Information processing device, information processing system, information processing method, storage medium and program
An information processing method and information processing device technology, applied in special data processing applications, design optimization/simulation, dynamic trees, etc., can solve problems such as combinatorial explosions and difficulties
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] Hereinafter, embodiments of the present invention will be described with reference to the drawings. In addition, in the drawings, the same reference numerals are attached to the same constituent elements, and explanations thereof are appropriately omitted.
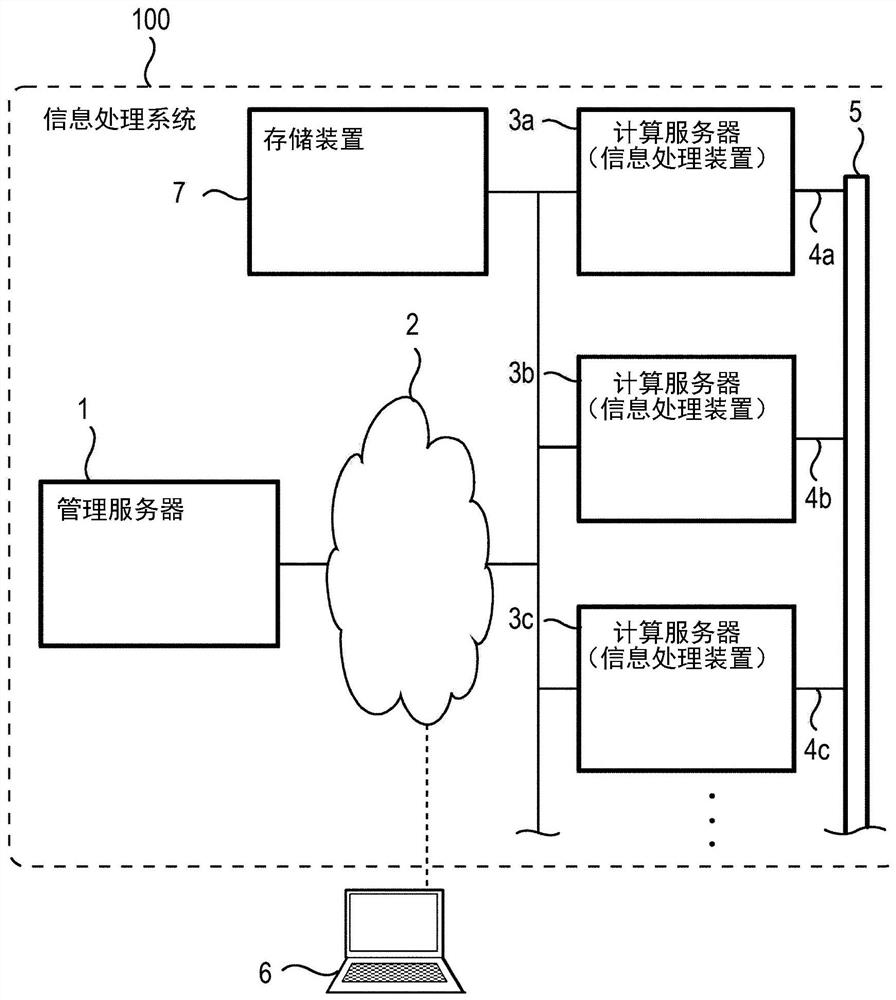
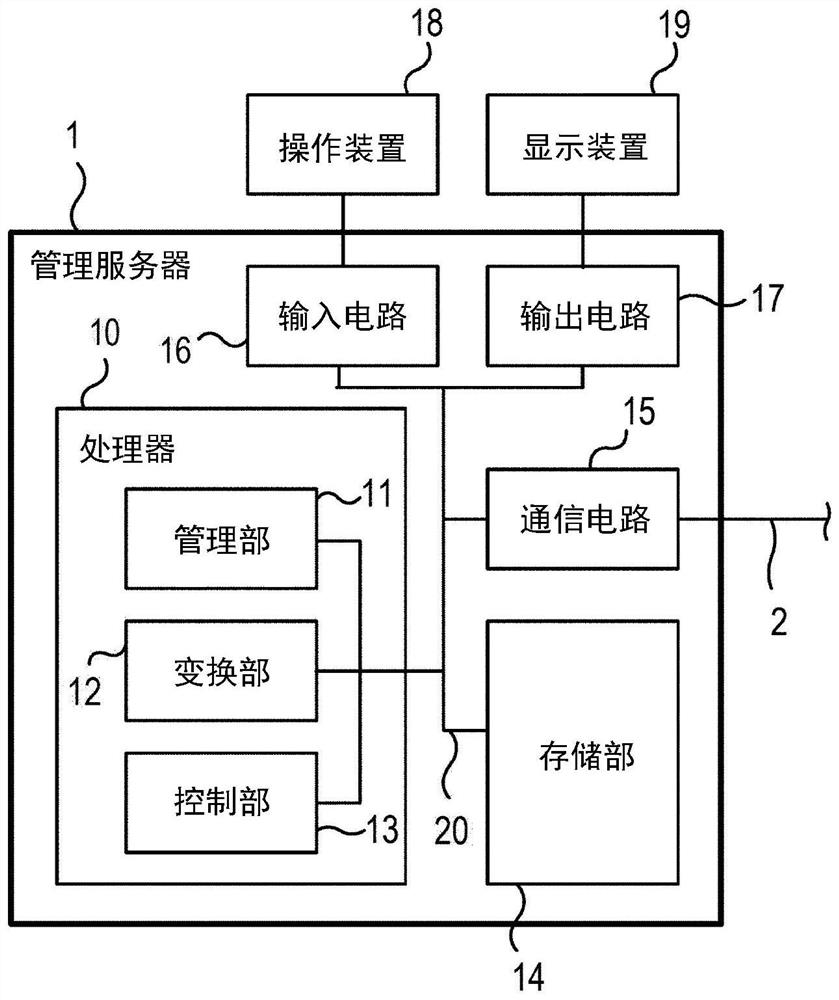
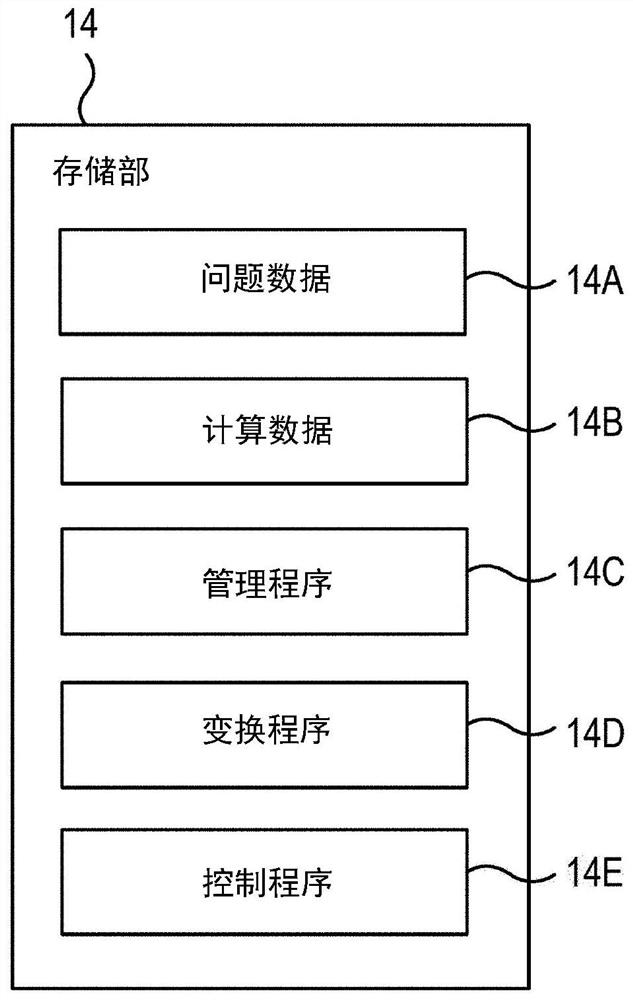
[0035] figure 1 It is a block diagram showing a configuration example of the information processing system 100 . figure 1 The information processing system 100 includes a management server 1 , a network 2 , computing servers (information processing devices) 3 a to 3 c , cables 4 a to 4 c , a switch 5 , and a storage device 7 . In addition, in figure 1 A client terminal 6 capable of communicating with the information processing system 100 is shown in . The management server 1 , computing servers 3 a to 3 c , client terminal 6 , and storage device 7 can perform data communication with each other via the network 2 . For example, the computing servers 3 a to 3 c can store data in the storage device 7 or read data fr...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More