key points of the face in the high-definition news anchor video, obtain the coordinates of 48 key points, and then calculate the similarity with the key points of the target person's face. The set similarity threshold is 0.8. When the calculation result is greater than 0.8 , the person in the video and the target person are considered to be the same person, record the position of the video frame with high face similarity in the original video, and use FFMPEG software to intercept the target anchor video from the original video according to the recorded position of the target person’s video frame part. Use the DLIB model to ident...
Embodiment 2
[0065] Corresponding to Embodiment 1 of the present invention, Embodiment 2 of the present invention also provides a device for generating a talking face video based on a convolutional neural network, the device comprising:
[0066] Dataset building blocks for building datasets;
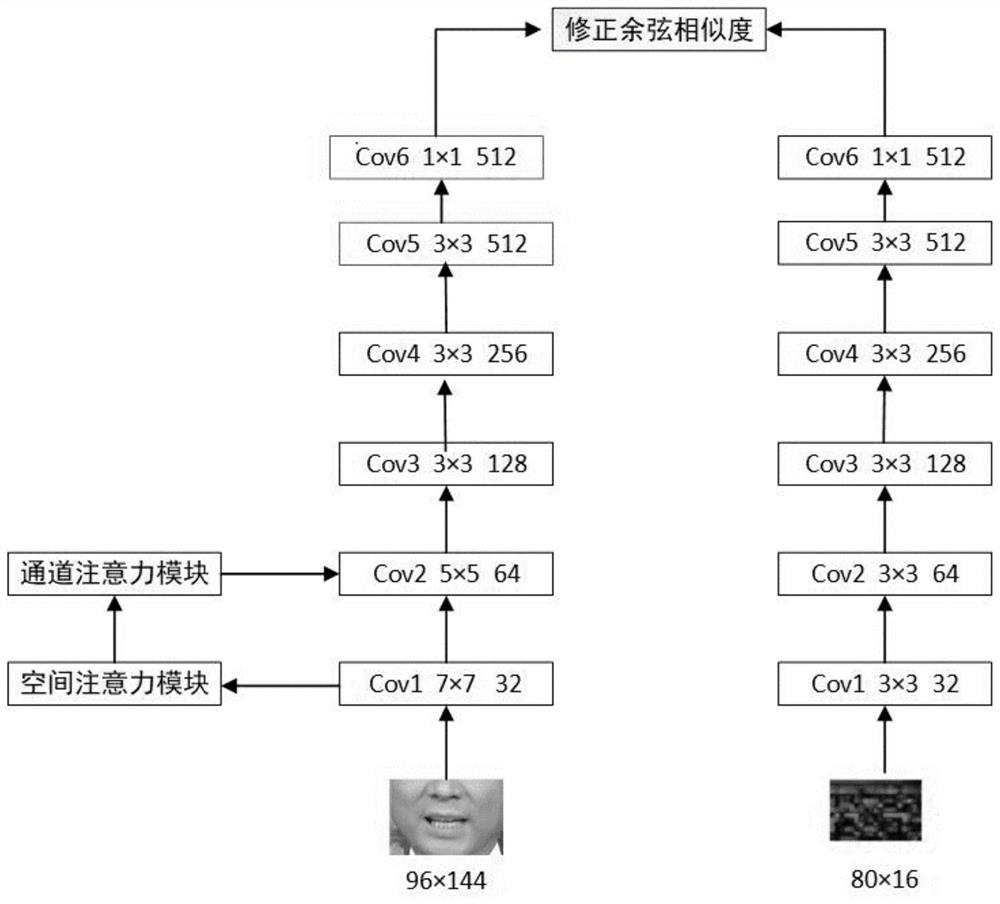
[0067] Lip sync module for designing lip sync discriminators;
[0068] The first training module is used to use the data set to train the lip sync discriminator to obtain the trained lip sync discriminator;
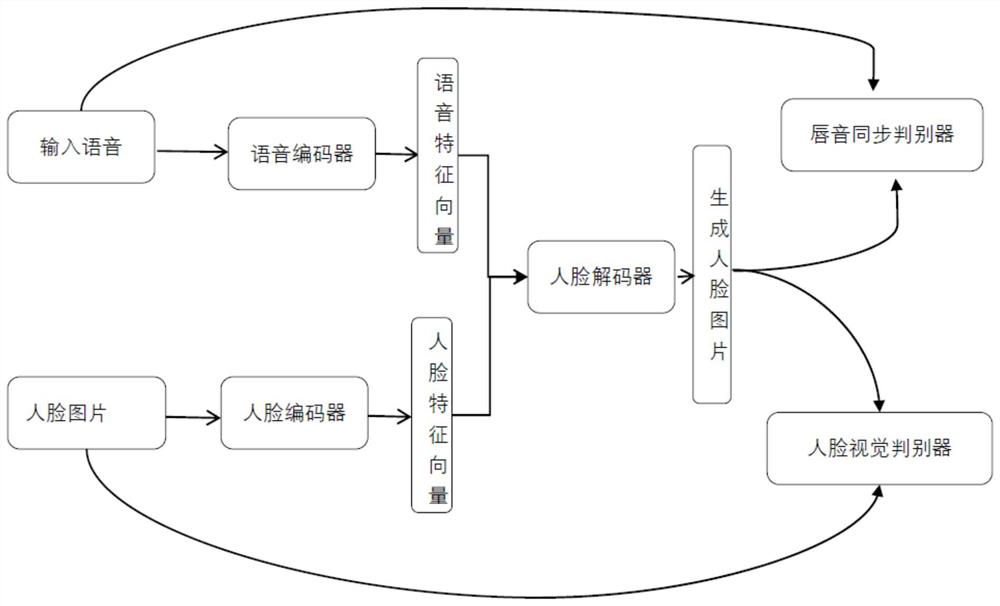
[0069] The speaking face generation network construction module is used to construct the speech face generation network, and the speech face generation network includes a voice encoder, a super-resolution module, a face encoder, a face decoder, a face visual discriminator, and a predictor Trained lip sync discriminator, input speech to speech encoder and lip sync discriminator, input face picture to super-resolution module and face visual discriminator, super-resolution module reconstructs face...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More