

Multi-attention feature fusion speaker recognition method
A technology of speaker recognition and feature fusion, applied in character and pattern recognition, speech analysis, instruments, etc., can solve the problem of not being able to fully utilize multiple branches, and achieve the effect of suppressing noise and enhancing effective information
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

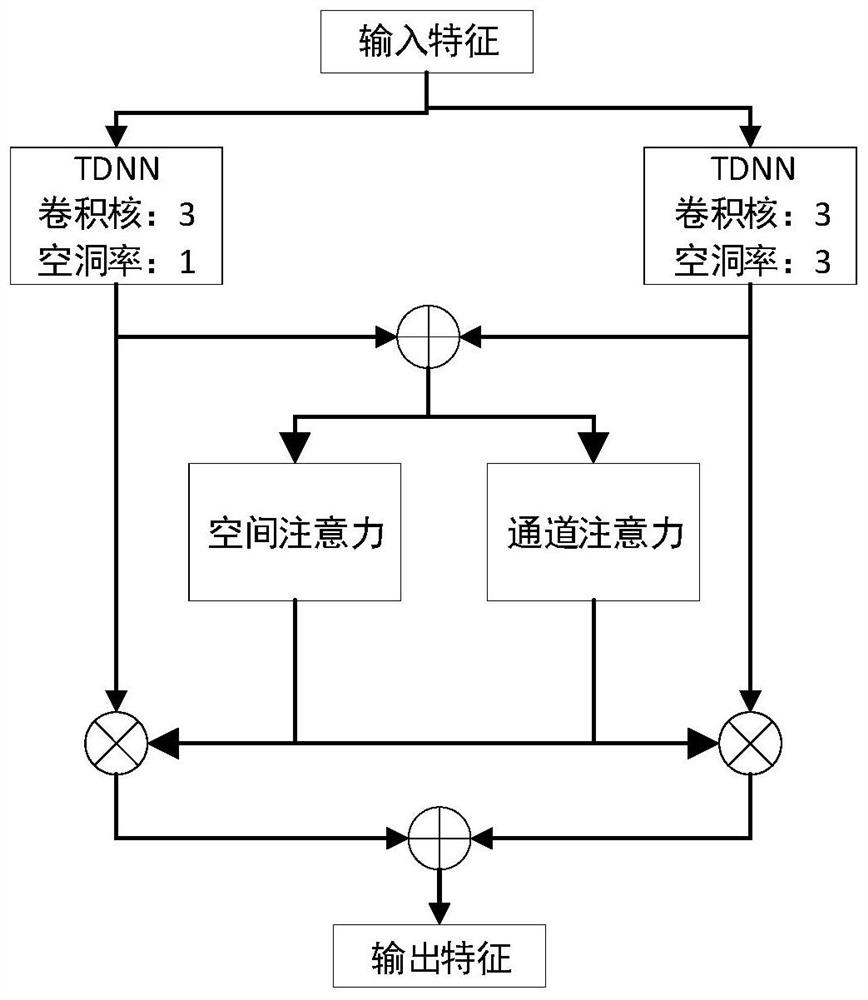
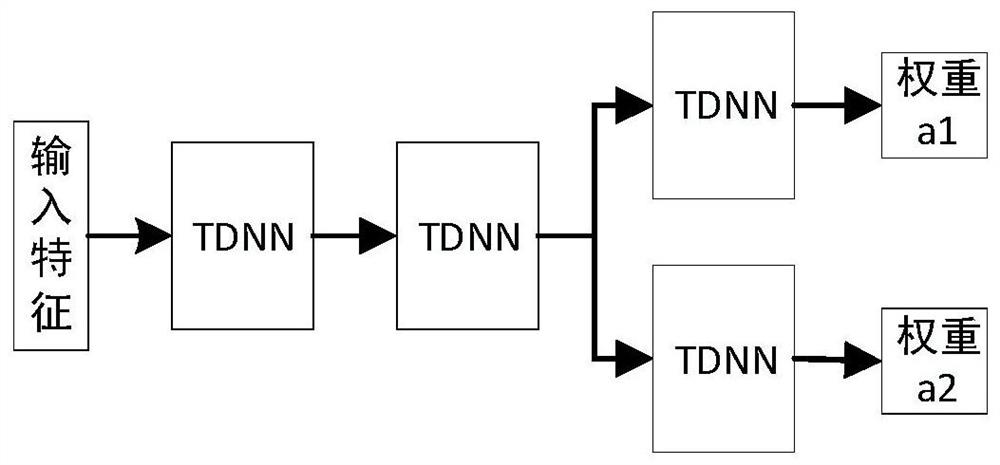
Examples
Embodiment Construction
[0023] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments, but the protection scope of the present invention is not limited thereto.
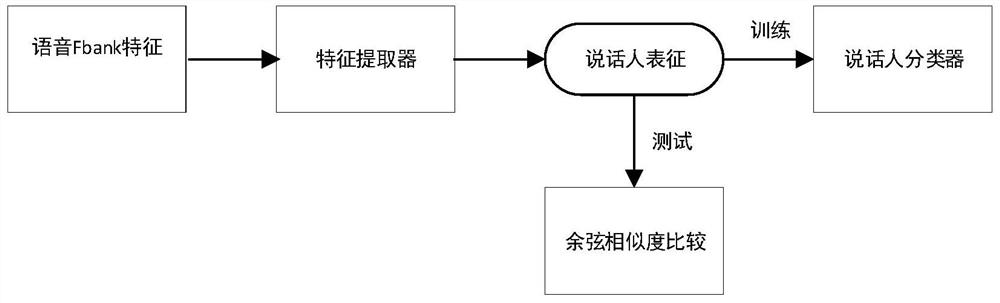
[0024] Such as figure 1 As shown, a kind of speaker recognition method of multi-attention feature fusion of the present invention, carries out short-time Fourier transform to speech signal and obtains spectrogram, and spectrogram obtains Fbank feature through Mel filter, and Fbank feature is used as deep speech The input features of the person representation model. The deep speaker representation model includes a feature extractor and a speaker classifier. The Fbank feature is extracted as a speaker embedding through the feature extractor. The speaker representation represents the speaker embedding in a speech signal. voiceprint information; in the training phase of the deep speaker representation model, the speaker classifier is used to map the speaker representation to ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More