

A deep GP-based Dyna-Q method for dialogue policy learning
A policy learning and in-depth technology, applied in the field of machine learning, can solve problems such as instability, highly sensitive hyperparameter selection, performance constraints of dialogue learning, etc., and achieve easy evaluation and analysis effects
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

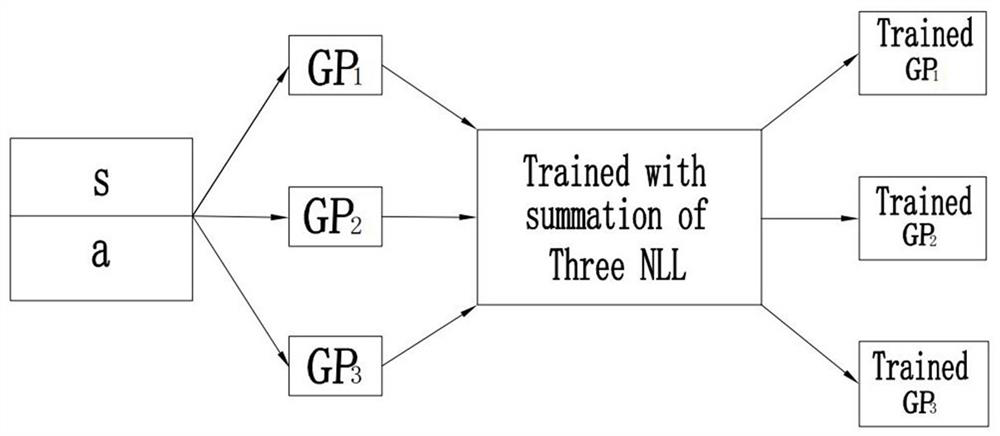
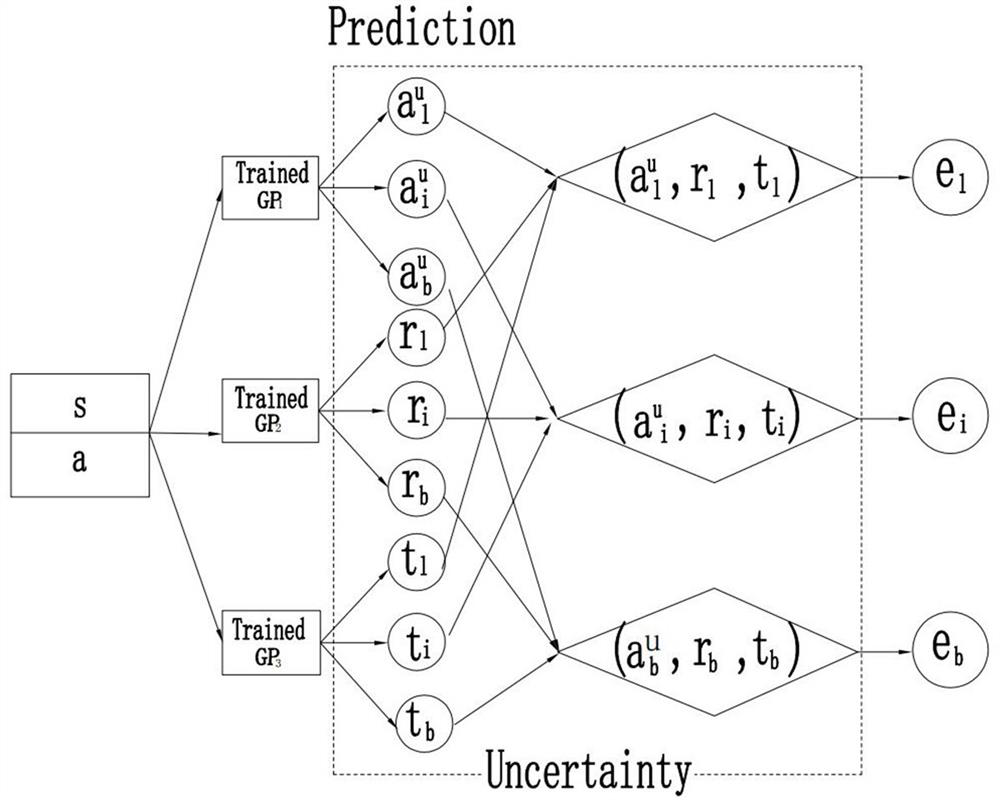
Examples
Embodiment Construction
[0065] The present invention will be described in further detail below in conjunction with the accompanying drawings and specific embodiments.
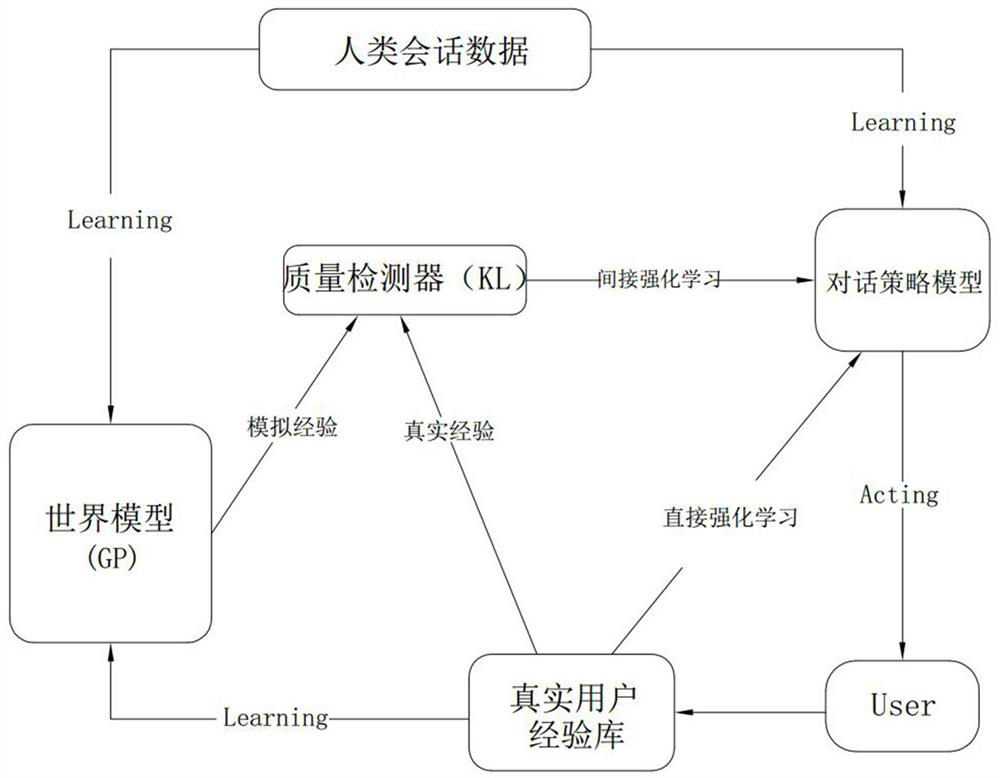
[0066] Such as figure 1 As shown, this scheme proposes a GP-based deep Dyna-Q method for dialogue policy learning. The basic method is consistent with the existing technology, such as using human conversation data to initialize the dialogue policy model and world model, and then Start dialogue policy learning. The dialogue policy learning of the dialogue policy model mainly includes two parts: direct reinforcement learning and indirect reinforcement learning (also called planning). Direct reinforcement learning, using Deep Q-Network (DQN) to improve the dialogue policy based on real experience, the dialogue policy model interacts with the user User, in each step, the dialogue policy model maximizes the value function Q according to the observed dialogue state s, Select the action a to perform. Then, the dialog policy model receives...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More