

Deep Q network reinforcement learning method and device for cognitive behavior model acceleration
A reinforcement learning and network technology, applied in the field of reinforcement learning, can solve the problems of lack of learning ability, weak generalization adaptability, and long training time of Agent, and achieve the effect of alleviating the influence of learning efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
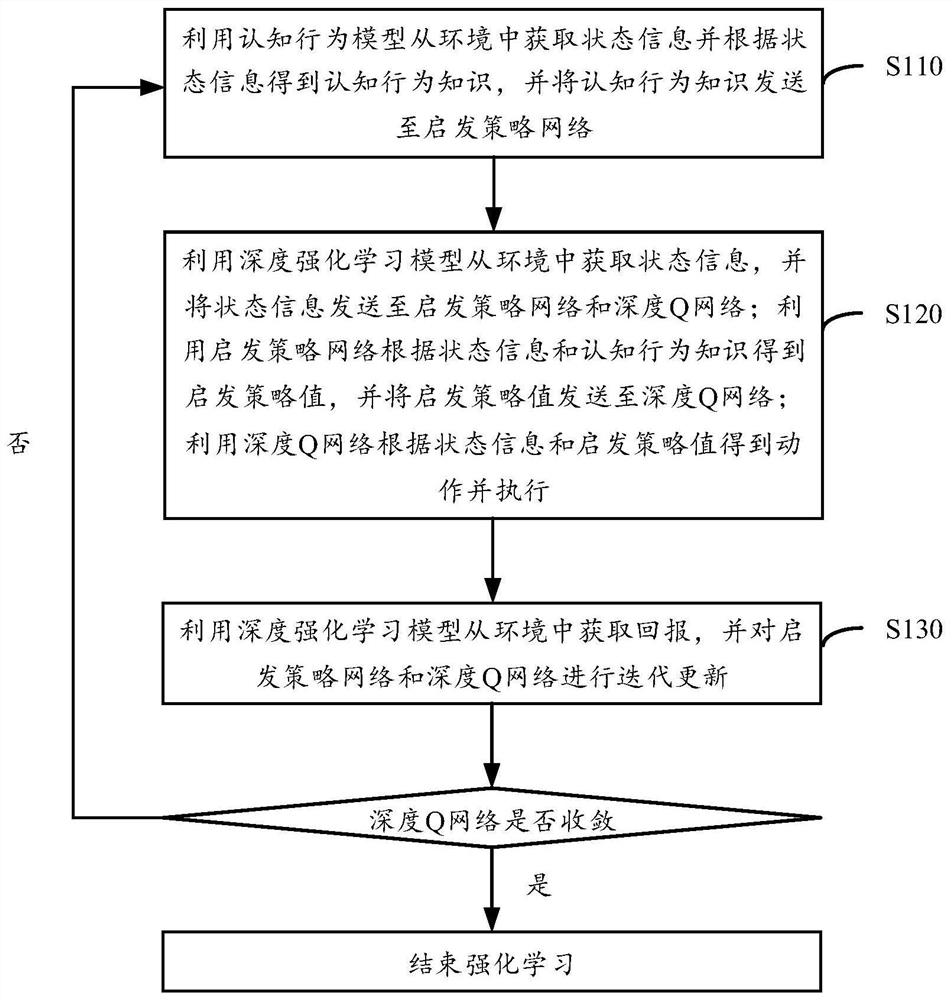
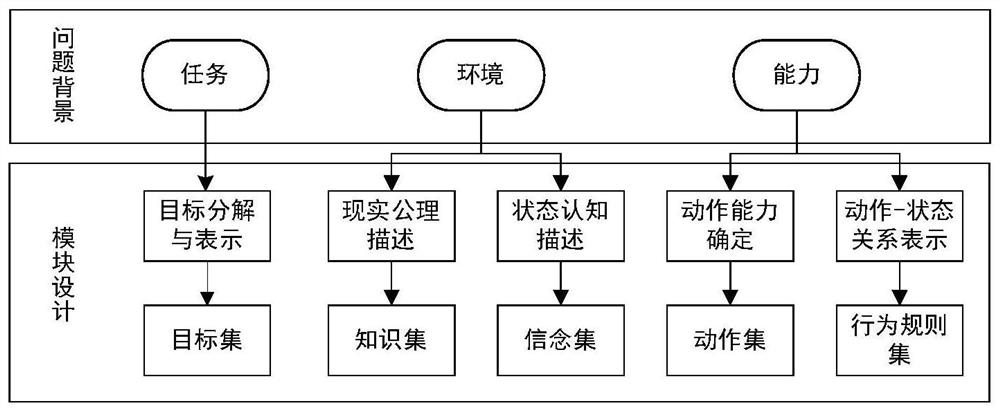
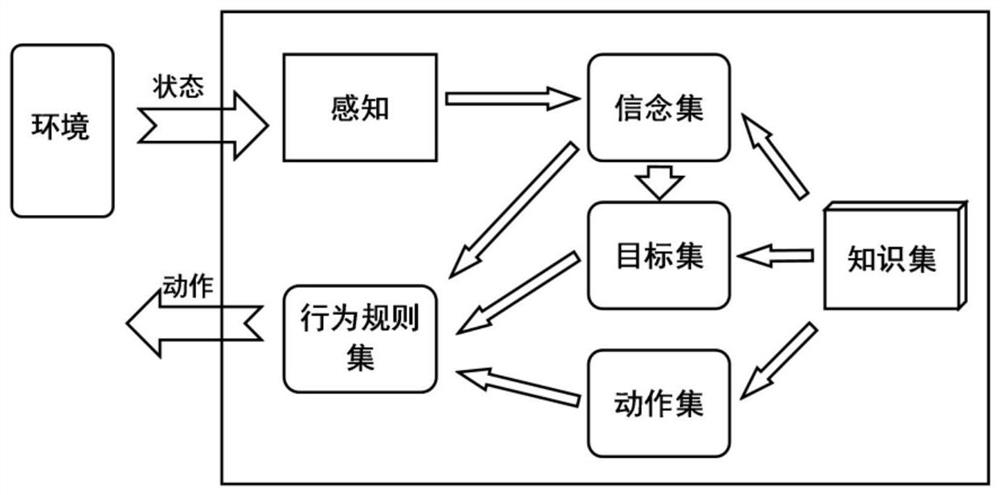
[0023] In order to make the purpose, technical solutions and advantages of the present disclosure clearer, the present disclosure will be further described in detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
[0024] It should be noted that, unless otherwise defined, the technical terms or scientific terms used in the embodiments of the present disclosure shall have ordinary meanings understood by those skilled in the art to which the present disclosure belongs. "First", "second" and similar words used in the embodiments of the present disclosure do not indicate any sequence, quantity or importance, but are only used to distinguish different components. "Comprising" or "comprising" and similar words mean that the elements or items appearing before the word include the elements or items listed after the word and their equivalents, without excluding other elements or items. Words such as "connected" or "connected" are not lim...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More