

Method and system for automatically extracting scientific and technical literature data based on text mining
A literature data, automatic extraction technology, applied in electrical digital data processing, natural language data processing, instruments, etc., can solve the problems of slow data accumulation, large time overhead, etc., to improve the accumulation efficiency, strong operability and practicality sexual effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
no. 1 example
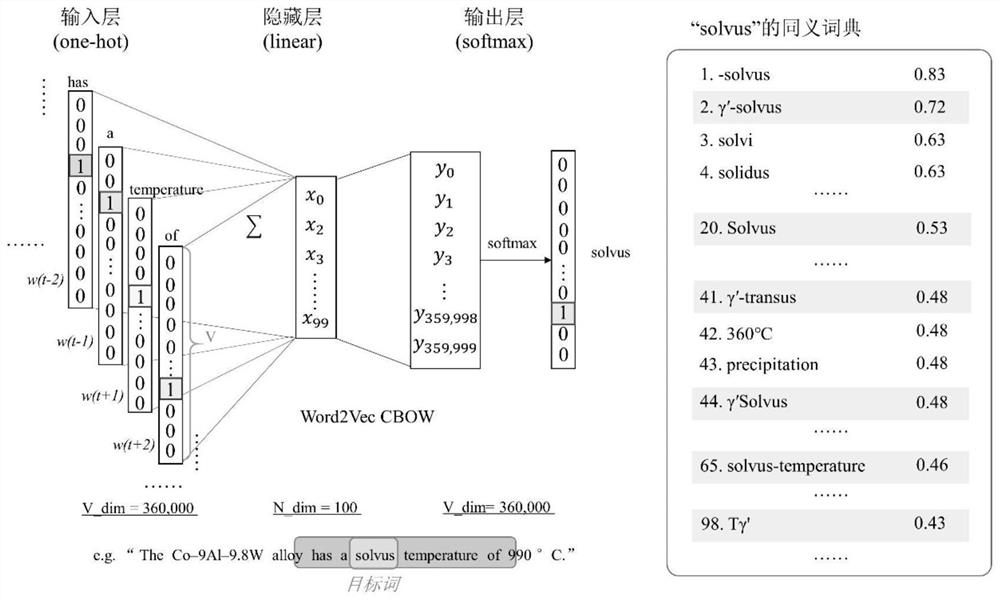
[0054] This embodiment provides a method for automatically extracting scientific and technological literature data based on text mining. Through the preprocessing, word segmentation, text classification, and named entity recognition of the literature corpus, the target entity in the scientific and technological literature corpus can be quickly identified; The semantic relationship between target entities forms an entity relationship, which can capture the events in the sentence of the literature corpus, and then automatically extract the key data information in the scientific and technological literature.
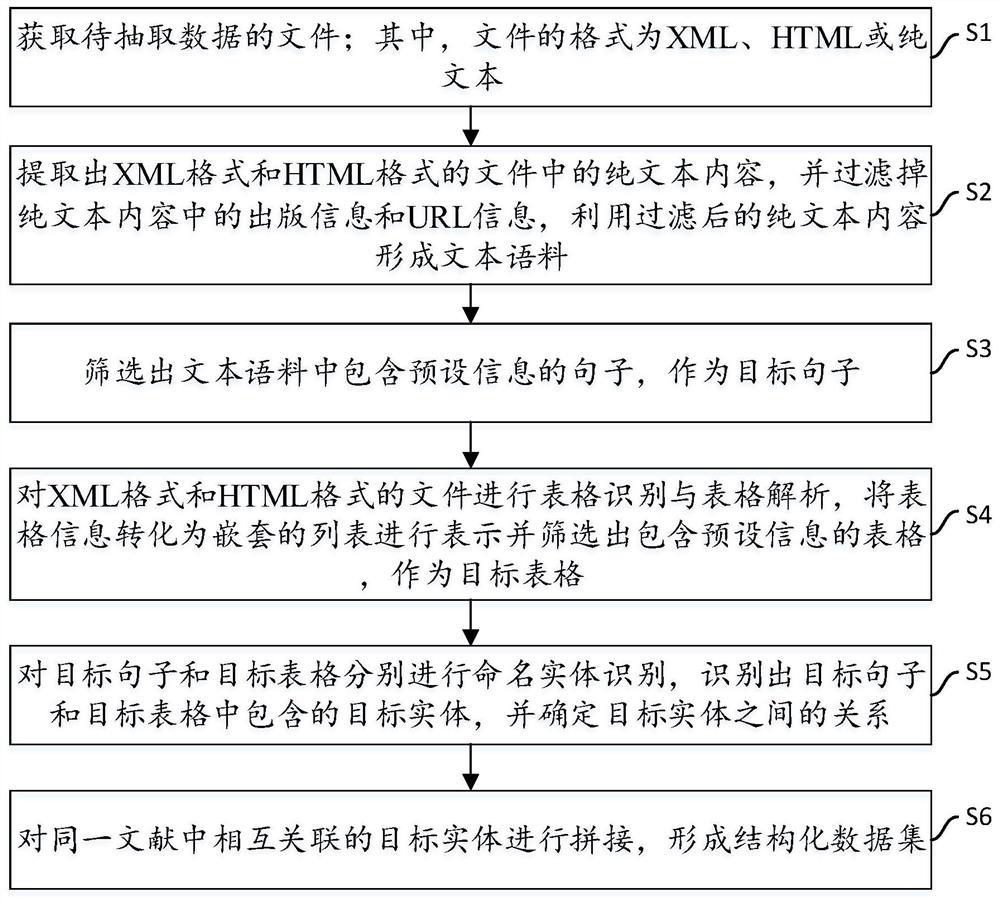
[0055] The method for automatically extracting scientific and technical literature data in this embodiment can be implemented by an electronic device, and the electronic device can be a terminal or a server. The execution flow of this method is as follows figure 1 shown, including the following steps:
[0056] S1, obtaining the file of the data to be extracted; wherein, th...
no. 2 example
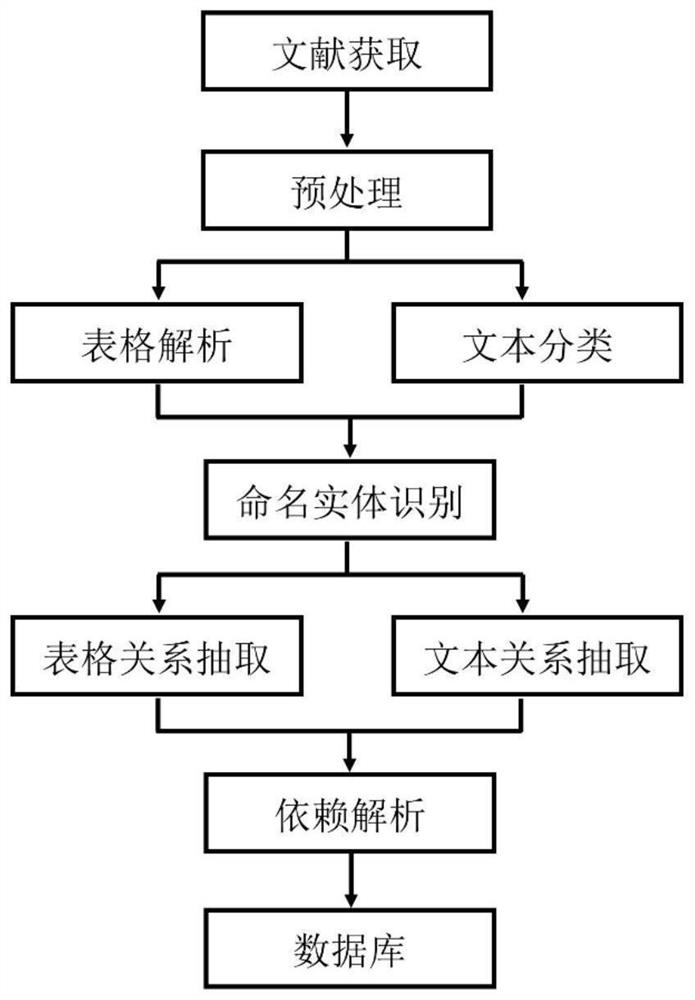
[0094] This embodiment provides a method for automatically extracting scientific and technological literature data based on text mining. Through the preprocessing, word segmentation, text classification, and named entity recognition of the literature corpus, the target entity in the scientific and technological literature corpus can be quickly identified; The semantic relationship between target entities forms an entity relationship, which can capture the events in the sentence of the literature corpus, and then automatically extract the key data information in the scientific and technological literature.
[0095]Next, take the automatic extraction of superalloy scientific and technological literature data in the field of material science as an example to illustrate the process of the automatic extraction method for scientific and technological literature data in this embodiment, as shown in figure 2 shown, which includes:
[0096] 1) Document acquisition: automatically deter...
no. 3 example
[0117] This embodiment provides a system for automatically extracting scientific and technological literature data based on text mining, including:
[0118] A document acquisition module, configured to acquire a file of data to be extracted; wherein, the format of the file is XML, HTML or plain text;
[0119] The text preprocessing module is used to extract the plain text content in the file of XML format and HTML format, and filters out the publication information and URL information in the plain text content, and utilizes the plain text content after filtering to form the text corpus;
[0120] The target text screening module is used to filter out sentences containing preset information in the text corpus as target sentences; perform table recognition and table analysis on files in XML format and HTML format, convert table information into nested lists for representation and Filter out the form containing preset information as the target form;
[0121] An entity recognition...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More